[CS231n] Lec1. Introduction to Convolutional Neural Networks for Visual Recognition

이 블로그글은 2017년 스탠포드 대학교 강의인 CS231n 을 시청하고 정리한 글임을 밝힙니다.
Introduction to Convolutional Neural Networks for Visual Recognition
Computer vision
CS231n
- 컴퓨터 비전/딥러닝계의 교과서로 불리는 2017년스탠포드 대학교에서 열린 강의이다.
- 컴퓨터 비전과 딥러닝에 대한 전반적인 내용을 담고 있다.
컴퓨터 비전의 중요성
- 엄청나게 많은 시각 데이터가 쏟아져 나오고 있다.
- 전 세계의 무수한 센서와 스마트폰에 내장된 카메라
- 인터넷 트래픽에 80%의 지분이 비디오 데이터이다.
→ 하지만 이런 시각 데이터는 해석하기 상당히 까다롭다.
컴퓨터 비전의 주변 분야
- 물리학(광학, 이미지 구성, 이미지의 물리학적 형성 등), 컴퓨터 과학, 수학, 공학(컴퓨터 비전 알고리즘을 구현할 컴퓨터 시스템 구축) 등
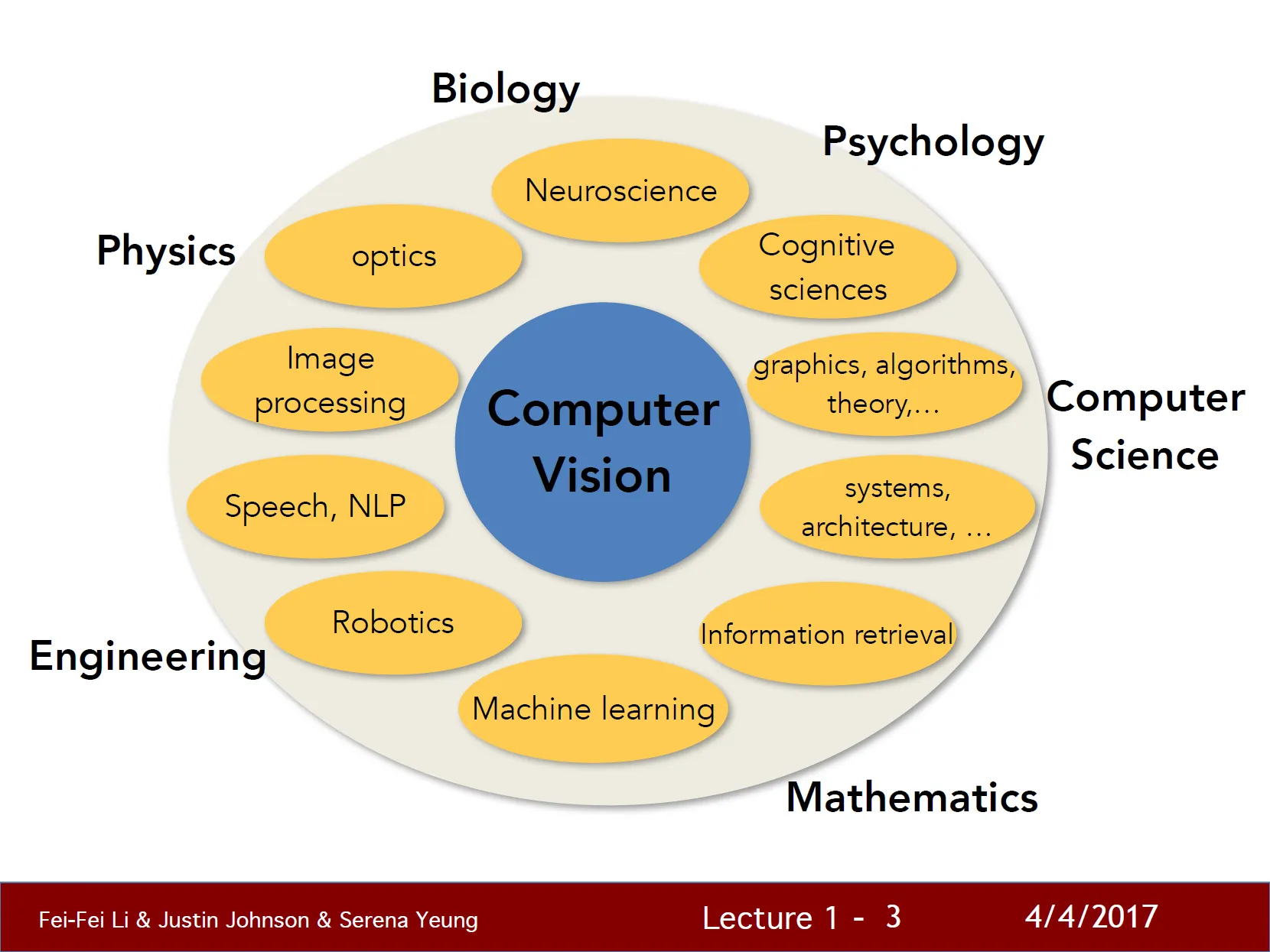
컴퓨터 비전의 역사
Evolution’s Big Bang
- 5억 4천만년전, 종의 수가 급등하였다.
- 이러한 급등의 원인을 앤드류 파커(Andew Parker)의 연구에서 생물들의 눈(eyes)이 생겨났고, 생물들이 볼 수 있게되면서라고 주장했다.
- 현재 눈은 가장 큰 감각 체계로 발전하였다.
→ 생물학적 비전의 시작이자 비전의 태동이됨
Camera Obscura

- 핀홀 카메라 이론에 기반으로한 카메라
- 빛을 모아주는 구멍을 통과하여 평평한 면에 정보를 모으고 이미지를 투영
- 카메라 기술이 발전하면서 오늘날 카메라는 어디애나 존재함
→ 공학적 비전
Hubel & Wiesel
- “포유류의 시각적 처리 매커니즘은 무엇인가”에 대한 질문에 생물학자들이 비전 메커니즘에 대해 연구
- 일차시각 피질이 전극을 통해 어떤 자극에 반응하는지 실험
- 시각처리는 단순한구조에서 실제 예상을 인지할때까지 점점 복잡해진다는 것을 알아냄
초창기 컴퓨터 비전 연구
- Block world - Larry Robers, 1963
- 컴퓨터 비전 최초의 박사 학위 논문
- 우리 눈에 보이는 세상을 인식하고 그 모양을 재구성
- The summer vision project - MIT, 1966
- 대부분의 시각체계를 구현하자
- 50년이 지난 지금 “컴퓨터 비전”이라는 분야는 현재 전 세계 수천 명의 연구자들이 비전의 가장 근본적인 문제들을 연구하고 있음
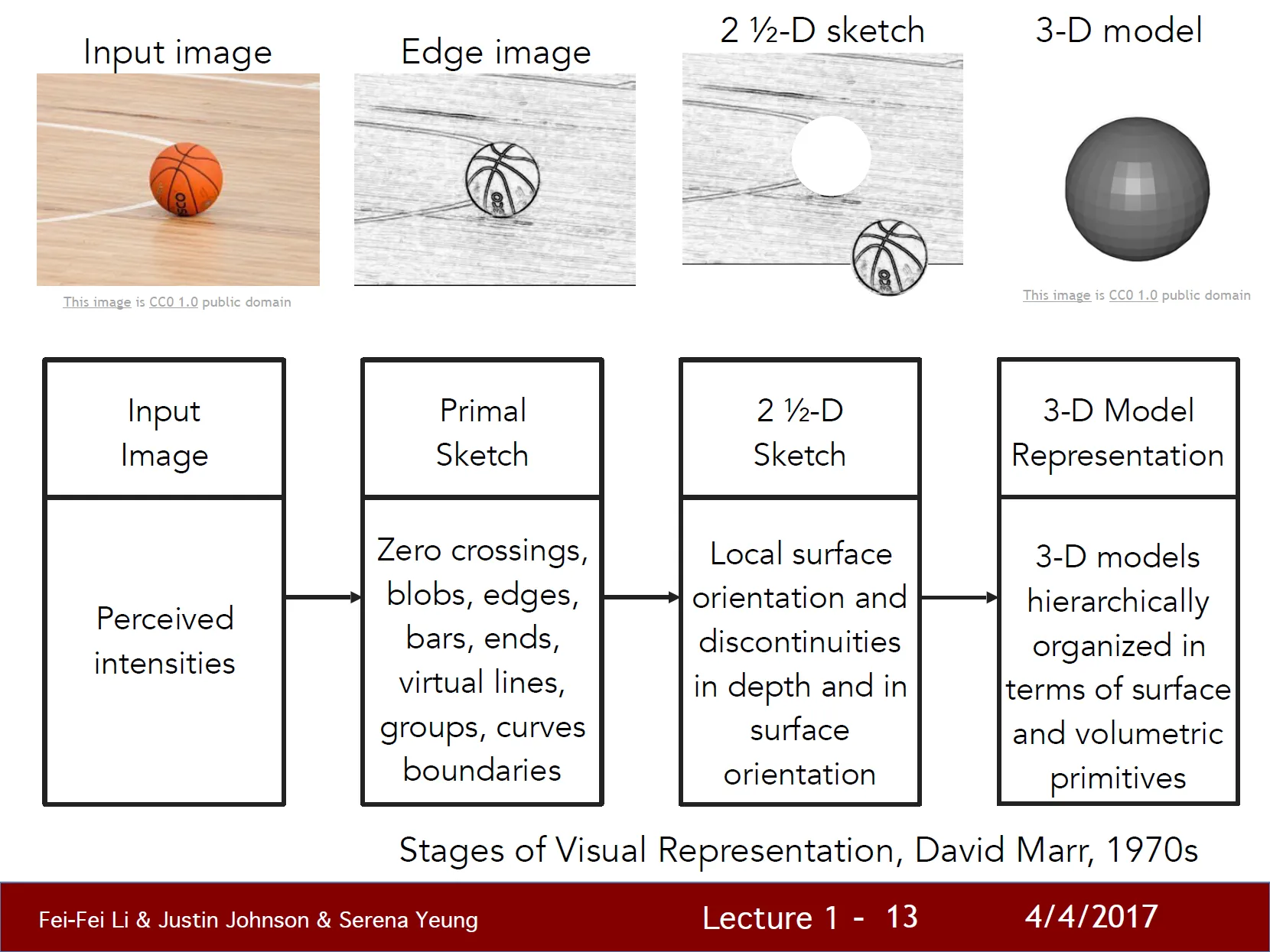
- VISION - David Marr, 1970s
- “컴퓨터비전이란 무엇인가?”
- “컴퓨터가 비전을 인식하게 하기 위해 어떤 방향으로 알고리즘을 개발해야 하는가? “
- 이미지를 최종적인 full 3D 표현으로 만들려면 몇단계의 과정을 거쳐야만 한다고 주장함
- Object recognition - Brooks & Binford, 1979, Fischler and Elschlager, 1973
- 각각, Generalized Cylinder, Pictorial Structure
- “어떻게 해야 단순한 블록세계를 뛰어넘어서 실제세계를 인식하고 표현할 수 있을까?”
- 모든 객체를 단순한 모양과 기하학적 구성을 이용해 표현할 수 있다.
- Feature-based geometric approach - David Lowe, 1987
- “어떻게 하면 단순 구조로 실제세계를 재구성하고 인식할 수 있을까?”
- 선과 경계 직선을 조합하여 구성함
→ 60/70/80년대에는 “컴퓨터 비전으로 어떤 일을 할 수 있을까?”에 대한 고민, 매우 어려운 문제였음
객체 분할 기반 연구
→ “객체 인식이 너무 어렵다면 객체 분할(segmentation)이 우선이 아니었을까?”
- Normalized Cut - Shi & Malik, 1997
- 이미지의 각 픽셀에 의미있는 방향으로 군집화하는 방법
- 배경/사람 픽셀단위로 구분
- 그래프 이론을 도입
- Face Detection - Viloa & Jones, 2001
- 유난히 발전 속도가 빨랐던 분야
- 1999/2000년대에는 기계학습(특히 통계적 기계학습)이 탄력을받음
- SVM, Boosting, Graphical models, 초기 Neural Network 등
- AdaBoost를 이용해 실시간 얼굴인식에 성공함
- 2006년, 실시간 얼굴인식을 지원하는 최초의 디지털 카메라 등장
- 기초과학 연구의 성과를 실제 응용 제품에 전달한 사례
특징 기반 객체인식 연구
→ 이후 “어떻게 객체를 잘 인식할 것인가?”, “특징기반 객체 인식 알고리즘”
- SIFT & Object Recognition, David Lowe, 1999
-
전체 객체를 서로 매칭시키기는 매우 어려움
-
객체의 특징 중 일부는 다양한 변화에 조금 더 강인하고 불변함
-
객체인식은 객체에서 중요한 특징을 발견하고 그 특징들은 다른 객체에 매칭시키는 과제로 변경

-
- Spatial Pyramid Matching, Lazebnik - Schmid & Ponce, 2006
- 장면 전체 인식 단계에 이름
- 특징들을 잘 뽑아내면 그 특징들이 일종의 단서 제공 가능
- 이미지 내 여러부분과 여러 해상도에서 추출한 특징을 하나의 특징 기술자로 표현하고 SVM 알고리즘을 적용
- Human Recognition - Dalal & Triggs, 2005, Felzenswalb, McAllester, Ramanan, 2009
- 각각, Histogram of Gradients (HoG), Deformable, Part Model
- “어떻게 해야 사람의 몸을 현실적으로 모델링할까?”
- 여러 특징들을 잘 조합해보자는 시도
Benchmark 데이터셋 수집
→ 사진의 품질이 좋아지고 인터넷, 디지털 카메라의 발전으로 좋은 실험 데이터가 만들어짐
→ 2000년대 초 컴퓨터 비전이 앞으로 풀어야 할 문제가 무엇인지의 정의를 어느 정도 내림 - 객체 인식
- PASCAL Visual Obect Challenge
- 기차, 비행기 사람, 소, 병, 고양이 등 20개의 클래스를 가지는 클래스당 수천 수만 개 이미지
- 다양한 알고리즘을 통해 테스트
- 객체 인식 성능이 진보 했음을 알게 됨
- IMAGENET
- “이 세상의 모든 객체들을 인식할 준비가 되었는가?”
- 당시에는 거의 대부분이 머신러닝 알고리즘을 사용했고 트레이닝 과정에서 Overfitting됨
- 시각 데이터가 너무 복잡(고차원 데이터)했고 모델을 학습하기 위해 많은 파라미터가 필요했지만, 학습 데이터가 매우 부족했음
- 두 가지 동기
- 이 세상의 모든 것을 인식하자
- 기계학습의 Overfiting 문제를 극복하자
- 결과 3년동안, 대략 15만장에 이미지와 22만가지의 클래스 카테고리를 보유하게 됨
→ 객체 인식은 새로운 국면에 접어듦
CNN 출현
-
ILSVRC
-
ImageNet은 2009년 국제 규모의 대회를 주체함
-
1000개의 객체에서 140만 개의 test set 이미지를 엄선
-
이미지 분류 문제를 푸는 알고리즘 테스트
-
평가 기준 : 5순위 정답
-
결과

-
2015년에 사람의 인식 수준을 넘어섰다.
-
가장 중요한 점은 2012년의 비약적 성능 증가
→ Cnvolution Neural Network 모델의 도입
-
-
→ CNN의 도입으로 컴퓨터 비전 분야의 진보를 이뤄냄
컴퓨터 비전 응용 분야
- Image classification : 알고리즘이 이미지 한 장을 보고 몇개의 고정된 카테고리 안에서 정답을 하나를 찾는 것
- 다양한 응용이 가능
- Object detection
- Action clssification
- Image captioning
- 다양한 응용이 가능
→ 다양한 industry, academy 문제에 적용이 가능
Convnet 역사

- 2010년 Lin et al의 알고리즘
- 계층적
- 여러 단계가 존재
- 특징을 추출
- 지역 불변 특징 계산
- pooling과 여러 단계 거침
- 최종적인 특징 기술자를 Linear SVM 알고리즘에 적용
- 2012년 Jeff Hinton의 AlexNet
- 7-Layer CNN을 만듦
- 획기적인 발전
- 2014년 Google의 GoogleNet
- 2015년 MSRA의 Residual Network
- Layer 수는 152개에 육박
→ 이러한 추세로 CNN은 매년 더 깊어져 감
CNN의 시작
→ CNN은 사실 오래전부터 존재 했음
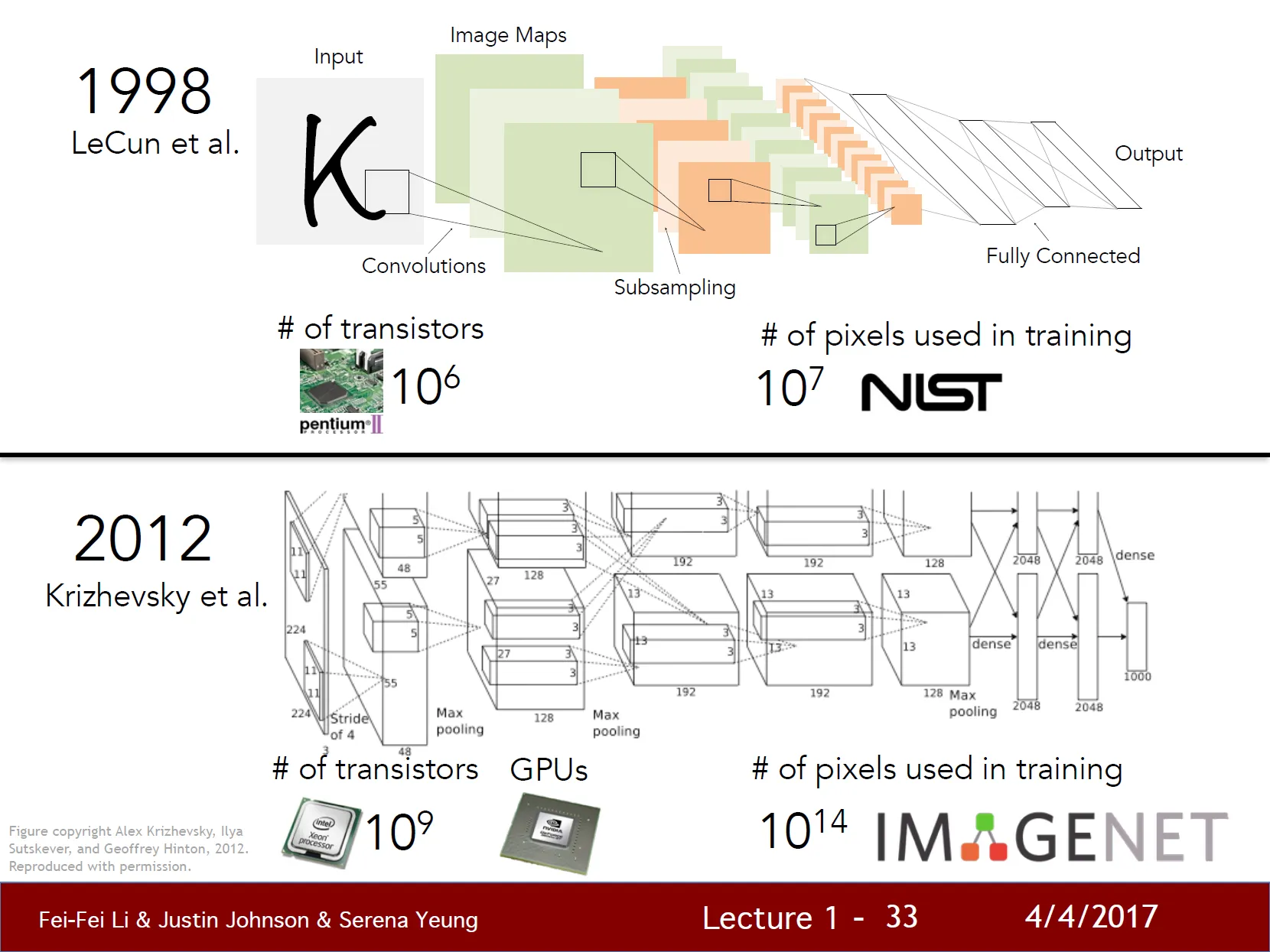
- 1998년 Jan LeCun, Bell Laps의 공동과제
- 숫자 인식을 위해 CNN 구축
- 자필 수표 자동 판독과 우편 주소 자동인식에 CNN을 적용
- raw pixel을 입력 받아 여러 CNN Layer를 거치고 Subsampling, 최종적으로 fully connected Layer를 거침
- 2012년의 AlexNet과 매우 유사함
CNN이 발전한 이유
- 계산 능력의 증가
- 무어의 법칙
- GPU의 강력한 병렬처리
- 데이터셋 확보
- 아주 많은 레이블이 매겨진 이미지가 필요 했음
- 오늘날에는 PASCAL이나 ImageNet 같은 규모가 크고 잘 분류된 레이블들을 가진 데이터셋이 많음
- 큰 데이터셋들을 잘 활용하여 Higher Capacity Model을 만들 수 있음
💡 무어의 법칙
- 반도체 집적 회로의 트랜지스터 수가 약 18개월마다 두 배로 증가한다는 관찰
- 컴퓨터 성능이 급격히 향상되는 현상을 설명하는 법칙
결론
- 컴퓨터 비전의 목표는 “사람 처럼 볼 수 있는” 기계를 만드는 것이다.
- 아직 컴퓨터 비전 알고리즘이 인간들의 깊은 이해를 이해하는데는 아직 갈 길이 멀다.
- 컴퓨터 비전은 의학 진단, 자율 주행, 로보틱스 등 어디든지 활용이 가능한다.
→ 인간의 지능을 이해하기 위한 핵심 아이디어들을 집대성하는 일종의 실마리가 될지도 모른다.
