
이 블로그글은 2019년 조재영(Kevin Jo), 김승수(SeungSu Kim)님의 딥러닝 홀로서기 세미나를 수강하고 작성한 글임을 밝힙니다.
💡 도움이 되셨다면 ♡와 팔로우 부탁드려요! 미리 감사합니다.
Assignment #1
Goal
- 다양한 MLP를 만들어보자.
- learning rate를 조절해보자
질문 / 해결책
- MLP hidden layer 수가 바뀔때마다 매번 코드를 직접 쳐야 함 → nn.ModuleList, Argparse, 함수화로 해결
- 실험 돌리는 것이 오래 걸림 → GPU로 실행
- 같은 코드인데도 실행마다 결과가 다름 (random으로 파라미터를 초기화하므로) → Seed 고정
- Train Loss는 줄어는데 Validation Loss는 줄어들지 않음 → Overffiting을 해결해야 함
- 변수들은 어떤 식으로 바꾸고 Train/Vaidation/Test를 어떻게 사용해야 할지모르겠음 → Hyperparameter Tuning 관련
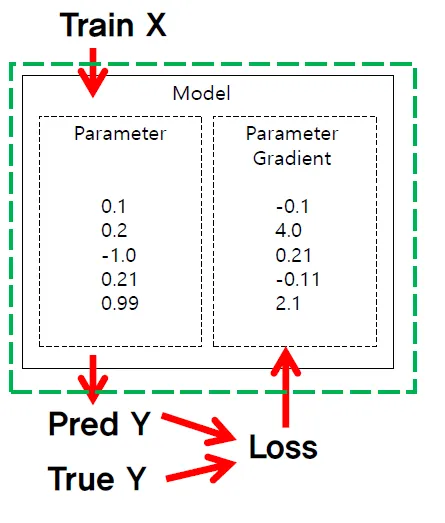
💡 Loss.backward()를 통해 Back-propagation 계산한 결과가 어떻게 Optimizer.step()을 호출하면 활용되는가?
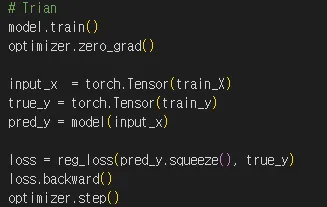
전체 학습코드 (예시)
학습 과정
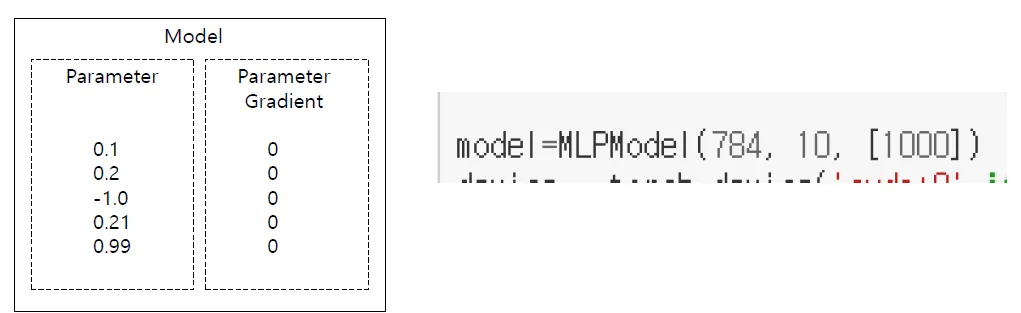
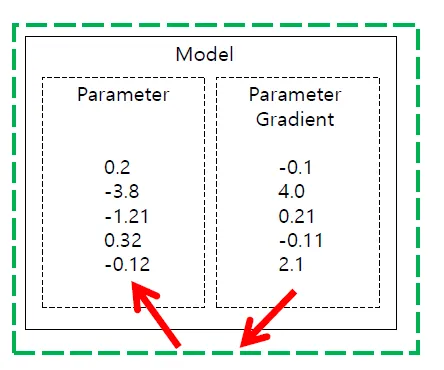
MLPModel 생성시 Parameter가 random으로 초기화됨
- torch.tensor의 경우 Paramet 외에 각 Parameter의 Gradient가 초기화되어 있음
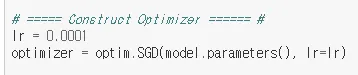
- optimizer 생성시 model.parameters()를 넘겨주면 모델에 있는 Parameter를 담당하게됨 (Optimizer 생성에서 넣어주는 model.parameters())
model에 input_X(입력)를 넣어 pred_y(모델의 예측값)를 예측함
pred_y = model(input_X)reg_loss(regression의 경우)를 사용해서 pred_y(예측값)과 true_y(실제값)을 비교해서 loss 계산
loss = reg_loss(pred_y.squeeze(), true_y)loss.backward()를 해서 각 parameter에 대한 loss에 편미분이 진행되어 loss를 줄이기 위한 gradient들이 계산됨
loss.backward()
optimizer.step()을 하면 계산된 gradient를 바탕으로 다시 파라미터들을 수정함
optimizer.step()
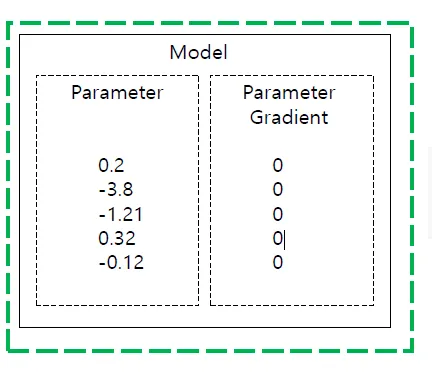
optimizer.zero_grad()를 통해 paramet gradient를 0으로 초기화
- 다음 iteration에 gradient 충돌이 안되게 함
optimizer.zero_grad()
nn.ModuleList()
- 여러
nn.Module들을 리스트처럼 담아 관리할 수 있게 해주는 클래스이다.
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self, in_features, out_features, hid_dim):
super(MyModel, self).__init__()
self.linear1 = nn.Linear(in_features, hid_dim[0])
self.hidden = nn.ModuleList()
for i in range(len(hid_dim) - 1):
self.hidden.append(nn.Linear(hid_dim[i], hid_dim[i + 1]))
self.linear2 = nn.Linear(hid_dim[-1], out_features)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.linear1(x))
for layer in self.hidden:
x = self.relu(layer(x))
x = self.linear2(x)
return x
model = MyModel(in_features=10, out_features=2, hid_dim=[64, 32, 16])사용 이유
- python list 대신에 nn.ModuleList를 사용하는 이유가 뭘까?
-
Python의 일반적인
list에nn.Module을 추가하면, PyTorch의Optimizer는 해당 모듈들의 파라미터를 추적하지 않는다.→
nn.ModuleList에nn.Module을 추가하면, PyTorch는 그 모듈들을nn.ModuleList의 일부로 인식하여 파라미터들을 자동으로 추적하고, 학습 과정에서 이를 업데이트한다.
-
💡 layer를 동적으로 쌓을때 nn.ModuleList를 사용하자
💡 도움이 되셨다면 ♡와 팔로우 부탁드려요!
