
이 블로그글은 2019년 조재영(Kevin Jo), 김승수(SeungSu Kim)님의 딥러닝 홀로서기 세미나를 수강하고 작성한 글임을 밝힙니다.
MLP
Review
- Linear transformation을 하고 non-linear function을 취한 것이 hidden layer가 됨
- hidden layer가 한 개 이상이고 적절한 비선형 활성화 함수가 적용된 신경망은 Universal approximation theorem에 의해서 어떠한 function도 근사할 수 있다.
실습
MLPModel class 생성
1 hidden layer MLP
class MLPModel(nn.Moudel):
def __init__(self, in_dim, out_dim, hid_dim):
super(MLPModel, self).__init__()
self.linear1 = nn.Linear(in_dim, hid_dim)
self.linear2 = nn.Linear(hid_dim, out_dim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
return x
m = MLPModel(2, 1, 200)💡 Sigmoid, Hyperbolic Tangent activation function을 잘 사용하지 않는 이유
- Vanishing gradient 문제: 출력이 0 또는 1에 가까워지면 기울기가 0에 수렴해 학습이 어려움
- 계산 복잡성: 미분이 복잡하여 ReLU 등 간단한 함수에 비해 효율성이 떨어짐
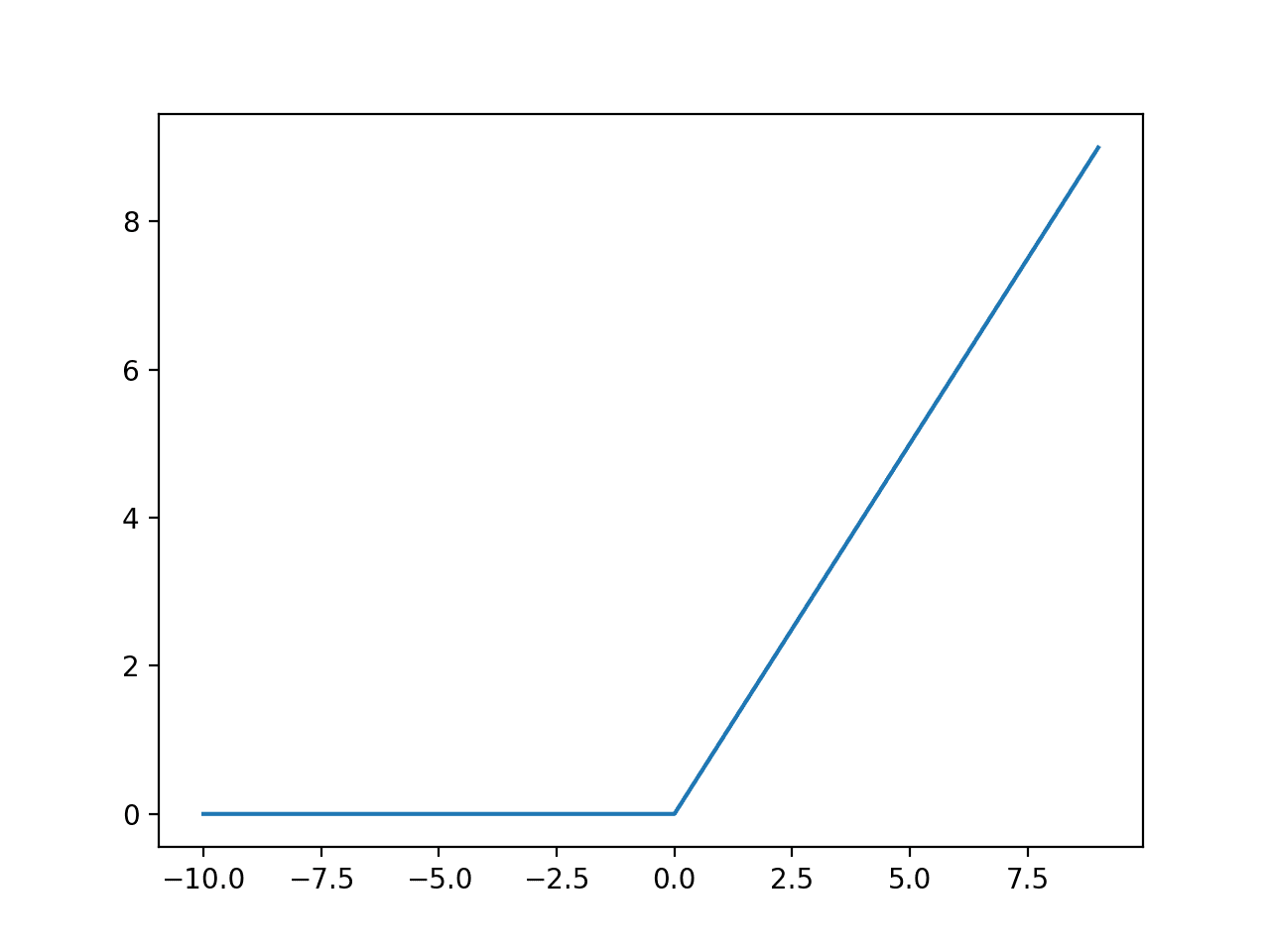
💡 ReLU (Rectified Linear Unit)
- Vanishing gradient 문제 완화: 양수 입력에서는 기울기가 1로 유지되어 학습이 잘 진행됨.
- 계산 효율성: 단순한 max(0, x) 연산으로, 계산 속도가 빠르고 구현이 간단함.
- 단점: 음수 입력에서 기울기가 0이 되어 뉴런이 죽는 문제 (dying ReLU problem)가 발생할 수 있음

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.