
이 블로그글은 2019년 조재영(Kevin Jo), 김승수(SeungSu Kim)님의 딥러닝 홀로서기 세미나를 수강하고 작성한 글임을 밝힙니다.
💡 도움이 되셨다면 ♡와 팔로우 부탁드려요! 미리 감사합니다.
Hyperparameter Tuning
목적
- 모델의 성능을 향상 시키기 위해서
- 즉, 모델의 True Risk(Generalization Error)를 줄이기 위해서
→ Validation 데이터셋의 Emprical Risk를 줄임으로써 전체의 True Risk를 간접적으로 줄이자.
두가지 접근법
- 근복적으로는 Optimal한 epoch와 model을 신경써야 한다.
Model Related
- Hidden layer의 수 결정
- Hidden unit의 수 결정
- Activation Function 결정
Optmimzation Related
- 어떤 Optimizer를 쓸지?
- Learning rate 설정
- L2 coef
- Dropout Rate
- Batch Size
- Epoch
→ 튜닝의 순서는 Model Related 부터 위에서 아래로 해보는 것이 좋아보인다. 하지만 왕도는 없다. (강의자님의 의견입니다.)
설정 방식 (참고)
- 정답은 아님, 데이터셋에 따라 Fleixible하다.
Hidden layer의 수 결정
- MLP에서는 1 ~ 10 layers 정도를 선택
- CNN의 경우 주로 ~152개 정도 쌓고 ~1000개 layer를 쌓기도 한다.
Hidden unit의 수 결정
- layer당 10 ~ 1024 unit정도, 많으면 2048까지도 시도해볼만하다.
Activation Function 결정
- hidden layer의 경우 non-Linear한 특성이 꼭 필요하기 때문에
-
sigmoid와 tanh는 잘 사용하지 않음 → gradient vansihing 때문
→ 이진 분류 문제의 출력층에서는 여전히 sigmoid를 자주 사용
-
ReLU, LeakyReLu, GeLU, Elu 등이 있고 ReLU를 가장 많이 쓰곤한다.
-
어떤 Optimizer를 쓸지?
- 가장 primary한 것이 GD이고 잘 사용하지 않는다.
- GD : iteration 마다 모든 데이터셋을 다보고 업데이트
- SGD는 쓸만한다.
- SGD : iteration 마다 데이터셋을 하나하나씩 보고 업데이트
- 원래 이론적으로는 한 번에 하나의 샘플을 보고 업데이트하는 방식입니다. 하지만, 실제 구현에서는 많은 경우 미니배치로 처리한다.
- RMSPROP, Adam, AdaDelta 등이 있고 Adam을 많이 쓰곤 한다.
→ 그러면 제일 좋은걸 쓰면 되지않을까? 데이터셋에 영향을 많이 받으므로 성능이 다를 수 있다. (SGD가 쉬운 문제의 경우 유리하곤 한다.)
Learning rate 설정
- 1e-5 ~ 1e-1 사이의 값을 선택
-
Log Scale로 바꿔 사용
- 0.00001
- 0.0001
- 0.001
- 0.01
- 0.1→ 시도해보고 가장 괜찮은 거 같은데서 Linear space에서 실험
예) 0.001, 0.003, 0.005
-
L2 coef
- 1e-5 ~ 1e5 사이의 값을 선택
- Log Scale로 바꿔 사용
- 0.00001
- 0.0001
- 0.001
- 0.01
- 0.1
- 1.0
- 10
- 100
- 1000
- 10000
- 100000
- Log Scale로 바꿔 사용
Dropout Rate
- 1 ~ 0.5를 일반적으로 많이 사용
- 모델이 너무 complex한데 데이터가 부족하면 0.7까지 늘리곤 (overfitting을 막기 위함)
Batch Size
- 데이터와 모델에 의존한다.
- 결정하는 두가지 방법
- 배치 size를 최대한 키운다. (Out of memory가 뜰 때까지)
- 병렬로 연산되므로 한 번 연산에 배치 size를 최대한 크게 넣음
- 만약 overfitting이 너무 심각하면, batch size를 줄여준다.
- 배치 size를 최대한 키운다. (Out of memory가 뜰 때까지)
- 일반적으로 128, 256, 512의 값을 사용 → 왜 2의 제곱꼴로 사용하는지? 2의 제곱꼴 크기는 메모리 페이지의 경계에 맞아 데이터 접근을 최적화하는 데 도움이된다.
Epoch
- Train Loss와 Validation Loss를 계속 모니터링한다.
- Early Stopping
- 만약 validation loss가 N epoch 이후에도 줄어들지 않으면 학습을 종료한다.
💡 본인만의 하이퍼파라미터 튜닝 방법은 다룰 수 있다.
하이퍼파라미터를 튜닝하는 4가지 방법
- Tune Experiment : 모델의 성능을 최적화하기 위해 하이퍼파라미터 튜닝(hyperparameter tuning)을 수행하는 실험을 말한다.
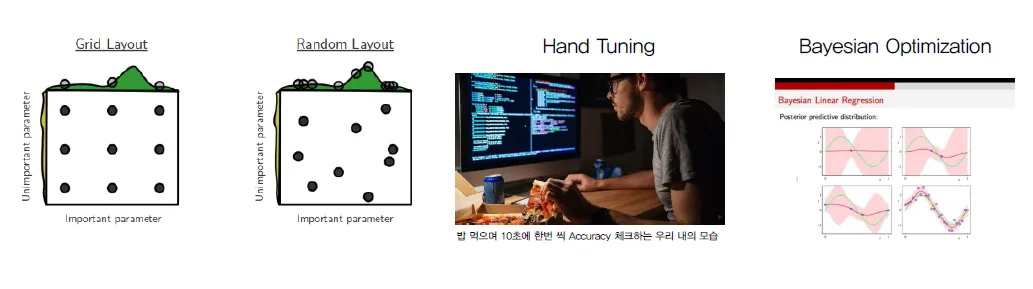
Grid Search
- 설정된 하이퍼파라미터 범위(space)를 미리 정의하고, 가능한 모든 조합을 시도하며 최적의 파라미터를 찾는다.
- 각 조합에 대해 모델을 학습시키고 평가하여 가장 성능이 좋은 조합을 선택한다.
Random Search
- 하이퍼파라미터 space에서 임의로 샘플링하여 조합을 선택한다.
- 전체 조합을 모두 탐색하지 않고 랜덤한 일부 조합으로 실험하므로, 시간이 절약될 수 있다.
Hand Tuning
- 경험과 직관을 바탕으로 하이퍼파라미터를 직접 설정하고 실험하여 최적화를 시도한다.
- 자동화되지 않은 방법으로, 데이터셋과 모델에 대한 깊은 이해가 필요하다.
Bayesian Optimization
- 이전 시도들의 결과를 바탕으로, 다음 실험할 하이퍼파라미터 조합을 더 효율적으로 선택하는 방법이다.
- 확률 모델(주로 가우시안 프로세스)을 사용해 하이퍼파라미터 space를 모델링하고, 성능이 좋을 것으로 예상되는 영역을 탐색한다. (통계적 기법을 사용)
- 불필요한 실험을 줄이고, 적은 시도로도 최적의 파라미터에 빠르게 수렴할 수 있다.
→ 그렇다면 무엇을 고를 것인가?
강의자분 추천
- Grid Search를 먼저 시도해서 다양한 옵션들이 결과에 어떤 영향을 주는지 경향성을 확인한다.
- Random Search로 미처 알지 못한 조합을 실험한다.
- 적당한 값에서 Hand Tuning 해본다.
- 어느 정도 파악이 되면 탐색하고 싶은 구간을 설정하고 (하이퍼파라미터 space를 제한하고) Bayseian Optimization을 시도한다.
💡 AutoML
- 모델 선택, 하이퍼파라미터 튜닝, 전처리 등 머신러닝 파이프라인의 여러 단계를 자동화하여 최적의 모델을 찾는 방법이다.
- 일반적으로 그리드 서치, 랜덤 서치, 베이지안 최적화 등의 기법을 활용하여 다양한 알고리즘과 하이퍼파라미터 조합을 시도하고, 최적의 성능을 내는 모델을 자동으로 선택한다.
- 데이터 전처리, 특징 엔지니어링, 모델 선택, 하이퍼파라미터 튜닝 등을 모두 자동으로 수행하므로, 머신러닝 지식이 적은 사람도 쉽게 사용할 수 있다.
- AutoML은 특히 대규모 데이터와 복잡한 모델링 작업에서 유용하며, 시간이 부족하거나 효율성을 극대화하고자 할 때 사용된다.
Human bias
문제 상황

- Test 데이터셋의 성능을 높이려고 학습한다.
- Test 데이터셋이 사람을 학습하는데 써버리게 되는 효과
→ Test 데이터셋은 학습과정에 노출되서는 안된다.
수정

- Test 데이터셋 대신에 Validation 데이터셋으로 테스트해보면서 성능을 높여나가자.
→ 모델을 준비하고 객관적인 평가를 할때 Test 데이터셋을 사용한다.

4개의 댓글

저도 학교 졸업작품으로 LSTM 모델 구현할 때 하이퍼파라미터 튜닝했던 기억이 새록새록나네요.
배치사이즈도 2의 배수로 하면 메모리 활용에 도움이 되지않을까 추측만 했었는데 정말 도움이 됐었다니 신기합니다 ㅎㅎ
전 뭐가 뭔지도 모르겠네요...ㅠㅠ