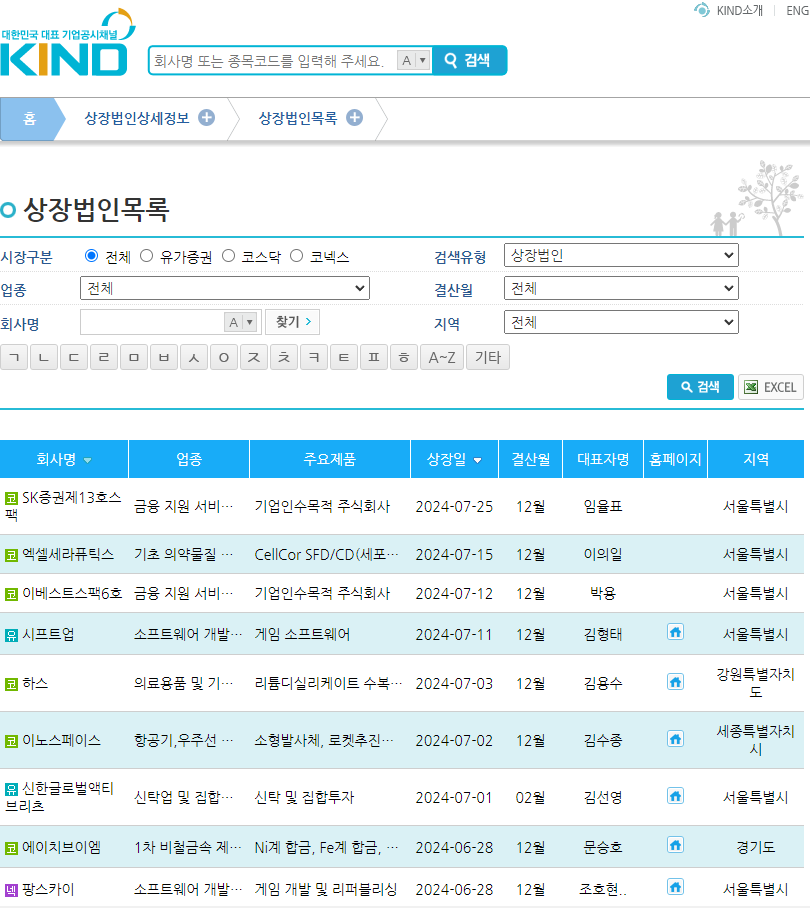
본 페이지 크롤링을 진행했다.
url = "https://kind.krx.co.kr/corpgeneral/corpList.do"
payload = dict(method='loadInitPage')
r = requests.get(url, params = payload)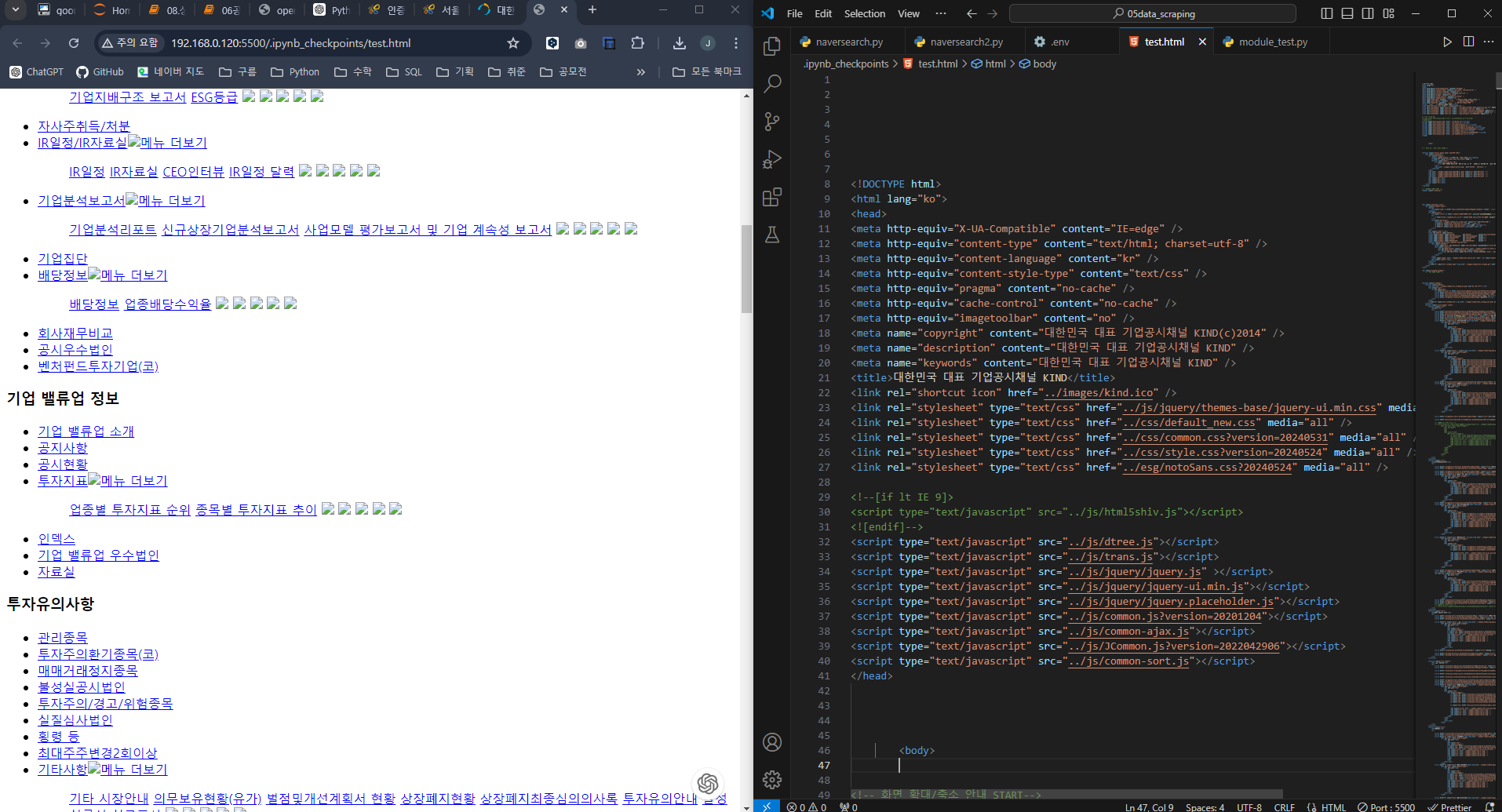
크롤링한 데이터를 가져와서 다시 서버에 띄움
그런데 내용이 없다!
개발자 모드로 봤을 때 이 영역은 자바스크립트로 데이터를 불러오는 영역이라
껍데기에는 노출되지 않음
url = "https://www.yes24.com/Product/Category/BestSeller"
payload = dict(categoryNumber='001',pageNumber=1,pageSize=24)
r = requests.get(url, params = payload)
# print(r.text)
soup = bs(r.text, 'lxml')
soup그래서 Get 방식으로 만들어진 Yes24 베스트셀러 페이지 를 크롤링해보았다.
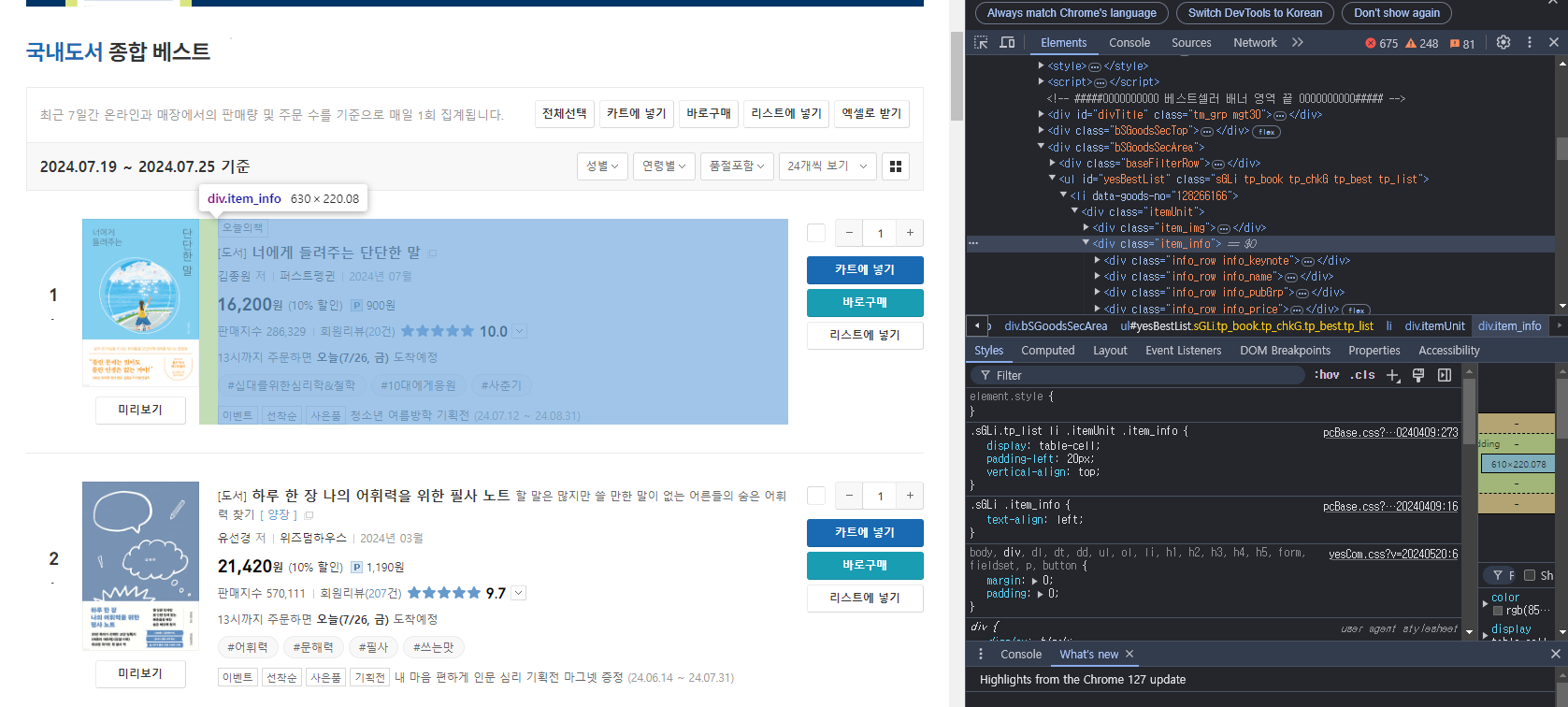
도서 정보를 css selectors를 통해 도서 정보를 추출해봤다.
BeautifulSoup의 find와 select를 사용했는데
나는 find가 편해서 find를 사용했다.
그리고 아주 열심히.. 노가다를 했다!!!
book = {}
#종류
for sort in soup.find_all('span', 'gd_res'):
book.setdefault("title", []).append(sort.string)
#도서명
for name in soup.find_all('a', 'gd_name'):
book.setdefault("name", []).append(name.string)
#도서상세링크
for link in soup.find_all('a', 'gd_name'):
book.setdefault("link", []).append('https://www.yes24.com/' + link['href'])
#저자명
for auther in soup.find_all('div', 'info_row info_pubGrp'):
book.setdefault("auther", []).append(auther.find('a').string)
#출판사명
for pub in soup.find_all('span', 'authPub info_pub'):
book.setdefault("pub", []).append(pub.find('a').string)
#출간일
for day in soup.find_all('span', 'authPub info_date'):
book.setdefault("day", []).append(day.string)
#가격
for price in soup.find_all('em', 'yes_b')[::2]:
book.setdefault("price", []).append(price.string)
#적립포인트
for point in soup.find_all('span', 'yPoint'):
book.setdefault("point", []).append(point.text)
#판매지수
for rating in soup.find_all('span', 'saleNum'):
book.setdefault("rating", []).append(rating.text.strip())
#회원리뷰
for custom in soup.find_all('em', 'txC_blue'):
book.setdefault("custom", []).append(custom.text)
#평점
for star in soup.find_all('em', 'yes_b')[1::2]:
book.setdefault("star", []).append(star.text)
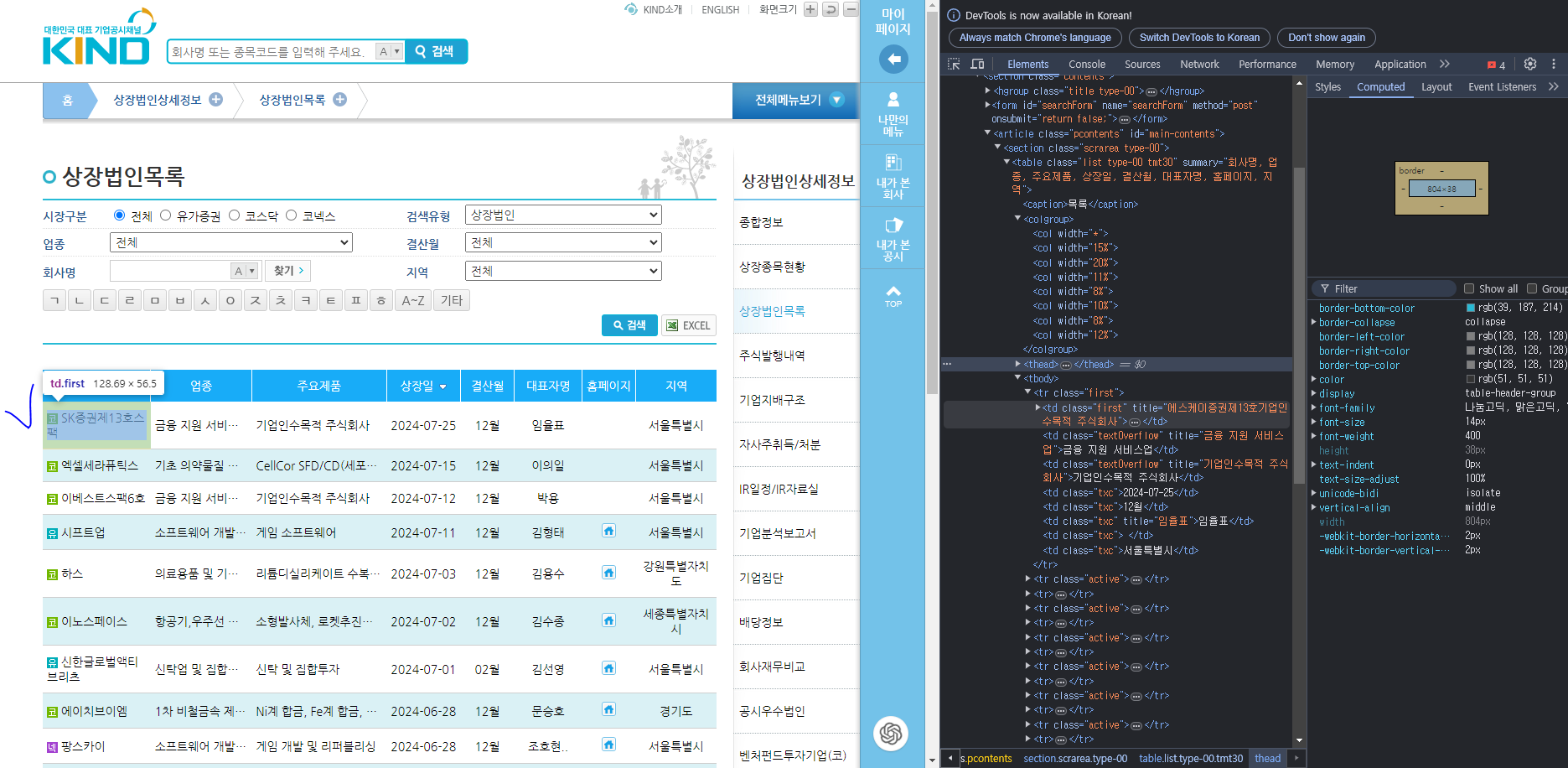
book코드 우클릭 > copy selcetor 통해 경로를 볼 수 있음
이후 넘파이를 통해 데이터 프레임에 저장했다.
import numpy as np
lengths = [len(v) for v in book.values()]
max_length = max(lengths)
# 길이가 맞지 않는 리스트를 NaN 값으로 채워서 길이를 동일하게 만듭니다.
for key in book:
if len(book[key]) < max_length:
book[key] += [np.nan] * (max_length - len(book[key]))
# 데이터프레임으로 변환
df = pd.DataFrame(book)
df
갠적으로 재밌었다 ㅎㅎ 웹기획자로 일함에도 개발자 코드를 볼 줄 몰랐는데 이제 조금 알게돼서 재미를 느끼는 것 같다.
다시 기업공시채널 KIND 페이지로 돌아와서 Headers 를 통해 웹에 보낸 요청과 받은 요청을 살펴본다.
post 방식은 숨겨져 있다.
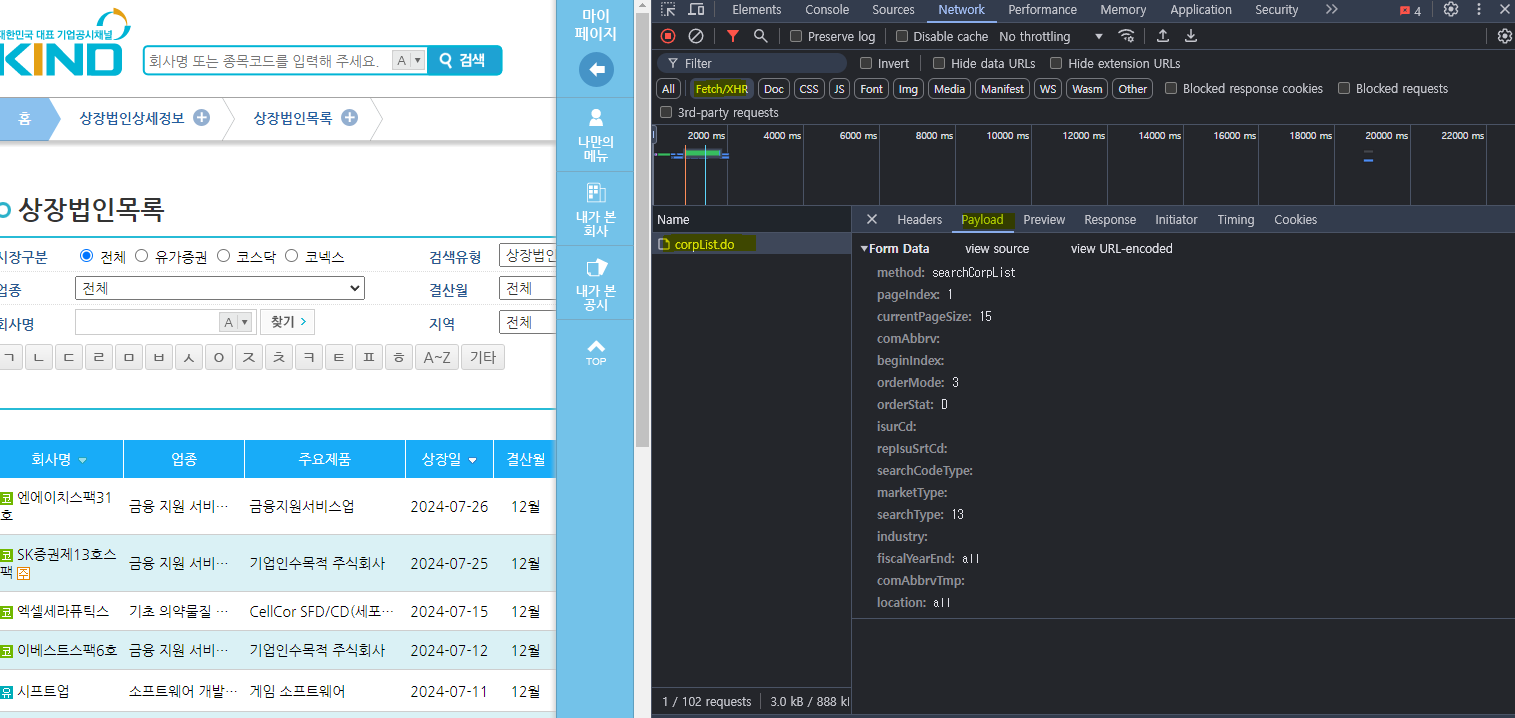
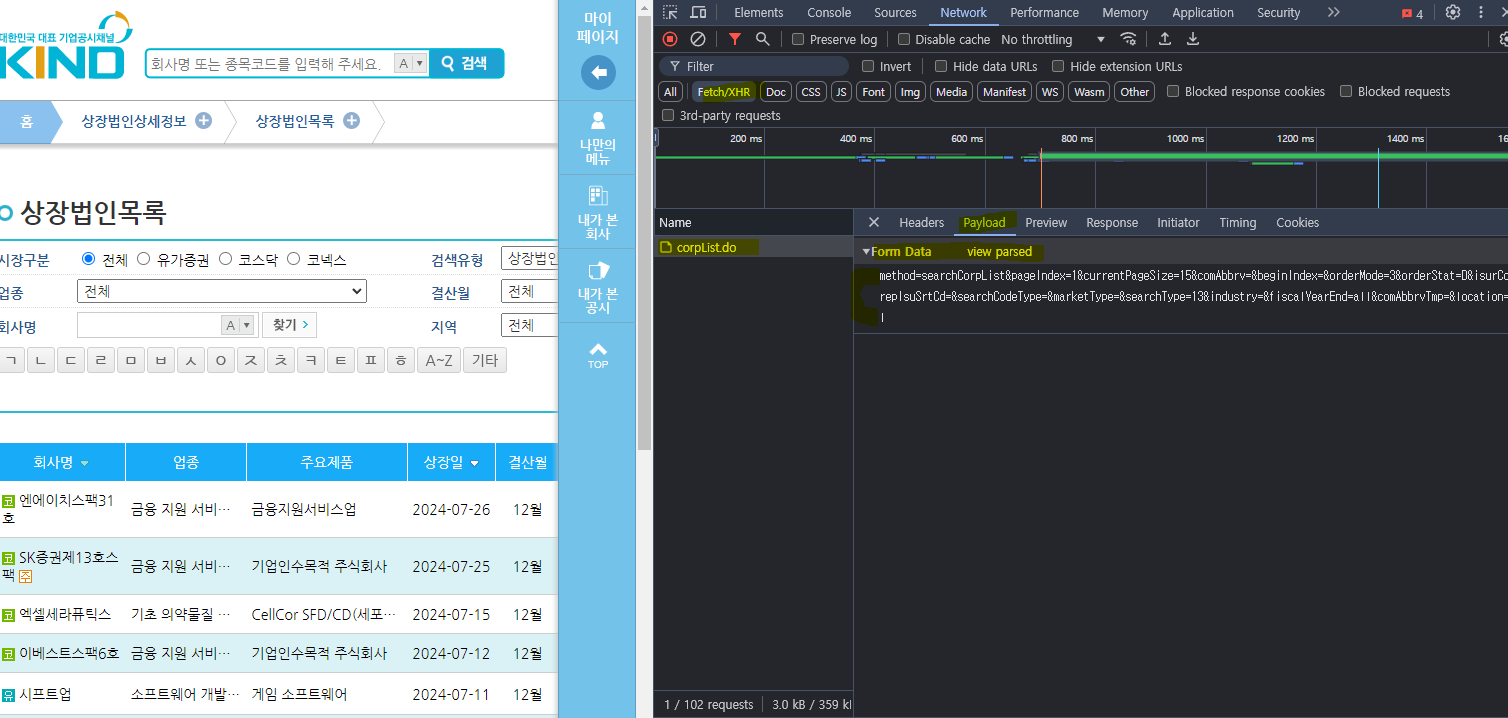
위 파라미터를 복사해서 url에 붙여넣기하면

짜잔~ 숨겨져있는 정보를 크롤링할 수 있다.

안녕하세요. 김지연입니다.