- Transport-layer services
- Multiplexing & demultiplexing
- Connectionless transport: UDP
- Principles of reliable data transfer
- Connection-oriented transport: TCP
- Principles of congestion control
- TCP congestion control
- Evolution of transport layer funcitonality
Transport layer services
Transport Services and protocols
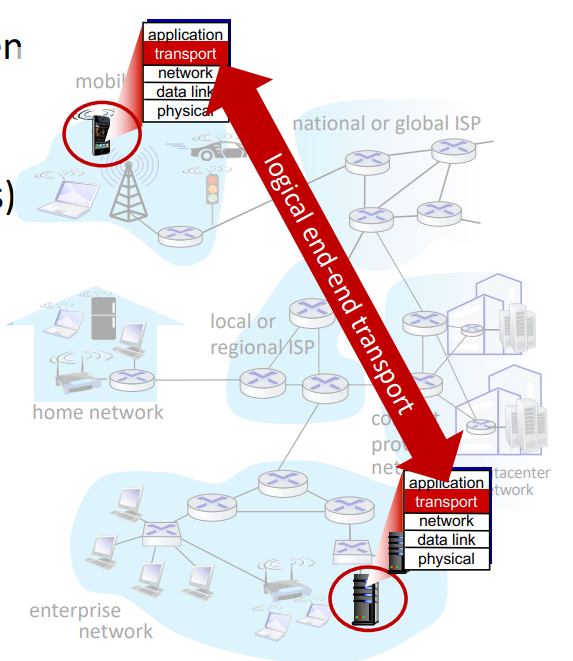
- Network layer : 다른 host 간의 logical communicaiton
- Transport layer : 다른 host에서 실행중인 process 간의 logical communication
- Transport protocol은 end system에서 행동한다.
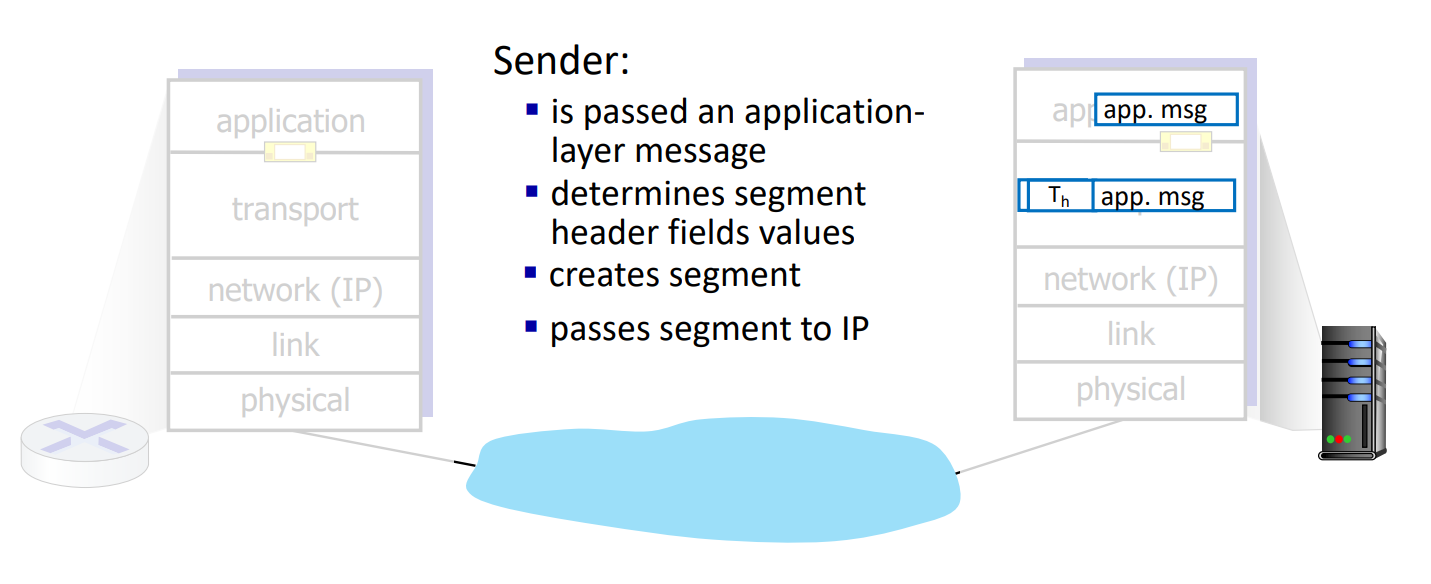
- sender : application message를 segment들로 쪼개고 network layer로 전달한다.
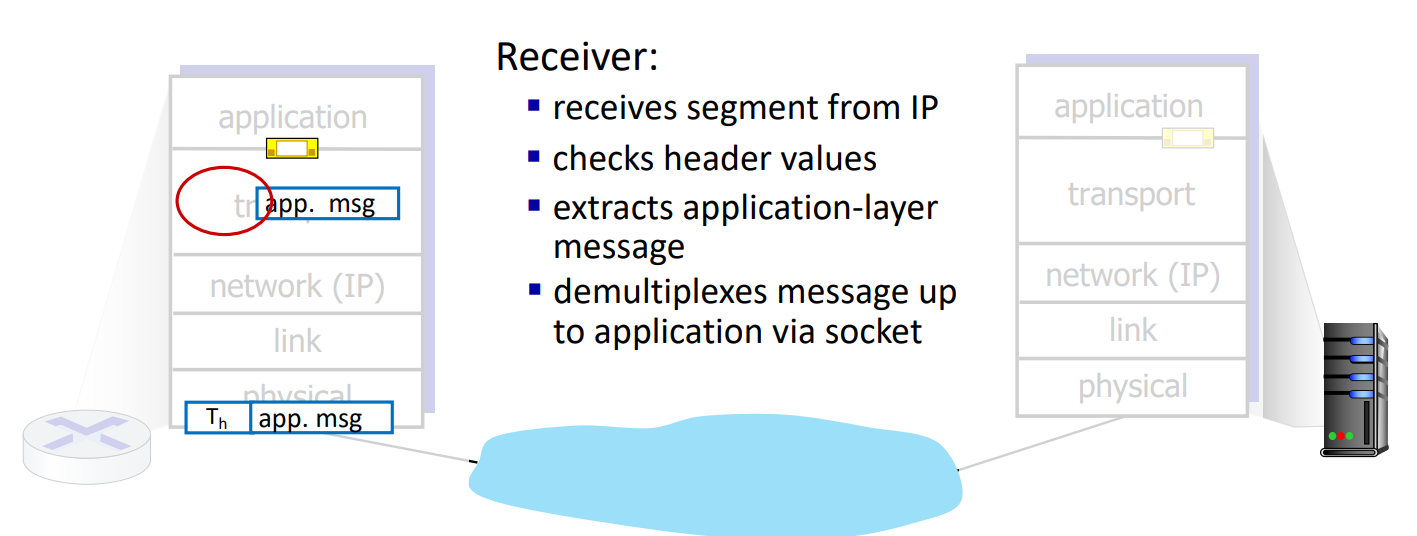
- receiver : segment들을 재정렬해 message로 만들고 application layer로 전달한다.
- 두 종류의 transport protocol : TCP / UDP
Transport Layer Actions
Two principle Internet transport protocols
-
TCP : Transmission Control Protocol
- reliable, in-order delivery : 데이터가 올바른 순서대로 도착할 수 있다.
- congestion control : 데이터 전송 속도를 조절해 과도한 전송으로 인해 대역폭을 초과하는 것을 방지해준다.
- flow control : receiver의 capacity에 맞춰서 데이터를 전송하게 한다.
- connection setup : handshaking 과정.
-
UDP : User Datagram Protocol
- unreliable, unordered delievery : 데이터가 도중에 손실될 수도 있고, 다른 순서로 도착할 수 있다.
- no-frills extension of "best-effort" IP
- IP는 목적지까지 데이터를 잘 전달하기 위한 행위만 한다. 전송 속도에 대해 아무런 보장을 하지 않으며, 정보가 도착할 것이라는 약속조차 하지 않는다. 그래서 IP 데이터 전송을 'best effort'(전달만 하는 최선의 서비스) 방식이라고 한다.
-
services not available:
- delay guarantees
- bandwith guarantees
- 즉, transport layer에서는 delay되는 정도와 bandwith를 조정할 수 없다. (데이터 양조절을 못함)
+) Datagram : 데이터그램은 사용자의 순수한 message를 다르게 부르는 말이다.
Multiplexing & Demultiplexing
Multiplexing / Demultiplexing
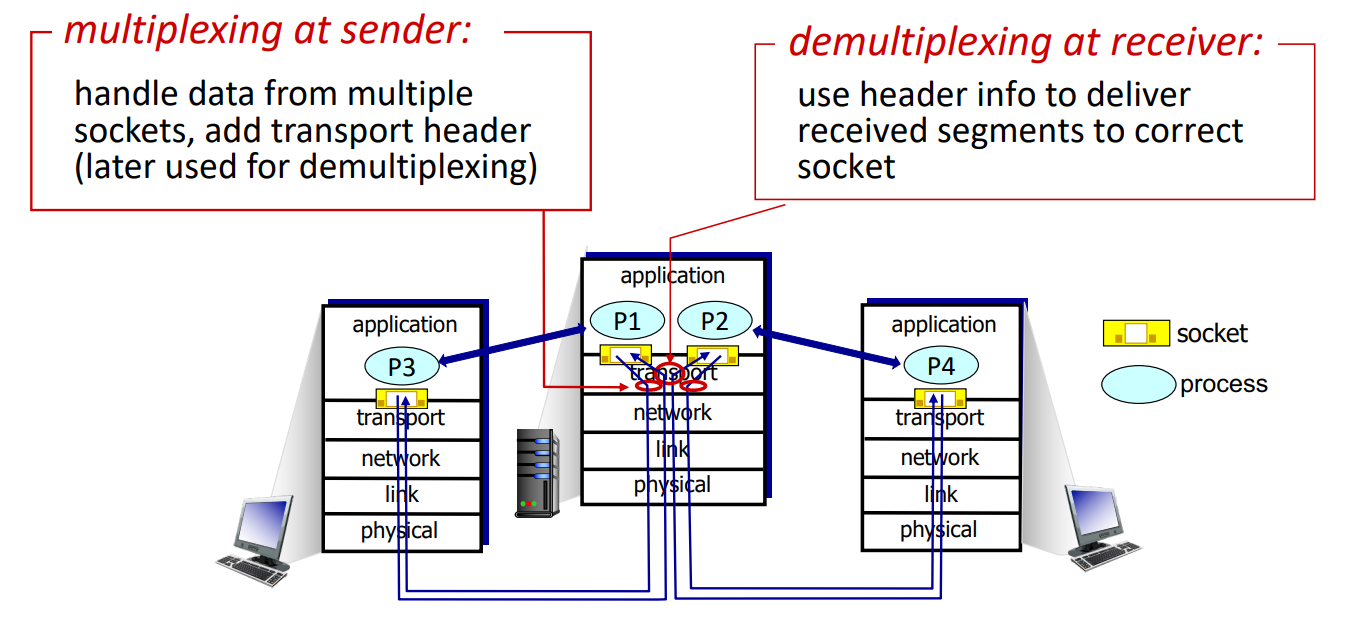
Multiplexing은 sender에서 수행되는 것으로, 여러 socket들의 데이터를 모아 transport header를 부착해 packet으로 만든 후 하위 레이어로 전송하는 과정이다.
Demultiplexing은 receiver에서 수행되는 것으로, 전달받은 packet의 header info를 이용해 수신한 segment가 올바른 socket으로 전달되도록 상위 레이어로 전송하는 과정이다.
+) 혼동을 방지하기 위한 사진 두개 (화살표 방향)
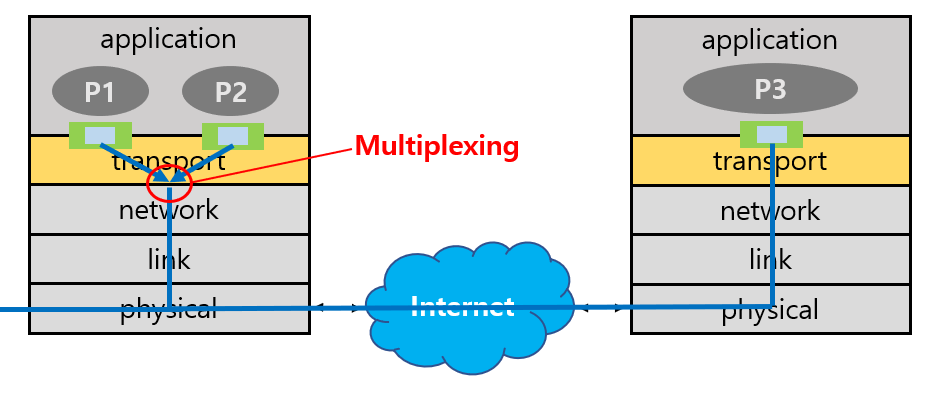
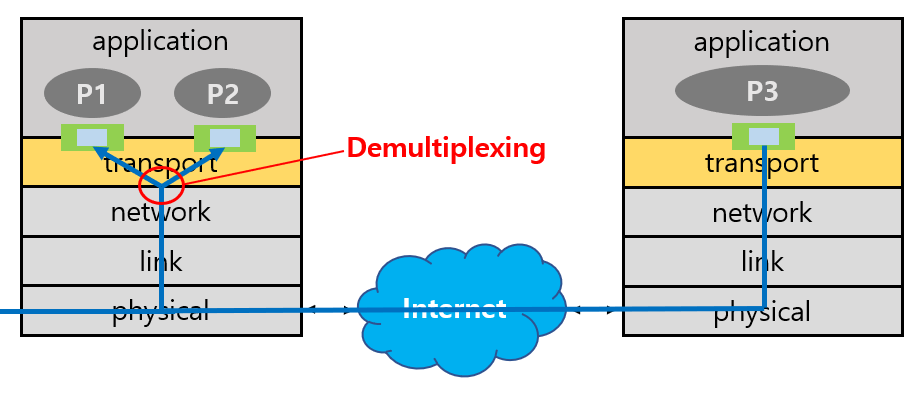
How demultiplexing works
그렇다면 지금부터 receiver에서 어떻게 transport header를 분석해서 대응되는 socket을 찾는지 알아보자.
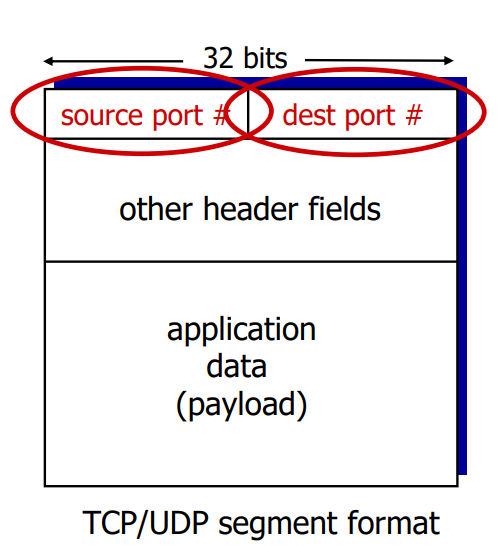
Host는 IP datagram을 수신하게 되고, 이때 각 datagram은 source IP address와 destination IP address를 가지고 있다. 이때 각 datagram은 하나의 transport-layer segment를 운반하며, 각 segment는 source, destination port number를 가지고 있다. 위 그림은 이 segment 부분의 대략적인 구조를 표현하고 있다.
Host는 datagram이 가진 IP address와 segment가 가진 port number를 이용해 적절한 socket을 찾을 수 있게 된다.
Connectionless demultiplexing (UDP)
앞서 UDP에서 socket을 생성할 때 host-local port #를 명시했던 것이 기억날 것이다.
- datagram_socket = socket(AF_INET, SOCK_DGRAM).bind(('', 50001));
이처럼 UDP socket을 이용해 datagram을 전송하려면 destination IP address와 destination port number를 명시해야 한다.
그리고, host가 UDP segment를 받게 되면 segment에 포함된 destination port #를 확인하고, 해당 port #에 대응되는 socket으로 보내게 된다.
- 이때 UDP에선 특정한 connection이 존재하지 않기 때문에, 서로 다른 IP 주소와 port를 가진 socket에서 같은 destination port #로 IP/UDP datagram을 보내면, receiver 측에선 하나의 socket으로 이를 처리할 수 있다.
example
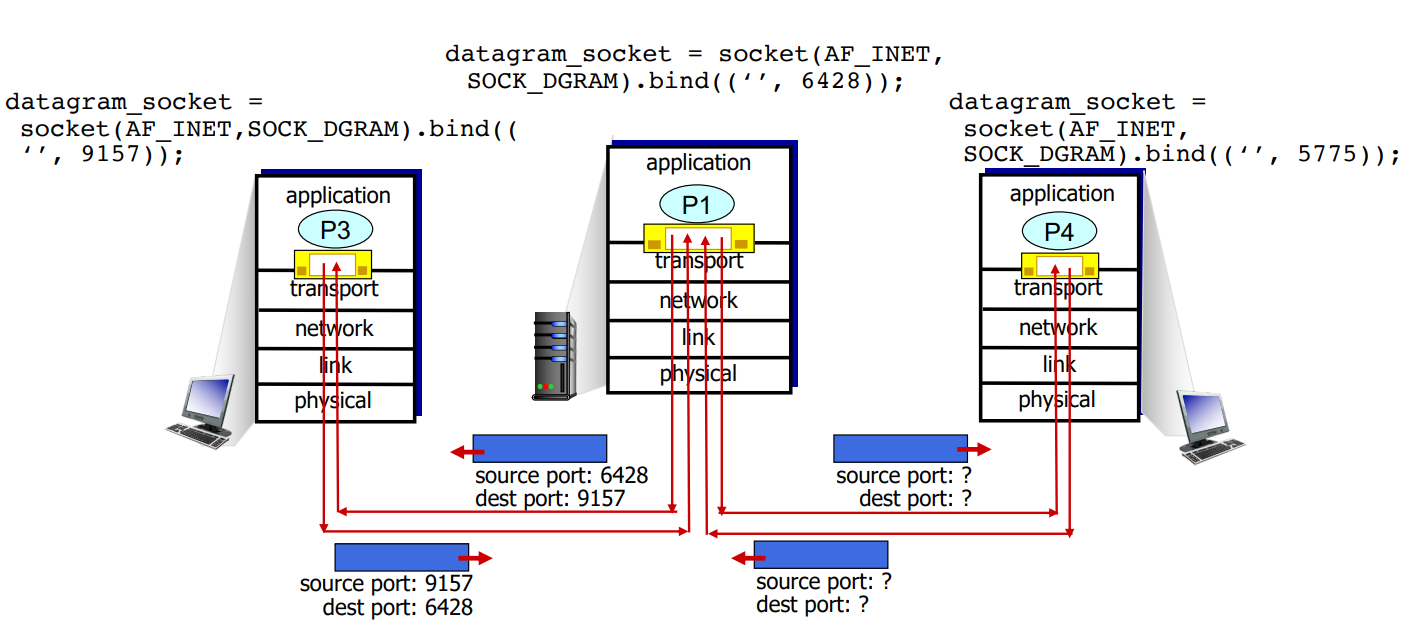
P1 - 6428 / P3 - 9157 / P4 - 5775 port
앞에서 얘기한 것 처럼 P1이라는 하나의 socket을 이용해 P3, P4 socket과 communicate하고 있다. 이때, P3과 P4이 같은 socket P1으로 데이터를 보낼 수 있다.
Connection-oriented demultiplexing (TCP)
TCP의 경우 socket을 명시하기 위해 4 tuple이 필요하다.
- source IP address
- source port number
- destination IP address
- destination port number
따라서 demux과정에 receiver는 이 4가지 값 모두를 이용해서 segment에 대응되는 socket으로 보내게 된다.
Server는 여러 개의 simultaneous TCP socket을 지원해야 하고, 이를 위해 각 socket은 고유한 4 tuple값을 가지며 서로 다른 client와 연결되게 만들었다.
example
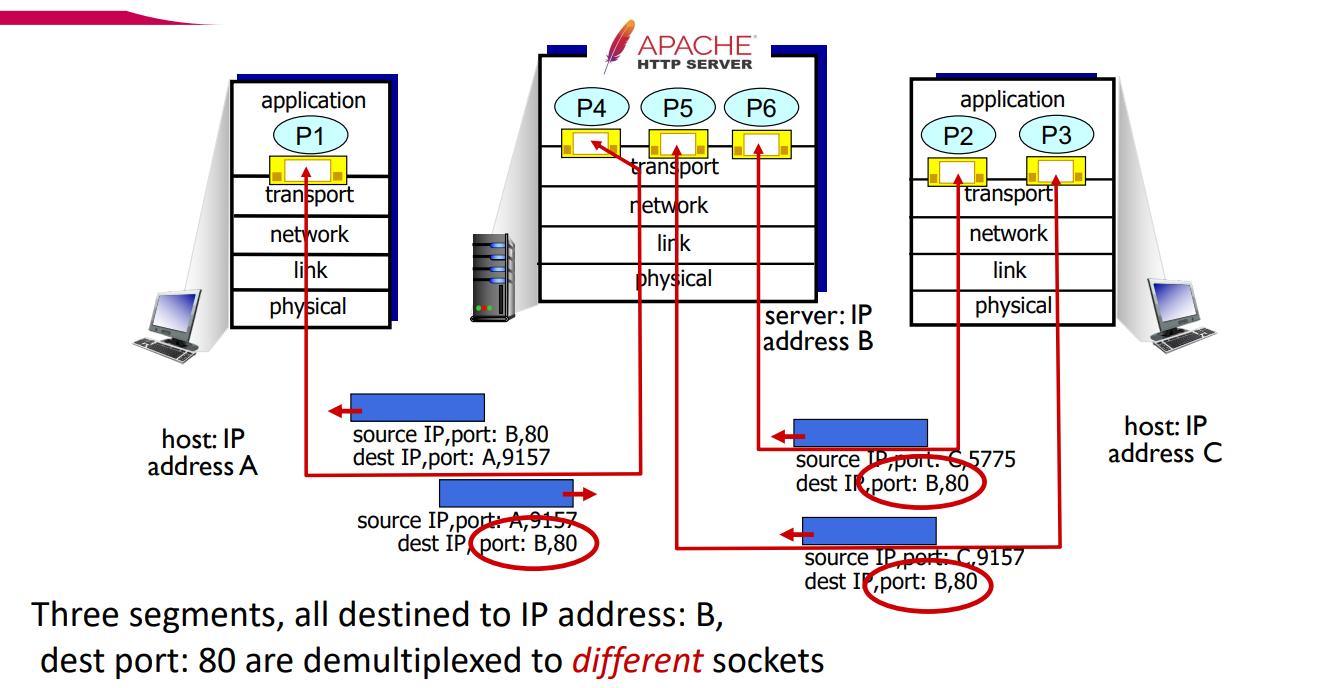
이 그림을 통해 simultaneous TCP socket을 더욱 잘 이해할 수 있다.
그림에 나타나는 P1, P2, P3가 모두 B라는 주소의 80 port #로 접촉을 시도하고 있다. 그럼에도 불구하고 각각의 client에 대응되게 P4, P5, P6의 socket을 각각 배정해주며, 이는 receiver측에서 같은 dest 정보를 가져도 다른 source 정보를 가진 것을 파악해 서로 다른 socket으로 demultiplex해주어 나타난 결과이다.
+) Summary
결과적으로 multiplexing과 demultiplexing은 segment와 datagram의 header field에 명시된 값들을 이용해 이루어지는 것이다.
- UDP의 경우 destination port number만을 이용해 demux를 진행
- TCP의 경우 4-tuple (dest IP, port, source IP, port)를 모두 이용해서 demux를 진행한다.
Connectionless transport: UDP
UDP: User Datagram Protocol
UDP는 "no frill", "bare bone" internet transport protocol로 "best effort" service를 제공한다. 즉, 단순하게 데이터를 전달하는 것만을 제공하고, 그 과정에서 데이터의 손실이나 out-of-order같은 건 신경쓰지 않는다는 뜻이다.
또한, UDP sender와 receiver간에 handshaking이 없고, 각 UDP sgement는 독립적으로 처리되기 때문에 connectionless라 지칭한다.
왜 UDP를 사용하는가?
이렇게 단점이 많아보이는 UDP를 현재에도 사용하는 이유가 뭘까?
- UDP는 connection establishment 과정이 존재하지 않기 때문에 이때 발생하는 RTT delay가 추가되지 않는다.
- connection state를 관리하지 않아 단순한 구조를 가지고 있다.
- 작은 header를 가지고 있다.
- congestion control이 없다.
이러한 특징들 때문에 UDP는 TCP 방식에 비해 매우 빠르게 전송이 가능하고, congestion이 발생한 상황에도 사용이 가능하다.
UDP는 빠른 속도를 보장한다는 특징 때문에 delay에 민감한 application들에서 많이 사용된다. 대표적으로 streaming multimedia app(loss tolerant, rate sensative), DNS, SNMP, HTTP/3 등이 있다.
만약 reliable transfer가 UDP에서 필요하면, application layer에서 reliability와 congestion control을 추가해서 해결한다. (HTTP/3 방식)
application layer에서 추가?또한, Application Layer에서 congestion control 기능을 추가할 수 있습니다. Congestion Control은 네트워크 혼잡 상태를 감지하고 데이터 전송 속도를 조절하여 네트워크 혼잡을 방지하는 기능입니다. 이 기능을 추가하여, UDP의 데이터 전송 속도를 제어하고, 네트워크 혼잡을 방지할 수 있습니다.
UDP를 이용하여 reliability와 congestion control 기능을 추가하는 것은 가능하지만, 이는 TCP의 기능과 유사해지기 때문에, UDP를 사용하는 이점을 상실할 수 있습니다. 따라서, 이러한 기능이 필요한 경우에는 TCP를 사용하는 것이 더 적절할 수 있습니다.
UDP: Transport Layer Actions
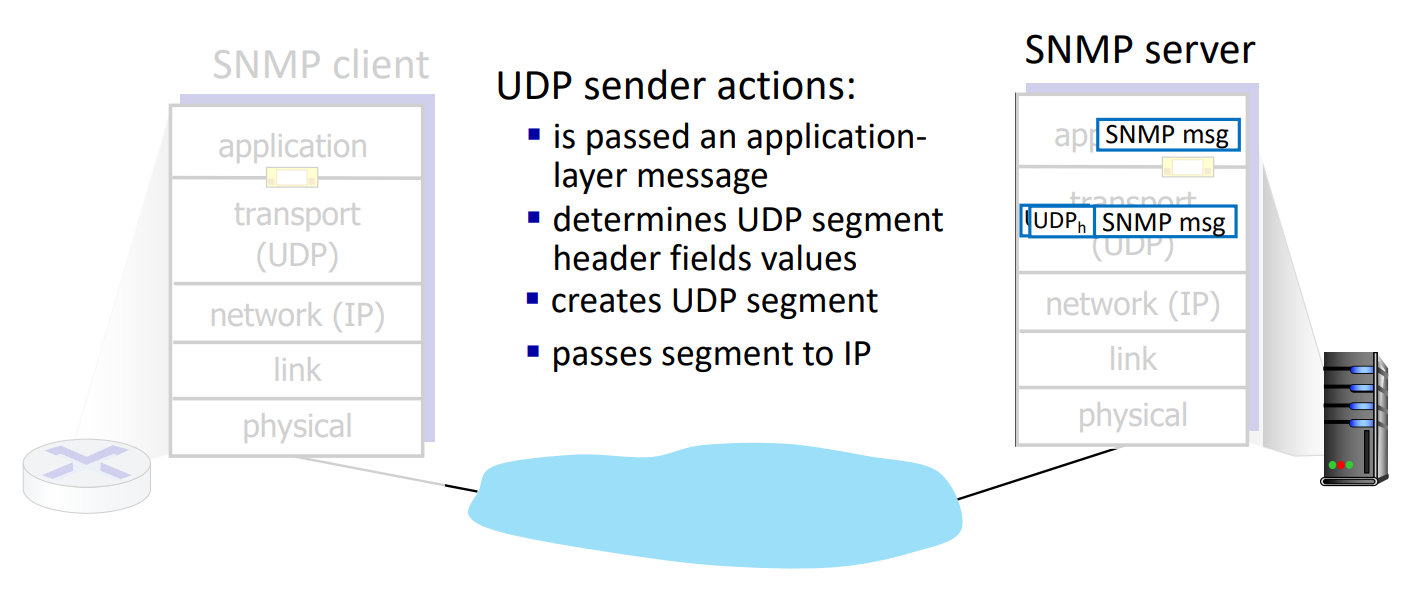
UDP sender는 application layer의 message를 socket을 통해 전달받은 후, header field를 추가하여 UDP segment를 만들어낸다. 이를 IP를 통해 하위 레이어로 보낸다.
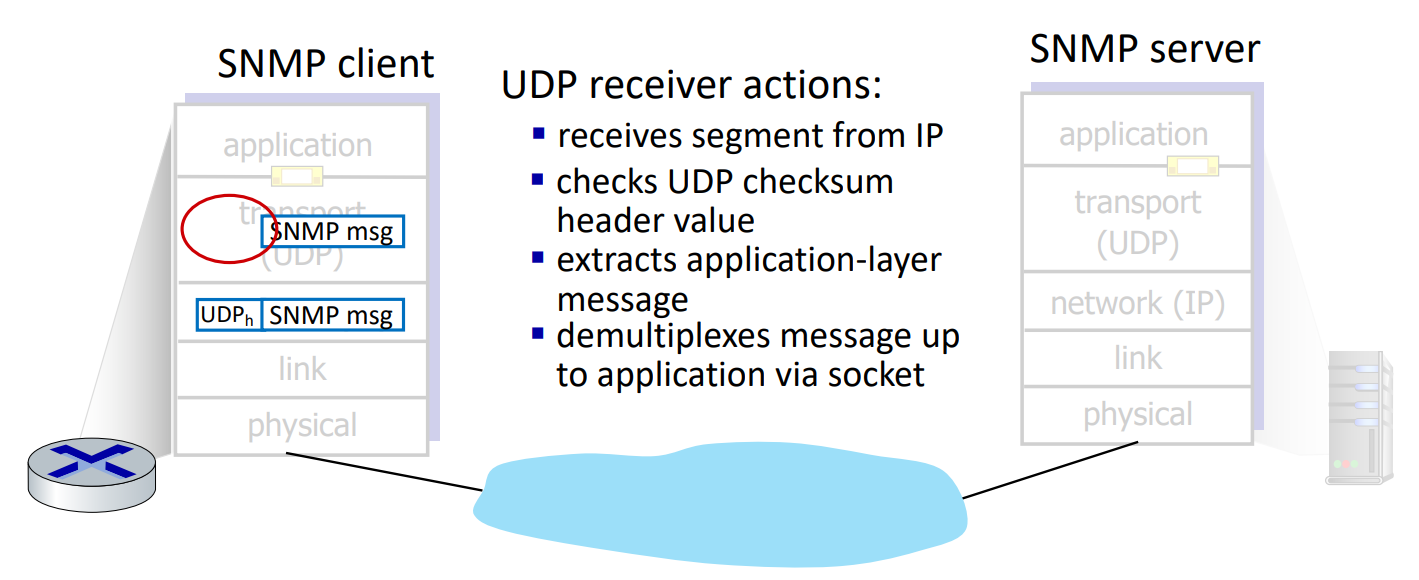
UDP receiver는 IP를 통해 segment를 받아 header 정보를 이용해 checksum을 확인하고, demultiplex를 통해 대응되는 socket으로 보낸다.
UDP segment header
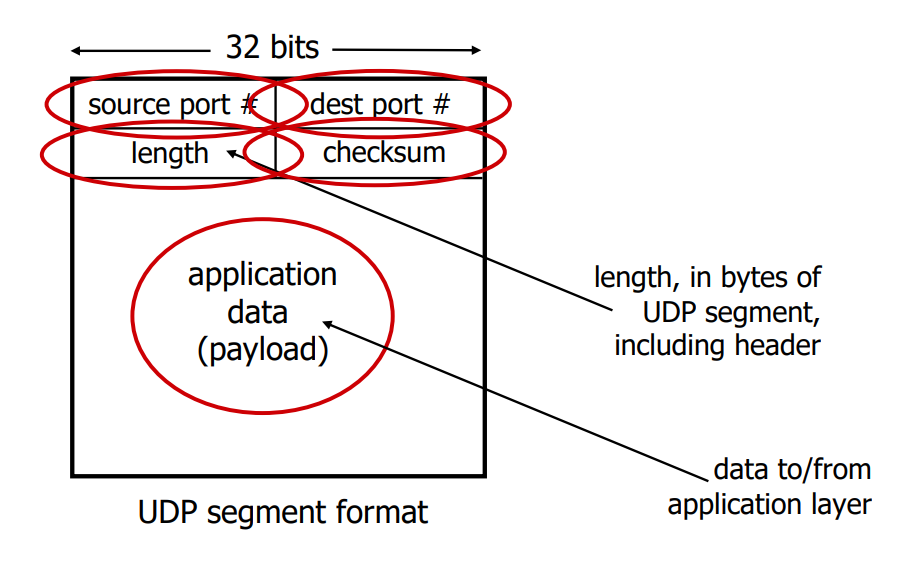
UDP segment header는 다음 정보들로 구성된다.
- source port # (2byte)
- dest port # (2byte)
- length (2byte)
- UDP 세그먼트 전체의 길이를 바이트 단위로 나타내며, 이때 헤더와 데이터를 모두 포함한 길이를 나타낸다.
- checksum (2byte)
- 이 값을 통해 에러를 검출할 수 있다. Sender가 udp segment를 만들때 checksum을 계산해 이 곳에 저장한다. Receiver가 추후 이 값을 이용해 에러를 검출한다.
헤더는 총 8byte로 구성되고, body에는 apllication data (payload)가 들어간다.
UDP checksum
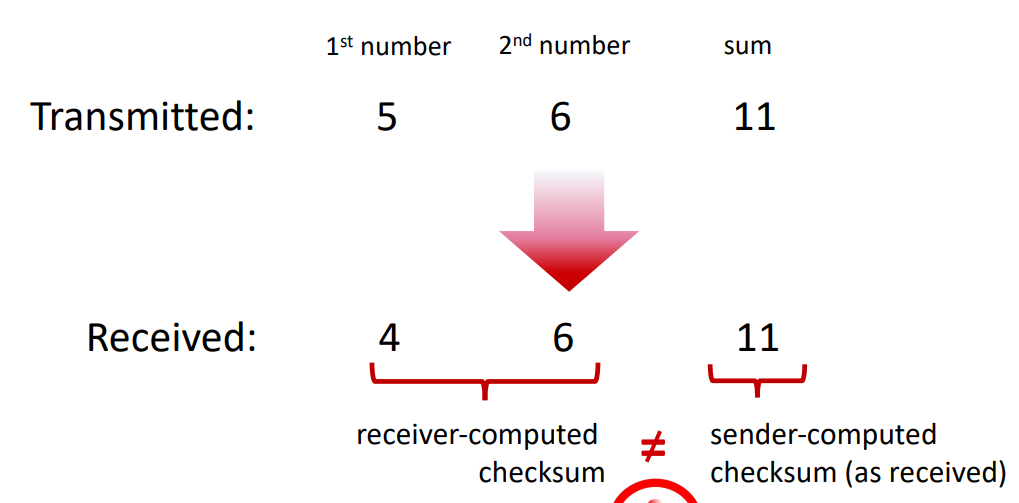
UDP checksum은 segment를 전송하는 과정에서 비트가 바뀌는 등의 문제가 발생하지 않았는지 확인하기 위한 수단이다. 이는 sender에 의해 결정되며 전송 이후에도 값이 일정하다면 전송 과정이 정상적일 확률이 높고(에러가 없다는 것은 아니다), 값이 다르다면 문제가 발생하였음을 확인할 수 있다.
Internet checksum

UDP sender 측에서 segment의 하위에 2개의 16bit의 word가 있었고, 이 두 값을 더한 뒤 overflow 된 bit이 wrapped되어 더해진 sum을 구한다. 그 후, 1s complement를 적용하여(0과 1 반전) 구한 값을 checksum에 기록한다.
UDP receiver에선 이 checksum과 원래 segment가 가지고 있던 2개의 16bit word를 합쳐서 1111111111111111가 되는지 확인한다. 만약 하나의 bit라도 0이라면 우린 packet 전송과정에서 에러가 있었음을 알 수 있다.
Weak protection

Bonus : Why not 2s' complement?
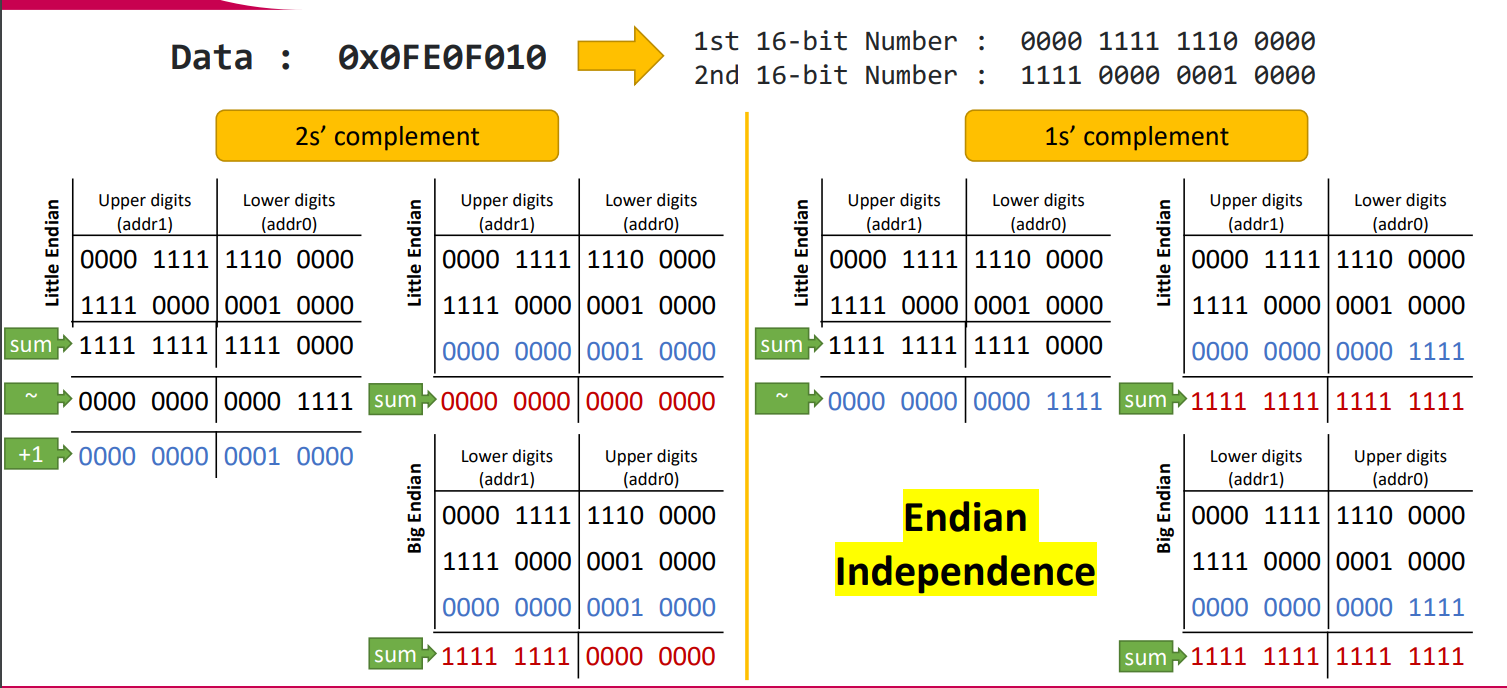
그렇다면 왜 2s complement를 이용하지 않는걸까?
예를 들어 0x0FE0F010라는 데이터가 있다. 이를 16bit씩 쪼개어, 2개의 수를 만들었다고 보자. 2s complement를 사용할 경우 negation을 취한 뒤 1을 더해주는 과정이 들어가는데, 이때 little endian 방식과 big endian 방식에서 checksum이 달라지게 된다. 반면 1s complement의 경우 endian에 관계 없이 같은 값이 나와, os마다 다른 endian 방식을 따라도 문제가 되지 않는 1s complement 방식이 채택된 것이다.
Bonus : Is UDP/TCP checksum invariant?
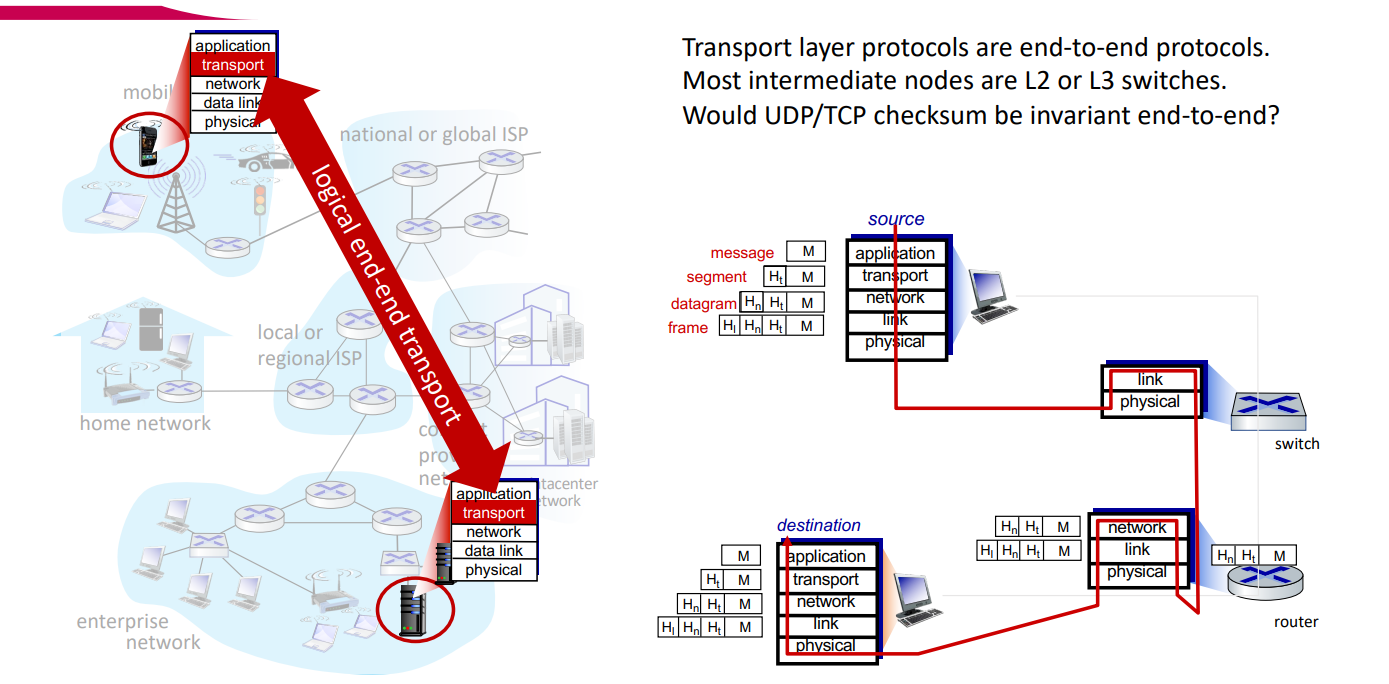
그렇다면 UDP/TCP의 checksum은 invariant일까? Transport layer protocol은 end-to-end protocol이기 때문에 많은 L2/L3 switch들을 지나게 된다. 과연 end-to-end protocol동안 checksum은 불변값이어야 할까?
답은 "아니다"이다. 전송 과정에서 payload가 바뀌지는 않으나, 이 과정에서 header에 변형이 일어나 port가 바뀔 수 있고, 특히 NAT 공유기의 경우 통신사에 따라 IP address가 다를 수 있다. 따라서 UDP header와 IP header가 모두 바뀔 수 있기에 checksum도 변할 수 있다.
summary: UDP
- no frills protocol
- segment는 도중에 잃어버릴 수 있고, out of order로 전송될 수 있다.
- best effort service : 단순히 전달 후 best이길 기도하는 것.
- UDP has it plusses
- 별도의 setup/handshaking이 필요하지 않아 이로 인한 RTT가 발생하지 않음.
- 네트워크 서비스가 혼잡해서 정상적으로 동작하지 않아도 작동할 수 있음.
- checksum으로 조금의 reliability를 제공할 수 있음.
- UDP application layer 위에 추가적으로 functionality를 더할 수 있음. (HTTP/3)
