- Transport-layer services
- Multiplexing & demultiplexing
- Connectionless transport: UDP
- Principles of reliable data transfer
- Connection-oriented transport: TCP
- Principles of congestion control
- TCP congestion control
- Evolution of transport layer funcitonality
Principle of reliable data transfer
Principle of reliable data transfer
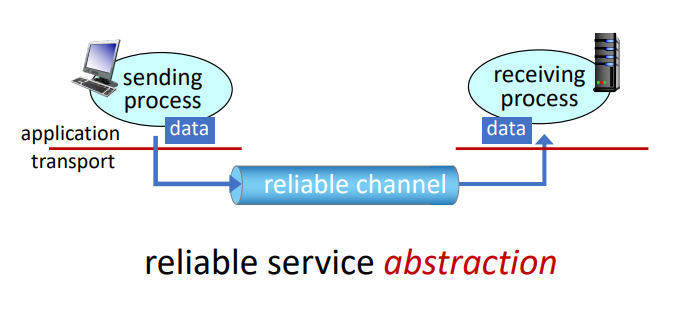
위 그림은 reliable data transfer의 프레임워크를 나타내고 있다. Service abstraction은 상위 계층인 application layer에게 데이터 전송 과정이 신뢰할 수 있는 채널을 통해 이루어지게 한다. 따라서 데이터들은 corrupt되지 않아야 하며 (bit flip) lost가 발생하지 않고, 원래 순서에 맞게 전송되어야 한다. TCP service도 이러한 모델을 제공한다.
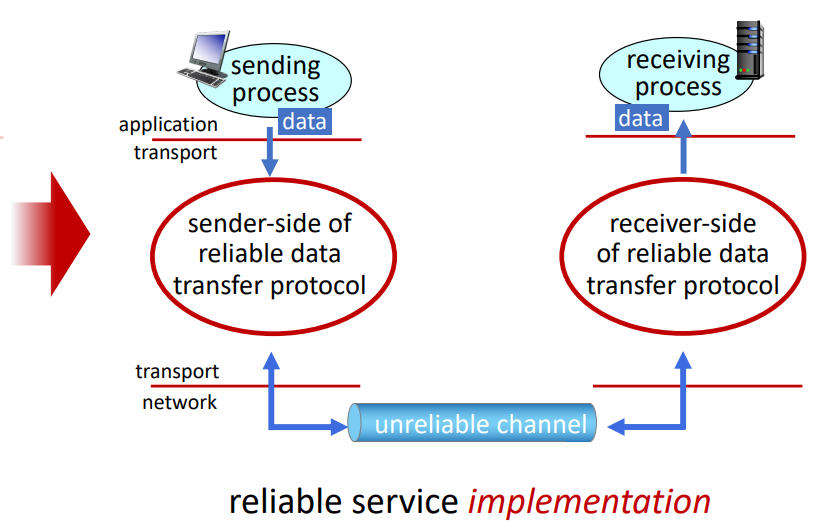
이를 위해, reliable data transfer protocol에서 이 abstranction이 가능하게 구현을 해야 한다. 이 부분이 어려운 이유는 transport layer 하위의 network layer가 unreliable하기 때문이다. 예를 들어, TCP는 reliable data transfer protocol이지만 unreliable한 (IP) end-to-end network layer 위에 구현되어있다.
Unreliable한 channel 외에도, sender와 receiver는 서로의 state를 알 수 없기에 어려움이 있다. 전송이 제대로 이루어졌는지, 어떤 문제인지 메세지를 주고 받지 않으면 알 수 없다.
Reliable data transfer protocol (Rdt) : interfaces
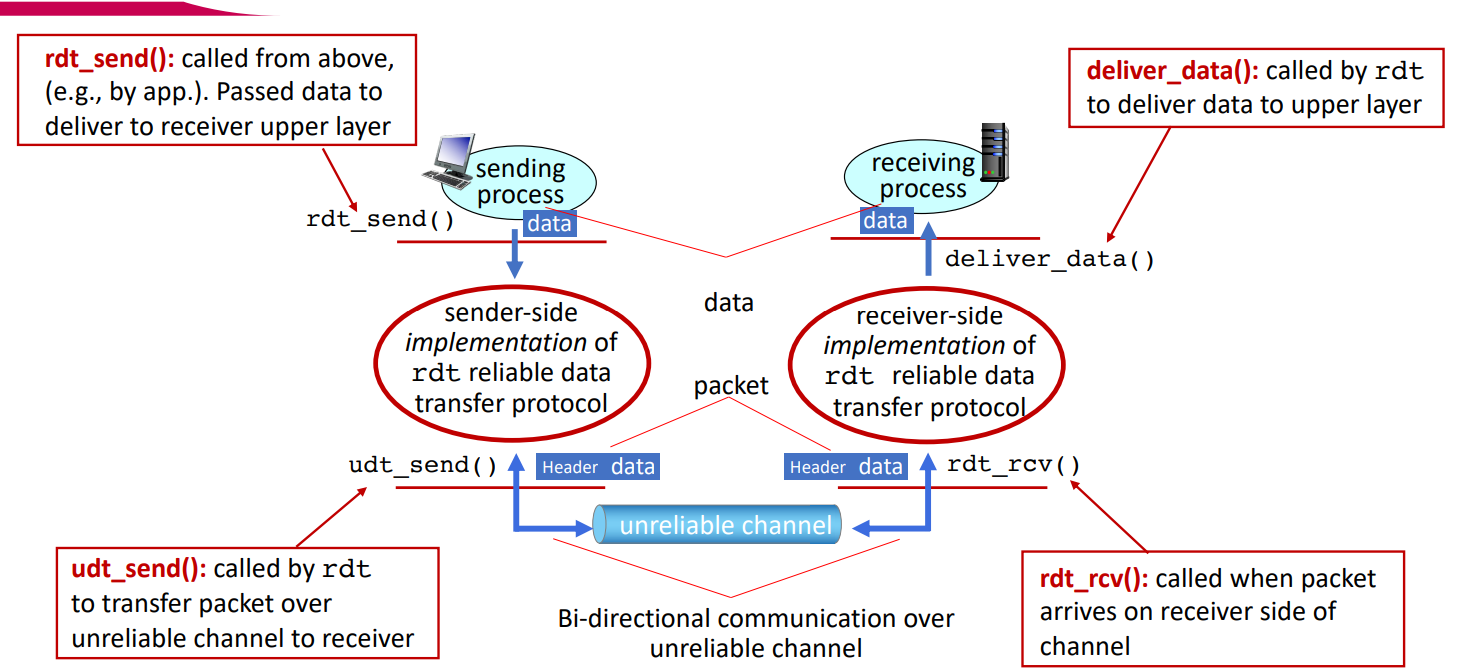
- rdt_send : sender application layer -> transport layer data 전달
- udt_send : sender transport layer -> unreliable channel packet 전달
- rdt_rcv : receiver unreliable channel -> transport layer packet 수신
- deliever_data : receiver transport layer -> application layer data 전달
Reliable data transfer
지금부터 reliable data transfer protocol의 sender & receiver 동작을 순차적으로 발전시키며 이해해보자.
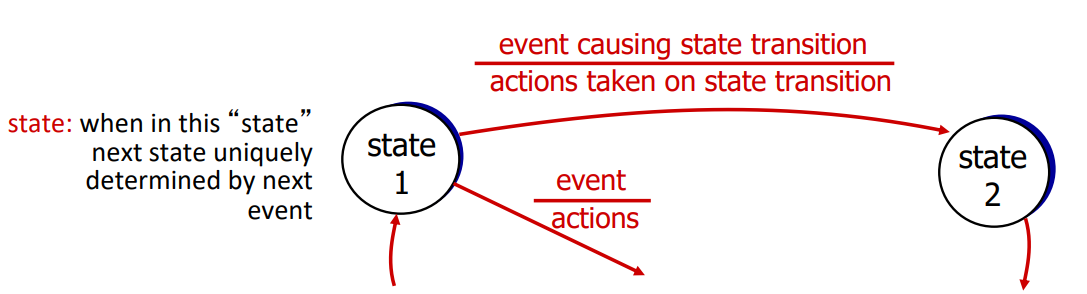
지금부터 표현되는 FSM은 위 그림의 방식으로 표현되어 있다. (State, event, action)
#1 RDT 1.0
RDT 1.0 : Reliable transfer over a reliable channel
- 이 경우는 완전히 신뢰할 수 있는 채널 위에서 동작하는 상황으로, bit error나 packet loss가 없는 경우다.
- 이땐 sender와 receiver의 FSM이 분리되어 있다.
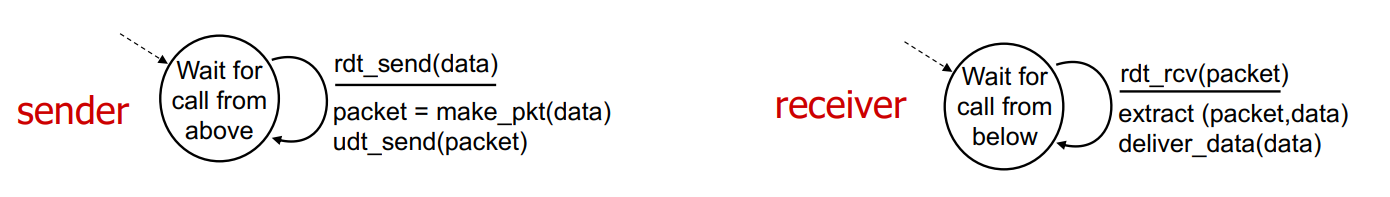
Sender가 상위 계층으로부터 호출을 기다린다. rdt_send를 통해 데이터가 들어오는 이벤트가 발생하면, packet을 만들고 udt_send를 통해 보낸다. Receiver는 하위 계층으로부터 호출을 기다린다. rdt_rcv를 통해 packet이 들어오는 이벤트가 발생하면, packet으로부터 데이터를 추출해 deliver_data를 통해 보낸다.
#2 RDT 2.0
RDT 2.0 : Channel with bit errors
이제부턴 하위 채널에서 bit flip이 발생할 수 있는 상황으로, checksum을 이용해 bit error를 감지할 수 있다. 만약 에러가 발생하였다면 어떻게 회복해야 할까?
- acknowledgements (ACKs) : Receiver가 sender에게 수신한 packet이 괜찮음을 직접적으로 명시하는 것
- negative acknowledgements (NAKs) : Receiver가 sender에게 수신한 packet에 에러가 있음을 직접적으로 명시하는 것.
- Sender는 NAK을 수신하면 packet을 retransmit한다.
RDT 2.0은 stop and wait 매커니즘을 따르며, sender가 하나의 packet을 보내면 receiver가 response를 보내기를 기다리는 방식이다.
RDT 2.0 : FSM specifications
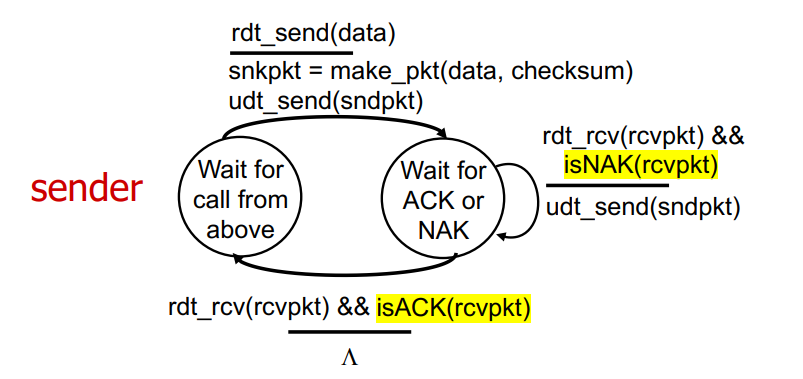
위 그림은 sender의 fsm이다.
Sender는 상위 계층으로부터 호출이 오길 기다리고 있었다. 이때 rdt_send를 통해 데이터가 들어오는 이벤트가 발생하고, 이에 따라 data와 checksum을 이용해 packet을 만들어 udt_send로 보낸다. Sender는 전송 후 ACK, NAK의 정보를 기다리는 상태가 되고, receiver가 packet을 받고난 뒤 에러가 발생했다는 뜻인 NAK을 보내면 무한 retransmit을, ACK을 보내면 정상적으로 보냈음을 알고 상위 계층의 호출을 기다리는 상태로 돌아온다.
- Receiver의 state는 sender로 메세지를 보내지 않는 이상 알 수 없음.
- Sender가 정상 수신을 받을 때까지 buffering이 발생하는 것이 특징.
RDT 2.0 : operation with no errors
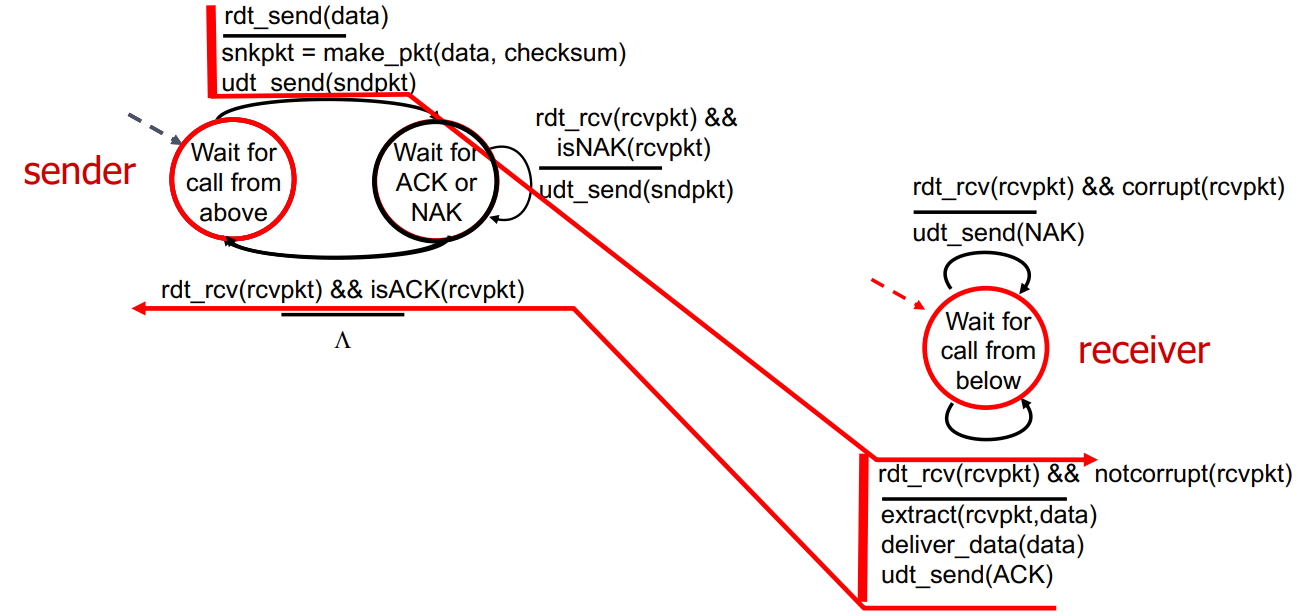
에러가 발생하지 않는 경우 위 그림처럼 동작한다.
Sender에서 data를 받아 packet으로 보내면, receiver에서 checksum을 통해 notcorrupt임을 인지하고 packet에서 data를 추출하고 sender로 ACK을 보낸다. ACK을 받은 sender는 초기 상태로 돌아간다.
RDT 2.0 : corrupted packet scenario
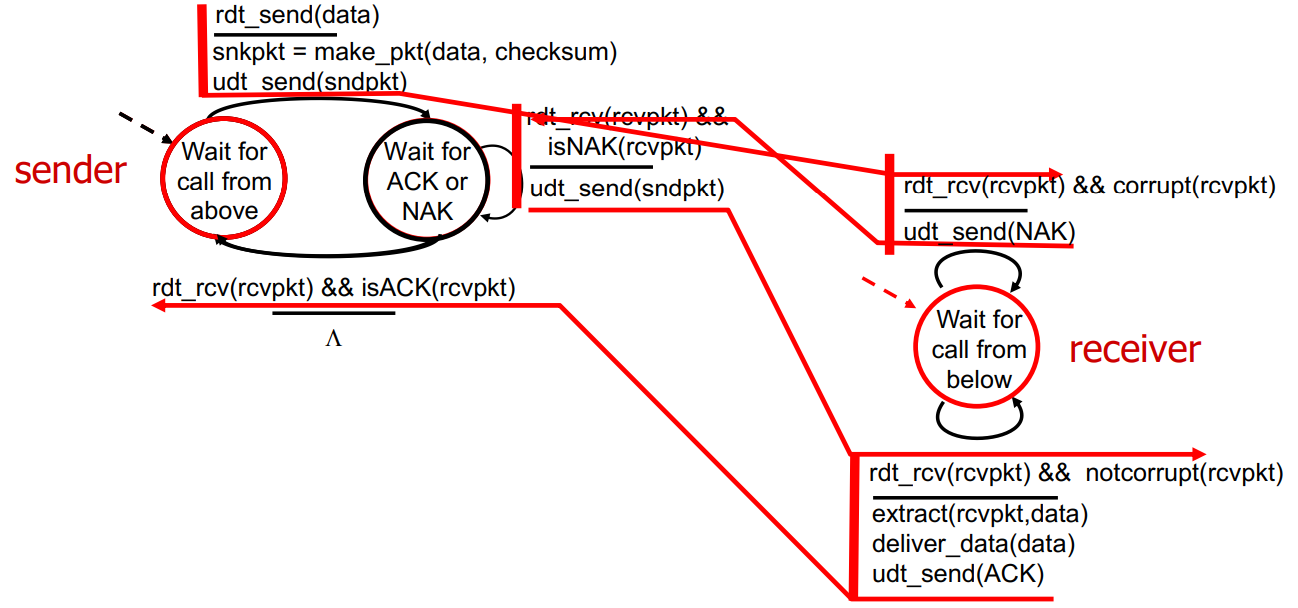
packet corrupt가 발생한 경우 위 그림처럼 동작하낟.
Sender에서 data를 받아 packet으로 보낸다. Receiver에서 checksum을 통해 corrupt임을 인지하고 NAK을 sender로 보낸다. NAK을 받은 sender는 retransmit을 진행하고, receiver가 not corrupt라면 ACK을 다시 sender에 보내 초기 상태로 돌아간다.
+) 이는 TCP에 해당되는 것이고, UDP에도 checksum이 있지만 error를 인지해도 별 다른 행동 없이 application에 알리기만 한다.
RDT 2.0's fatal flaw
RDT 2.0은 모두 ACK과 NAK을 기반으로 동작하고 있으나, 만약 ACK과 NAK이 corrupt되면 어떻게 할까? Sender는 receiver에서 무슨 동작이 일어났는지 알 수 없고, 단순히 retransmit을 시키는 것은 duplicate packet이 될 수 있다.
Packet이 중복으로 수신될 경우, receiver 측에선 새로운 packet을 받을 필요가 없어 단순히 폐기되고 이는 대역폭을 낭비가 된다. 또한, receiver 측에서 중복 수신이 손상된 packet에 의한 것으로 오해하여 retransmit을 또 시도할 수도 있어 문제가 된다.
이를 방지하고자, sender는 ACK/NAK이 corrupt 되었을 때 현재 packet을 retransmit하고, 각 packet에 sequence number를 부여해 중복을 감지할 수 있게 해야 한다. Receiver는 duplicate packet임을 인지하면 이를 폐기하게 되는 방식으로 진행한다.
#3 RDT 2.1
RDT 2.1부터는 sequence number의 활용이 핵심이다.
RDT 2.1 : Sender, handling garbled ACK/NAKs
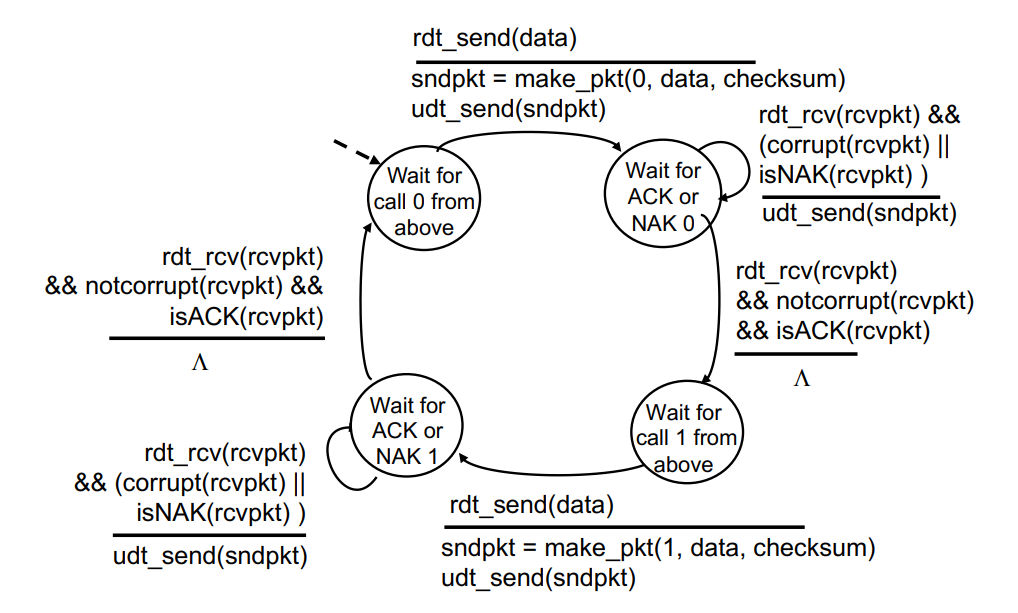
- Wait for call 0 from above (0번 sequence number)
1-1. data -> packet with 0, data, checksum -> send - Wait for ACK or NAK with 0
2-1. receive packet that corrupt or NAK -> retransmit
2-2. receive packet that notcorrupt and ACK - Wait for call 1 from above (1번 sequence number)
3-1. data -> packet with 1, data, checksum -> send - Wait for ACK or NAK with 1
4-1. receive packet that corrupt or NAK -> retransmit
4-2. receive packet that notcorrupt and ACK
여기서 sequence number는 0 / 1 둘 중 하나.
RDT 2.1 : Receiver, handling garbled ACK/NAKs
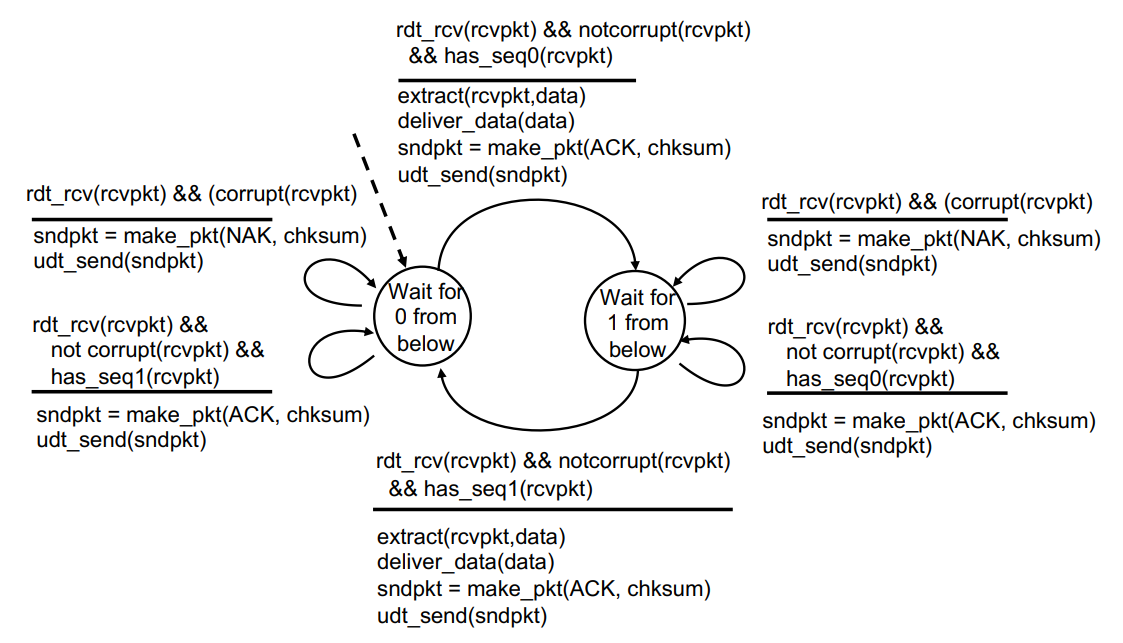
- Wait for 0 from below
1-1. receive packet with corrupt -> send packet with NAK, checksum
1-2. receive packet notcorrupt but sequence number 1 -> send packet with ACK, checksum (duplicate, discard)
1-3. receive packet notcorrupt and sequence number 0 -> extract data from packet -> send packet with ACK, checksum - Wait for 1 from below
2-1. receive packet with corrupt -> send packet with NAK, checksum
2-2. receive packet notcorrupt but sequence number 0 -> send packet with ACK, checksum (duplicate, discard)
2-3. receive packet notcorrupt and sequence number 1 -> extract data from packet -> send packet with ACK, checksum
RDT 2.1 : discussion
- Sender
- Packet에 sequence number 추가
- 두 개의 sequence number (0,1)로 충분
- 받은 ACK/NAK이 corrupt된 건지 반드시 확인
- 이전에 비해 2배로 늘어난 state
- state는 받을 것으로 기대되는 packet이 seq #가 0인지 1인지 반드시 기억
- Receiver
- 받은 packet이 duplicate인지 반드시 확인
- state 자체가 받을 것으로 기대되는 seq #가 0인지 1인지 표현
- receiver는 자신이 가장 최근에 보낸 ACK/NAK이 sender에서 괜찮은지 알 수 없음
- 받은 packet이 duplicate인지 반드시 확인
#4 RDT 2.2
RDT 2.2 : a NAK-free protocol
RDT 2.2는 2.1과 같은 functionality를 가지지만 ACK만을 사용한다는특징이 있다. NAK을 사용하지 않고 receiver가 packet을 정상적으로 수신했을 때만 ACK을 전송하며, 이때 ACK된 packet의 sequence number를 직접적으로 명시한다. Duplicate ACK 또한 NAK과 같이 처리되며, retransmit으로 해결된다. TCP는 이 방식을 통해 NAK-free를 얻었다.
RDT 2.2 : sender, receiver fragments
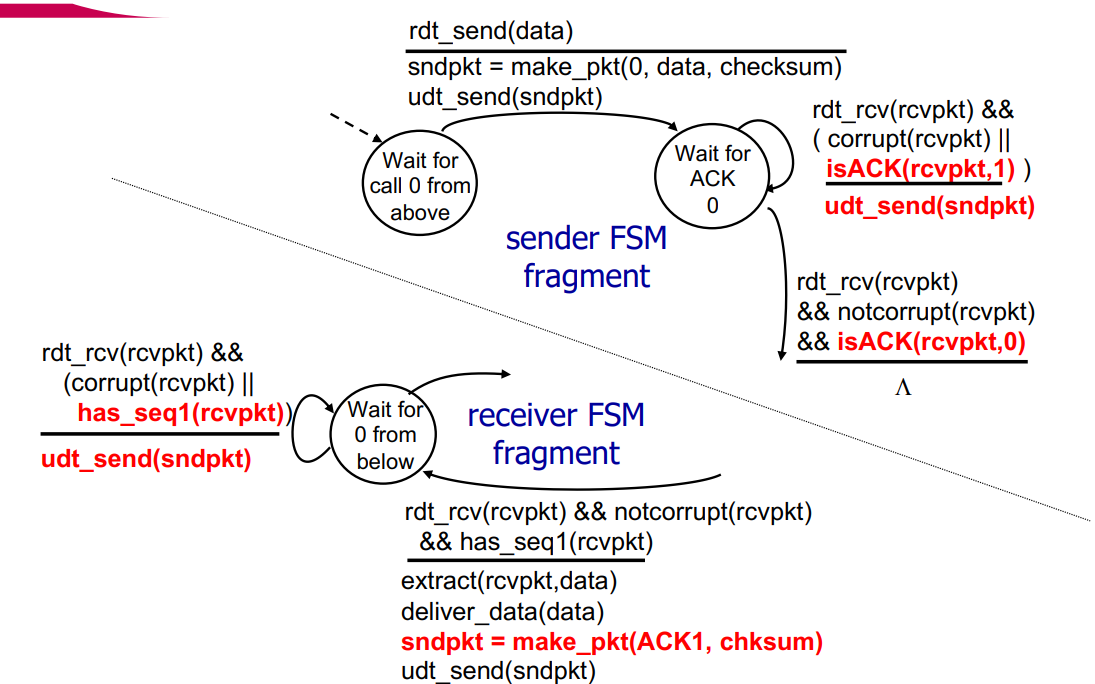
이 그림은 2.1에서 바뀐 부분만 표현되어 있다.
Sender를 보면 sequence number 0을 기다리고 있을 때 ACK이 1과 함께 온 상황을 NAK 대신에 사용하였고, 정상 수신은 ACK과 0이 함께인 상황으로 구별하였다.

Receiver의 경우 RDT 2.1의 FSM을 보면 sender의 retransmit이 필요한 경우가 corrupt되거나 / corrupt는 아닌데 sequence number가 다른 2가지 시나리오가 있었다. 하지만 NAK을사용하지 않게 되며, 어떤 종류의 에러인지 sender에게 구분할 필요가 없어져 새로운 packet을 만들지 않고 기존에 만들었던 ACK1이 포함된 packet을 재전송하는 방식이 되었다.
#5 RDT 3.0
RDT 3.0 : channels with errors and loss
이제 RDT 3.0은 bit error와 packet(data, ACKs) loss가 모두 발생하는 상황을 포함하게 되었다. 우리가 이전에 사용하던 checksum, sequence #, ACK, retransmission 기법들은 도움이 되긴 하나 충분한 해결책이 아니었다.
이를 해결하기 위해 sender가 ACK의 인식을 합리적인 시간 동안만 기다리고 시간 초과시 재전송하는 time-based retransmission을 따르게 되었다.
- 만약 packet 혹은 ACK이 lost되진 않았는데 그저 지연되고 있다면, duplicate retransmission이 될 수 있지만 이 부분은 sequence number로 해결 가능하다.
- receiver는 ACK가 완료된 packet의 sequence number를 명시해야 한다.
- countdown timer를 구현해서 합리적인 시간을 지나가는지 확인해야 한다.
RDT 3.0 sender
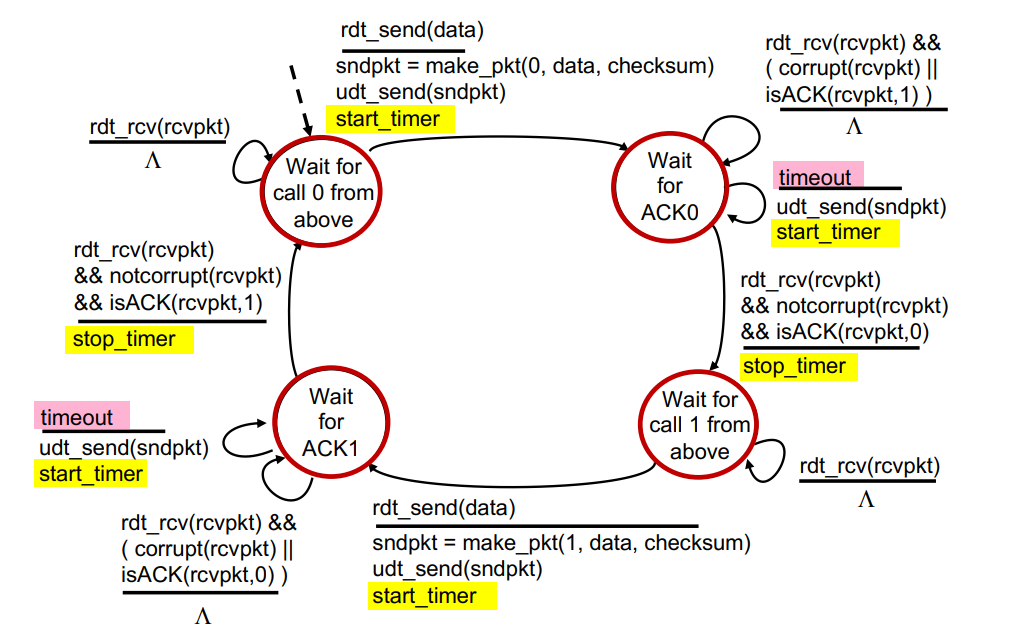
- Wait for call 0 from above
1-1. data -> send packet with 0, data, checksum -> start timer - Wait for ACK 0
2-1. receive packet corrupt or ACK 1 -> nothing
2-2. Just timeout -> retransmit -> start timer
2-3. receive packet not corrupt and ACK 0 -> stop timer
(절반만 서술)
RDT 3.0 in action
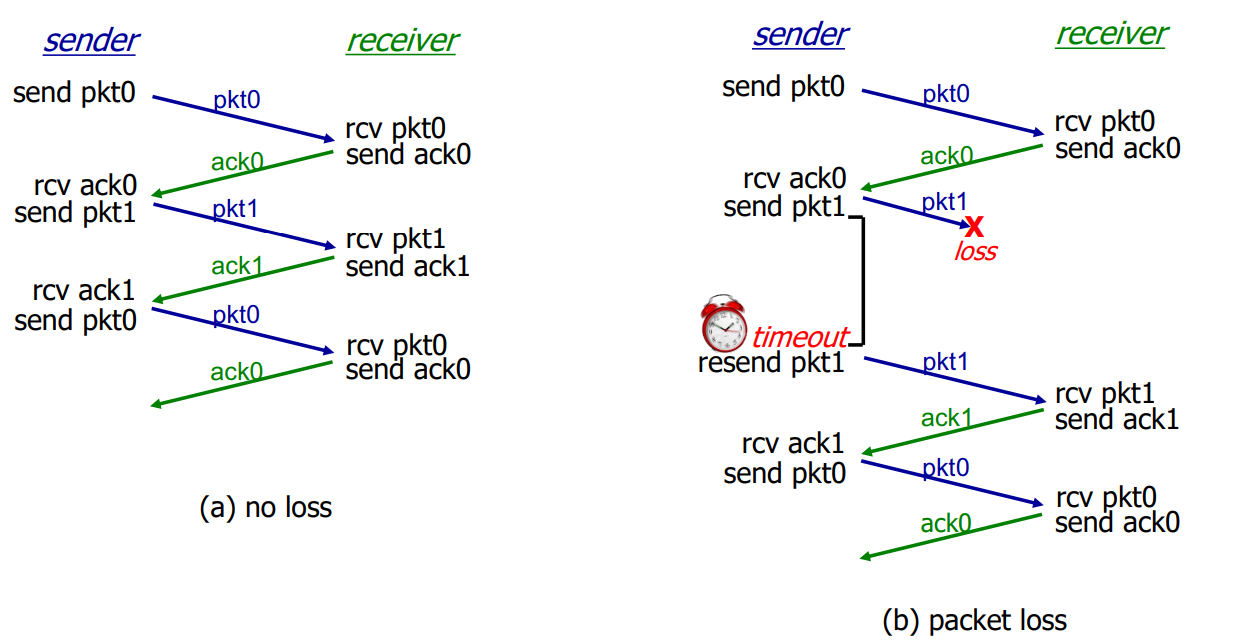
Loss가 없으면 각 sequence number에 대해 packet을 보내고 ack을 받는 것으로 진행된다. 하지만 packet loss가 발생한 경우엔, sender 측에서 아무런 행동을 하지 않고 sender에서 timeout이 발생될때까지 기다린 후, retransmit을 하는 방식으로 진행된다.
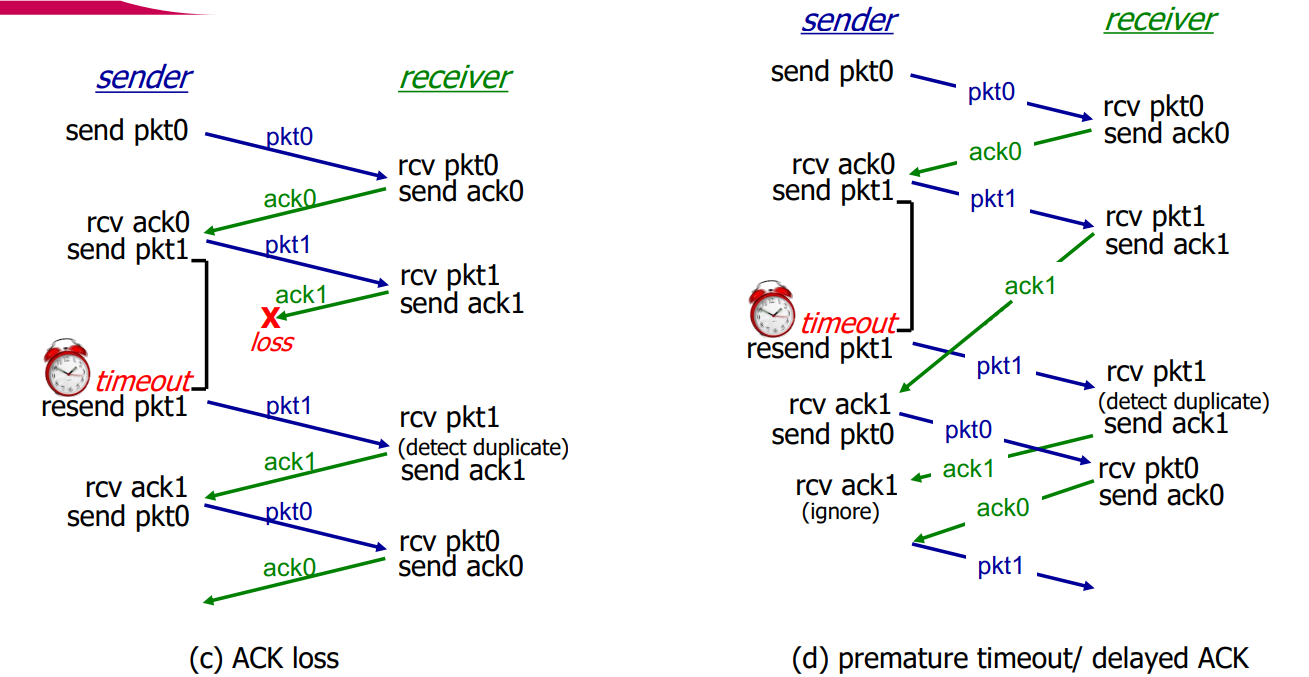
ACK loss의 경우에도 receiver 측에서 성공적으로 전송되었는지 모르기에 sender가 timeout이 발생할때까지 기다린 후 ack이 되지 않았던 packet 1을 retransmit 한다. Receiver는 duplicate임을 인지하고 다시 ack을 보내게 된다.
Premature timeout이나 delayed ACK의 경우 ack이 정상적으로 이루어졌는데 timeout이 먼저 발생해버려서 duplicate을 retranmit하게 된다. 그러면 receiver는 duplicate임을 인지한 후 ack을 보내는데, 이미 sender에선 해당 ack을 받았었기에 무시해버리게 된다.
RDT 3.0 performance (stop and wait)
- Usender : utilization - fraction of time sender busy sending
Utilization은 성능을 표현하는 대표적인 지표 중 하나다. 지금부터 RDT 3.0의 퍼포먼스를 stop and wait 방식을 기준으로 계산해보겠다.
+) recap : 이전 network layer의 traffic intensity라는 개념을 이용해 utilization을 계산했던 적이 있다.
- example : 1 Gbps link, 15ms prop. delay, 8000bit packet
- 여기서 L = 8000bit, R = 1Gps
- Dtrans = L / R = 8000 bits / 109 (bits/sec) = 8 microsecs
- 즉 여기서 transmit delay는 8 microsec이다.
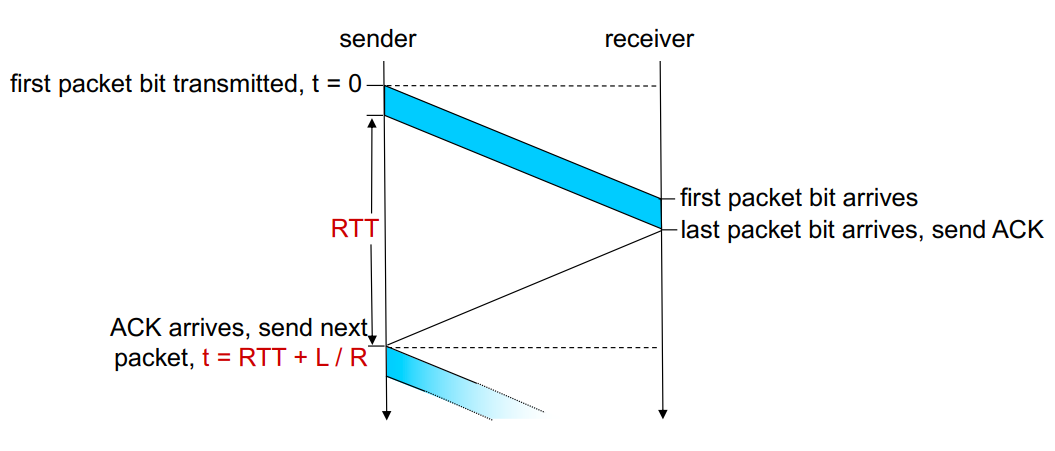
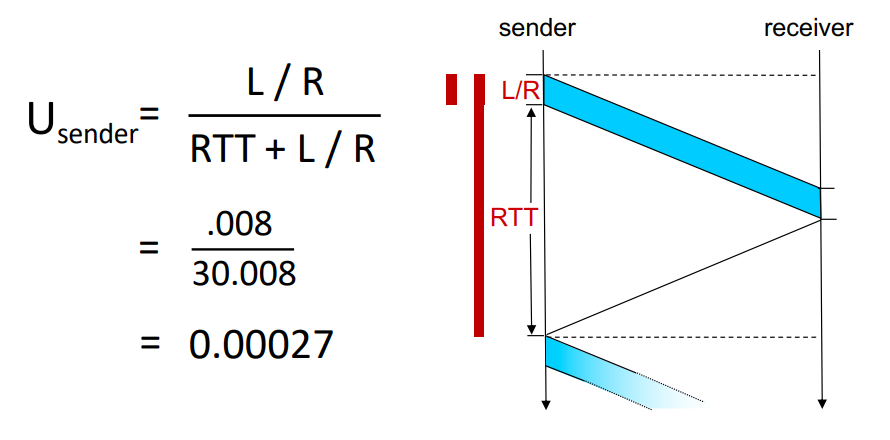
먼저 sender가 transmit하는데 8msec가 걸리고, receiver는 모든 packet이 transmit 된 후에 ACK을 보내게 된다.
- 패킷이 출발지에서 목적지까지 갔다가 다시 출발지로 돌아와서 걸리는 시간 = RTT (Round Trip Time)
Sender 입장에서 packet을 보내고 ACK을 받기 까진, RTT + transmit delay의 시간이 소요된다. 이상적인 상황에선 RTT = 2 * propagation delay 이므로 30msec가 RTT임을 알 수 있다.
최종적으로 알게된 sender의 utilization은 끔찍한 값을 가지고 있따. 따라서 이를 개선하기 위해 pipelining을 도입하게 되었다.
Pipelining: increased utilization
Pipelining을 통해 sender는 아직 acknowledge가 않은 packet들을여러개 보낼 수 있게되며, 이를 위해 sequence number도 증가하고, sender와 receiver 모두에서 buffering이 발생하게된다.
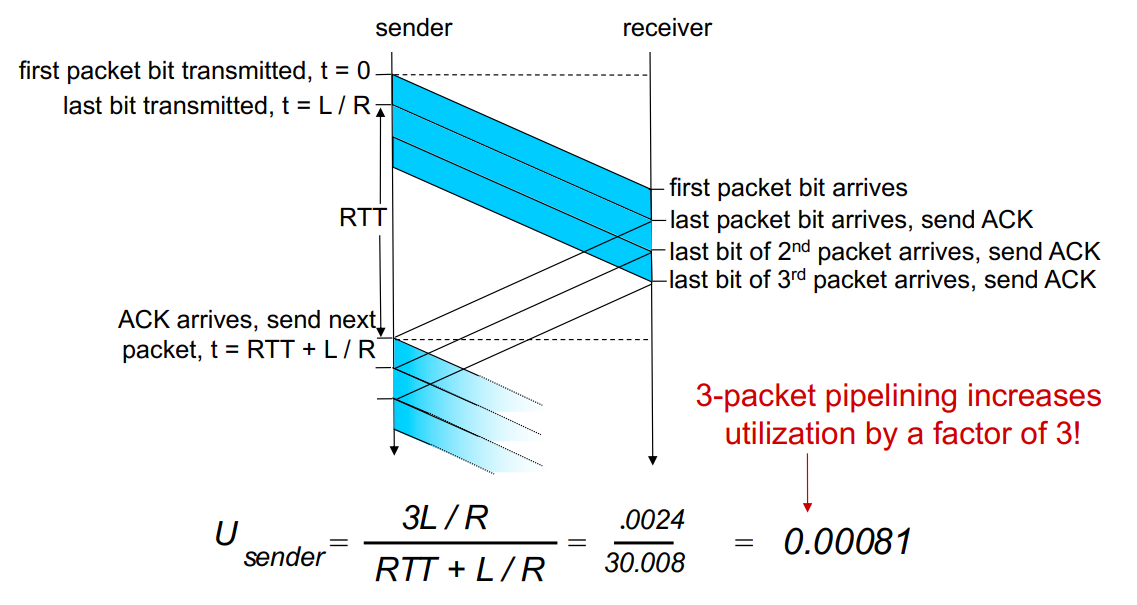
위 그림에서 보이듯이 3개의 packet을 연속해서 보낼 수 있게 된다.
- transmission delay : 3L/R
- RTT는 그대로
- Utilization sender는 첫 번째 packet을 보내서 ack이 될때까지 이므로, (3L/R) / (RTT + L/R)이 되어 utilization이 3배가 된다.
Pipelining 기법을 사용하게 되었을 때, packet loss나 delay가 발생하는 상황을 처리하기 위해 Go-back-N 기법, 혹은 selective repeat 기법을 사용할 수 있다.
Go-Back-N
Go-Back-N : Sender
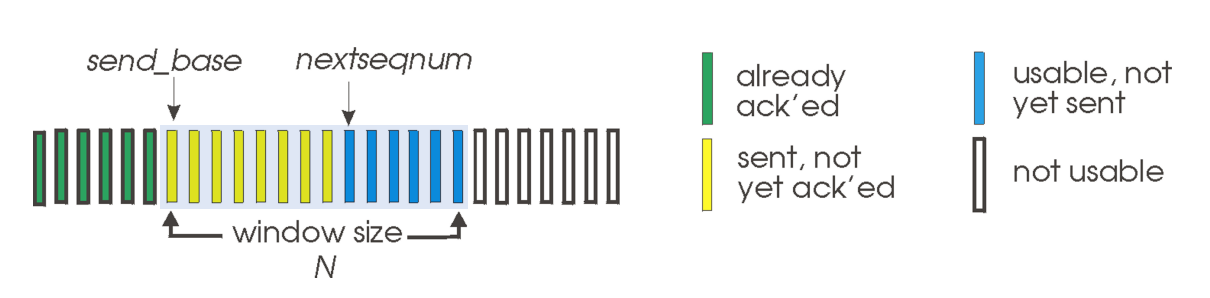
Pipelining을 하게 되면서 여러 개의 acknowledge 되지 않은 packet들을 연속해서 보낼 수 있게 되었다. 이때 보낼 수 있는 개수를 window라 하며, 그 크기는 최대 N이라하자.
- cumulative ACK ( ACK(n) ) : 데이터 전송 시 전송한 패킷에 대한 ACK를 받으면 그 이전에 전송한 모든 패킷이 제대로 도착했다는 가정을 하고 다음 패킷을 보내는 방식
- timer for oldes in-flight packet
- timeout(n) : packet n부터 window 범위 내이며 더 높은 sequence number를 가지는 모든 packet들을 재전송
Go-Back-N : Receiver
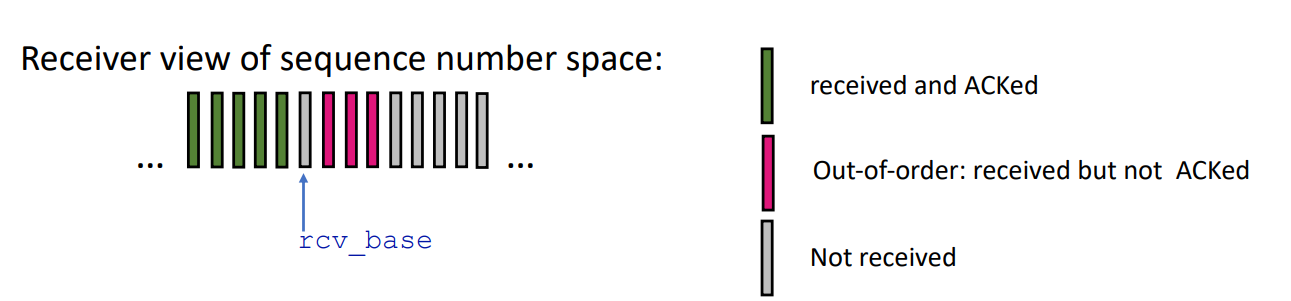
-
ACK-only : ACK을 올바르게 수신된 packet들에 한해 전송하며, 이때 가장 높은 in-order sequence #에 맞춰 전송한다.
-
예를 들어 OOOOXXOO 이렇게 된 상황이면, 연속적으로 올바르게 수신된 가장 마지막 번호는 4번이므로 (cummulative) ACK이 4가 된다.
-
이로 인해 duplicate ACK이 발생할 수 있다.
-
rcv_base만 기억하면 된다.
rcv_base?receiver가 패킷을 받으면, 이 패킷의 sequence number와 rcv_base를 비교합니다. 만약 sequence number가 rcv_base와 같거나 그보다 크다면, 이 패킷은 이미 도착한 패킷들 중 가장 마지막에 도착한 패킷 이후에 도착한 패킷이므로, 정상적으로 처리합니다. 이때 rcv_base는 새로 도착한 패킷의 sequence number + 1로 업데이트됩니다.하지만, 패킷이 중복 전송되어서, sequence number가 rcv_base보다 작은 패킷이 도착할 경우, 이 패킷은 이미 처리된 패킷과 중복되는 패킷이므로, ACK를 다시 전송합니다. 이때 rcv_base는 업데이트되지 않습니다. 따라서 receiver는 rcv_base만 기억해도 중복 ACK를 방지하고, 패킷의 정확한 순서를 파악할 수 있습니다.
-
-
out of order packet을 수신한 경우
- buffering 없이 discard or buffering 할 수 있다. (구현방법차이)
- 가장 높은 in-order seq #로 re-ACK을 진행한다.
Go-Back-N in action
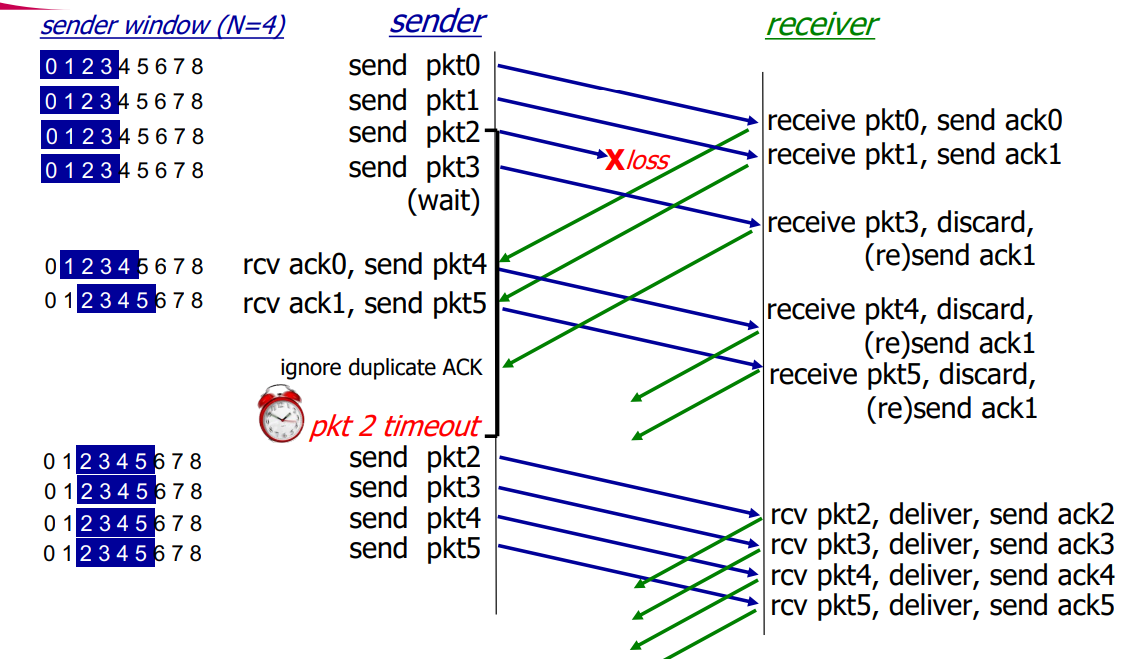
이 문제는 일단 window 크기가 최대 4개이다.
0 전송 -> ack 0
1 전송 -> ack 1
2 전송 과정에서 loss
3 전송 -> recv_base는 2인데 3이 들어옴. discard. ack 1 (구현방식이 discard)
(window 크기가 4이기 때문에 ack이 오길 기다림)
ack 0 받음 4 전송 -> recv_base는 2인데 4가 들어옴. discard. ack 1
ack 1 받음 5 전송 -> recv_base는 2인데 5가 들어옴. discard. ack 1
(window 크기가 4이기 때문에 ack이 오길 기다림)
(근데 이미 ack1을 받았는데 계속 들어와서 무시. inflight 개수가 안 줄어듬)
(ack이 되지 않은 가장 빠른 packet 2로 인해 timeout이 일어남을 인지)
2 전송 -> ...
Selective repeat
앞서 Go-Back-N의 경우엔 ack이 되지 않은 가장 빠른 번호부터 그 뒤로 쭉 retransmit하는 방식이었다면, selective repeat의 경우엔 문제가 되는 애만 retransmit하는 것이다.
- receiver가 개별적으로 올바르게 수신된 packet들을 acknowledge한다. (cummulative 방식이 아니라는 것)
- packet을 필요한 만큼 buffer해서 in-order delivery가 되게 한다.
- sender가 timeout/retransmit이 unACKed packet들에 대해 개별적으로 이루어진다.
- sender가 각각의 unacked packet에 대해 timer를 관리해야한다.
- sender window
- N개의 연속되는 sequence number들로 구성된다.
- 전송되거나 unack이 될 수 있는 packet의 수를 제한한다.
Selective repeat : sender, receiver windows
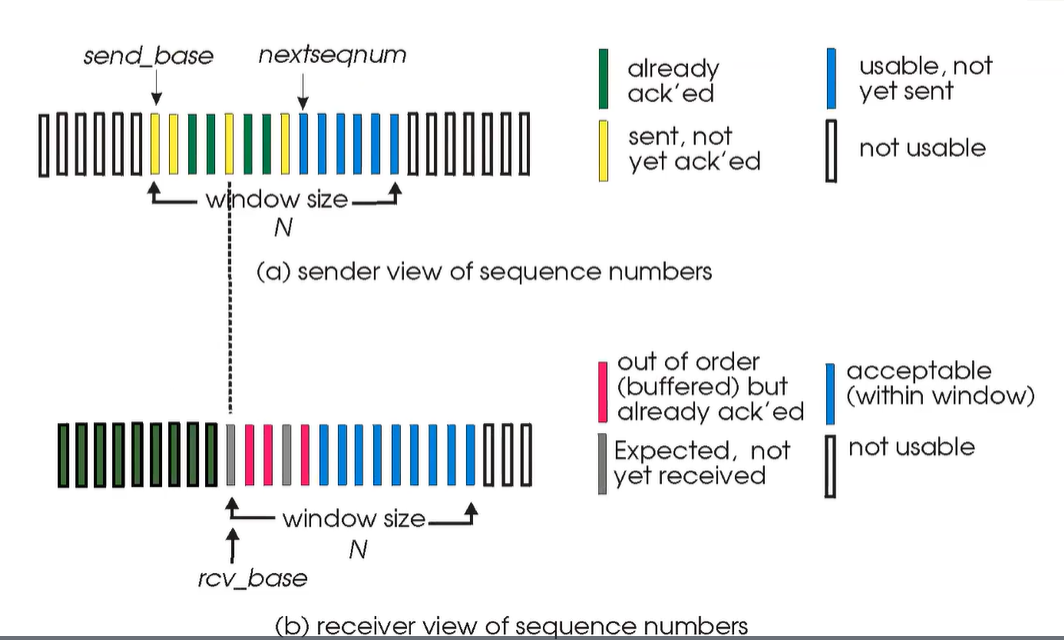
Sender는 send_base부터 N개의 연속되는 sequence number들을 window로 가진다. ? 모야 이게
Selective repeat : sender and receiver
- Sender의 event와 action
- data from above
- 만약 window 내에 가능한 sequence number가 있다면 보낸다.
- window 범위를 초과할경우 buffer / return to upper layer
- timeout(n)
- 각 packet에 따라 존재하므로 resend packet n, restart timer
- ACK received
- ACK(n) in [sendbase, sendbase + N]
- packet n을 수신하였음을 표시한다.
- 만약 packet n이 send_base와 동일하면 window를 smallest unACKed packet으로 이동시킨다.
- data from above
- Receiver의 event와 action
- Packet n in [rcvbase, rcvbase + N - 1] - 윈도우 범위
- 수신한 packet이 receiver의 window 범위 내이므로 ACK(n)을 보낸다.
- 만약 packet이 처음으로 수신된 거라면 buffer에 넣는다.
- 만약 packet이 rcv_base와 같다면 이 packet을 포함해 이전에 수신되어 buffer에 존재하는 모든 packet을 upper layer로 보낸다.
- 그 후 아직 receive되지 않은 packet으로 window 이동.
- packet n in [rcvbase-N, rcvbase-1] - 윈도우 이전 범위
- 이 경우 ACK(n)이 보내지며, 중복 수신이더라도 똑같이 행동.
- otherwise
- packet을 무시한다.
- Packet n in [rcvbase, rcvbase + N - 1] - 윈도우 범위
Selective Repeat in action
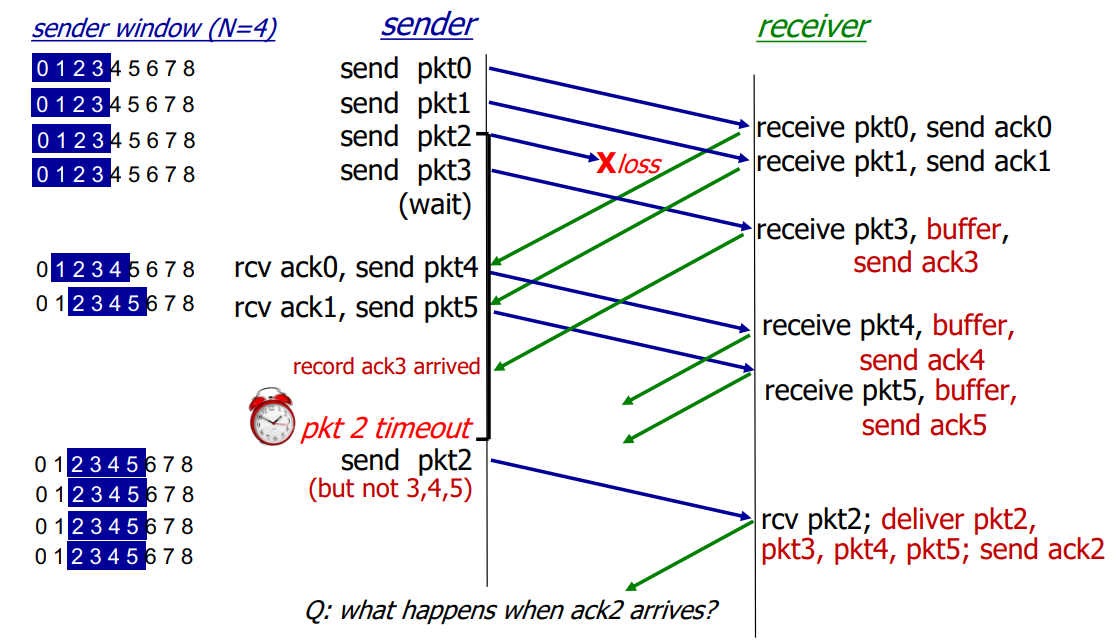
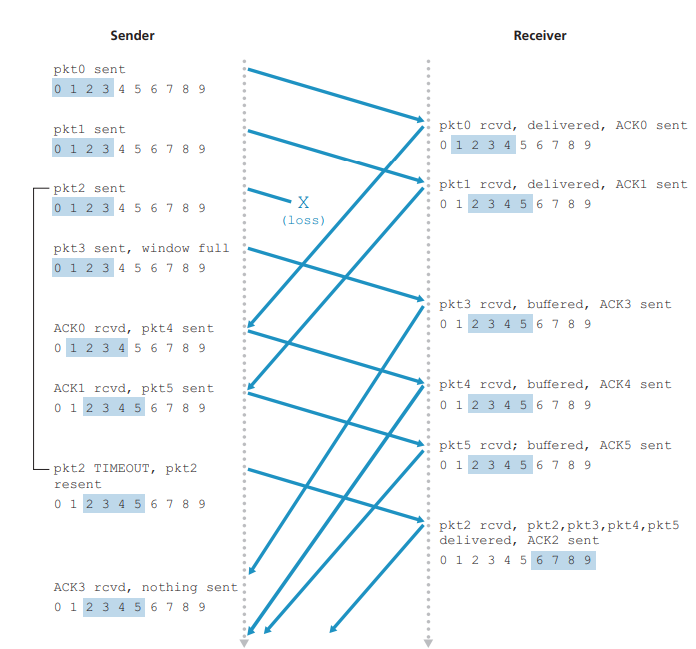
(같은 내용. 일부러 가져옴)
윈도우 크기 4
0 전송 -> 0 수신. deliver. ack 0 (0이 buffer에 들어가도 base랑 같아서 바로 deliever)
1 전송 -> 1 수신. ack 1
2 전송 -> loss
3 전송 -> 3 수신. buffer. ack 3
(max 도달, 윈도우 크기 때문에 기다림)
ack 0 수신 4 전송 -> 4 수신. buffer. ack 4
ack 1 수신 5 전송 -> 5 수신. buffer. ack 5
(ack 3을 수신)
(2번 packet을 수신하지 못해서 윈도우 크기 때문에 더 진행 못함)
(2번 packet의 timer timeout)
2 전송 -> 2 수신. deliver 2,3,4,5. ack 2 (2가 buffer에 들어가는 순간 base랑 같아져 2 이전에 들어와있던 모든 버퍼에 있던 값 전송)
(ack 4 수신)
(ack 5 수신)
ack 2 수신 6 전송 -> ... (2번 packet을 수신하는 순간 가장 작은 unACKed packet으로 이동하게 되는데, 이게 6번임)
Selective Repeat dilema
그러나 selective repeat 방식은 딜레마가 존재한다.
예를 들어, sequence number가 0, 1, 2, 3 이라 하자. (4개 base counting) 이때 윈도우 크기가 3이다.
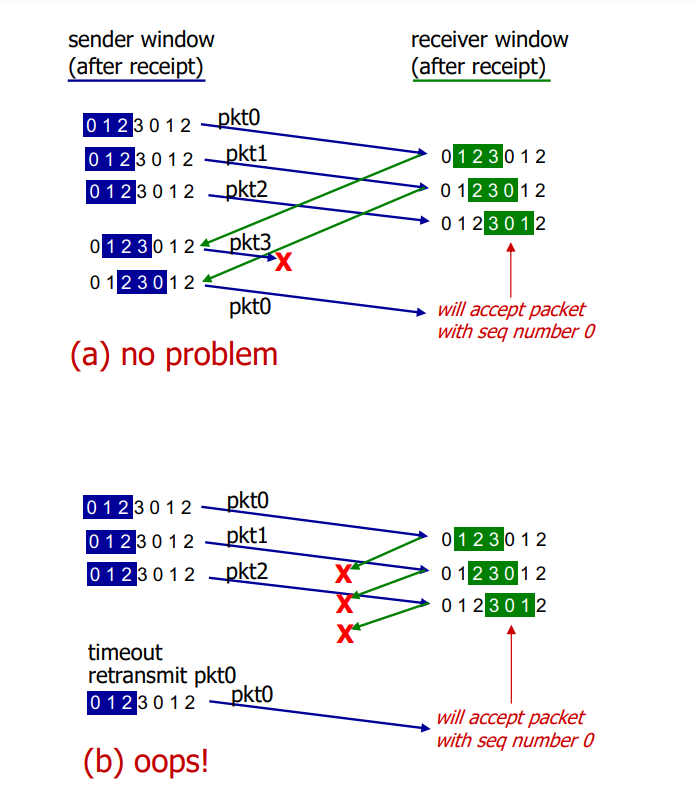
(a) 설명
0 전송 -> 0 수신. deliver. ack 0
1 전송 -> 1 수신. deliver. ack 1
2 전송 -> 2 수신. deliver. ack 2
ack 0 수신. 3 전송 -> loss
ack 1 수신. 0 전송 -> 0 수신. deliver. ack 0
이처럼 in-flight 중인 packet 번호가 중복되지 않으면 괜찮다.
(b) 설명
0 전송 -> 0 수신. deliver. ack 0
1 전송 -> 1 수신. deliver. ack 1
2 전송 -> 2 수신. deliver. ack 2
(packet 0에 대해 timeout)
0 전송 -> 0 수신. deliver. ack 0
이 경우, 모두 수신을 성공했는데 ack을 보내는 과정에서 문제가 발생했고, retransmission timeout 때문에 다시 0을 보내게 되었다. 그러나, receiver의 window에선 0,1,2가 모두 정상이었기에 window가 이동했고, 따라서 window 범위 내에 있는 0은 다시 accept가 되는 문제가 발생한다. (0은 0이지만 같은 seq #가 아닌걸 인지하니 문제!)
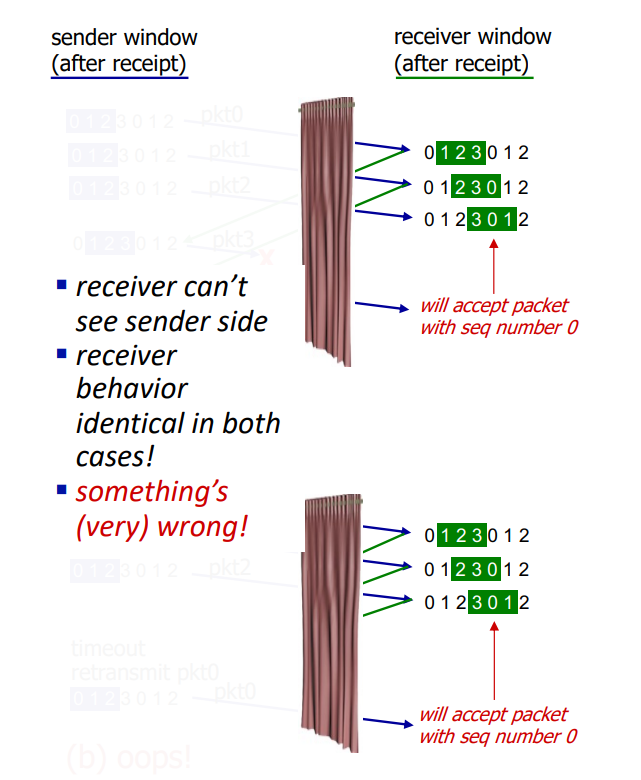
Receiver 측에선 sender side를 볼 수 없고, (a)경우와 (b) 경우에서 receiver의 행동이 똑같이 일어나고 있다.
이 문제를 방지하기 위해서는 sequence number space가 확장되어야 하고, sequence number space는 flight에 허용되는 최대 개수와 다른 요소들을 이용해 엄밀하게 계산되어야 한다.
sequence number space 계산