- Transport-layer services
- Multiplexing & demultiplexing
- Connectionless transport: UDP
- Principles of reliable data transfer
- Connection-oriented transport: TCP
- Principles of congestion control
- TCP congestion control
- Evolution of transport layer funcitonality
Principles of congestion control
TCP State Diagram
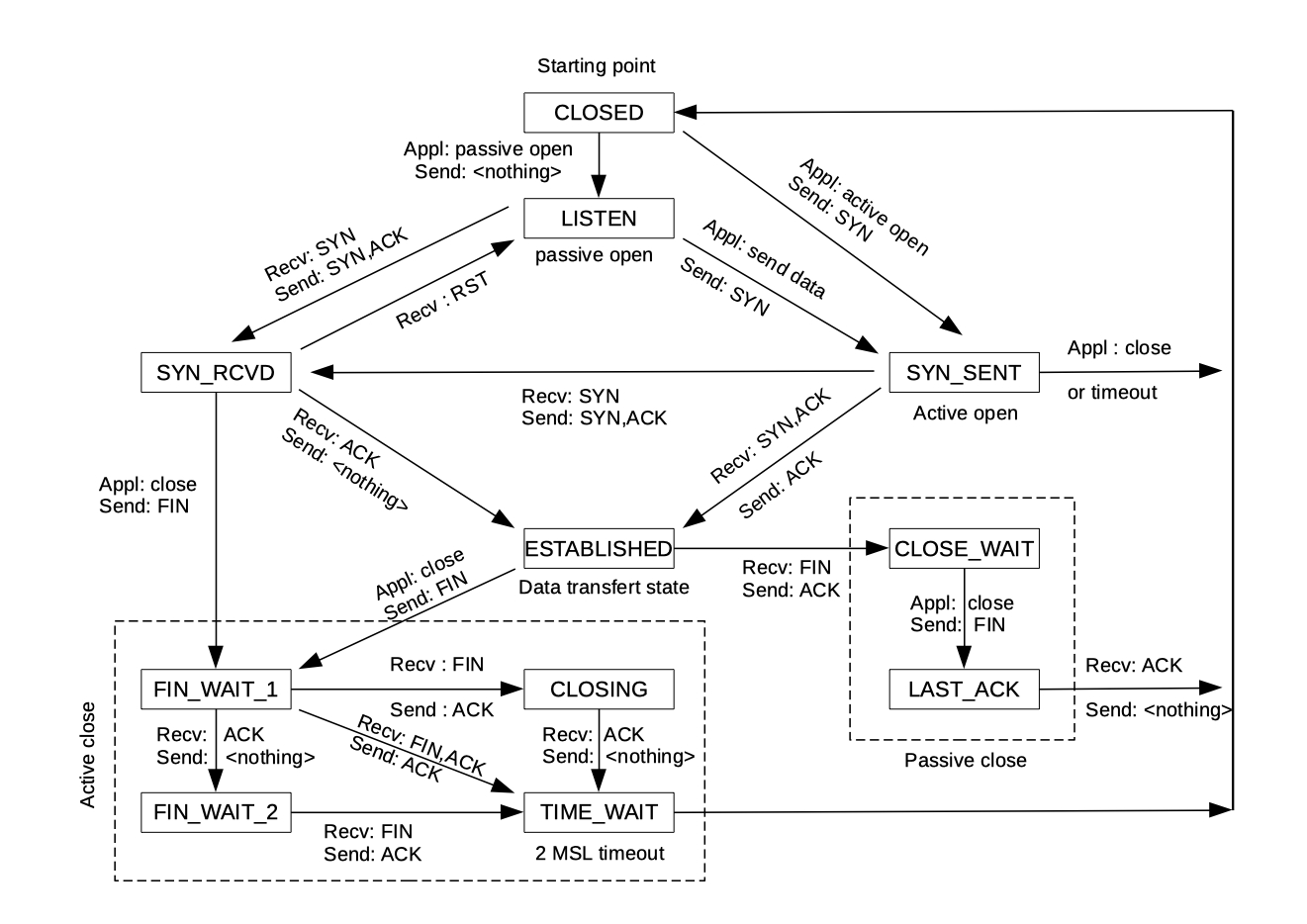
Server와 client 모두 active close를 할 수 있는데, 먼저 fin을 보내는 쪽이 active close를 하고, 이를 받는 쪽은 passive close가 된다.
Active close를 보면 TIME_WAIT이라는 state가 존재한다. 이 상태는 sender가 이미 종료된 연결과 관련된 모든 패킷들이 완전히 소멸될 때까지 대기하여 이후에 이 socket을 재사용할 때 생길 수 있는 충돌을 방지한다. 또한, 상대방이 마지막으로 보낸 ACK 패킷이 loss되었을 때에도 유용하다. 만약 sender가 socket을 바로 닫아버렸을 경우엔 ACK이 loss되어 retransmit을 해야하는데, 이 과정에서 문제가 생길 수 있기 때문이다.
Q. 그렇다면 socket이 왜 굳이 discard 대신 기다리는 방식을 선택한걸까?
A. Security를 위해서이다. 단순히 discard 시키는 방식을 선택하면, FIN을 받고난 뒤에 다른 host에서 순간적으로 같은 port로 접근해서 데이터를 확인할 수 있기 때문에 receive를 모두 하고 종료하는 방식이 안전하다.
- CLOSED: a TCP connection is inactive and no data can be sent.
- LISTEN: the TCP server is waiting for a client to open a new connection.
- SYN_RECVD: a TCP server has received the first TCP message from the client in the three-way TCP open hand-shake.
- SYN_SENT: a TCP client has sent its first message in the three-way handshake. This message has the SYN bit set.
- ESTABLISHED: the connection can start to send and receive data.
- FIN_WAIT_1: one side of a TCP connection shuts down by sending a message with the FIN bit set and waits for a FIN from the other side of the connection.
- FIN_WAIT_2: one side of a TCP connection has sent a FIN and received the ACK from the other side of the connection.
- CLOSE_WAIT: one side of a TCP connection receives a shutdown from the other side of the connection by receiving a message with the FIN bit set. It sends a message with the ACK bit set acknowledging the FIN.
- CLOSING: one side of a connection in FIN_WAIT_1 state gets a shutdown from the other side by receiving a FIN message and sends an ACK for that FIN and awaits the other side to send its final ACK.
- TIME_WAIT: one side of a connection sends its final ACK. The connection waits for a period of time to be sure of the other side has terminated completely.
- RST_ACT: one side of a connection sends its final FIN and awaits a final ACK from the other side of the connection. Upon reception of the final ACK, the connection is closed.
Principles of congestion control
Congestion이란 너무 많은 source들이 너무 많은 데이터들을 네트워크가 감당할 수 있는 속도 이상으로 보내면서 생긴 혼잡한 상황을 뜻한다. 이를 나타내는 대표적인 징후로 router buffer에서 queueing으로 인해 생기는 long delay와, router에서 buffer overflow가 일어나며 packet loss가 있다.
Congestion control은 너무 많은 sender가 너무 빠르게 보내서 문제인거라면, flow control은 하나의 sender가 하나의 receiver에게 너무 빨리 보내서 문제인 것이라 다르다는 점을 인지해야 한다. (Window가 아니라, network에 문제가 생기는 것!)
Causes/costs of congestion : scenario 1
우선 가장 단순한 형태의 시나리오부터 보자.
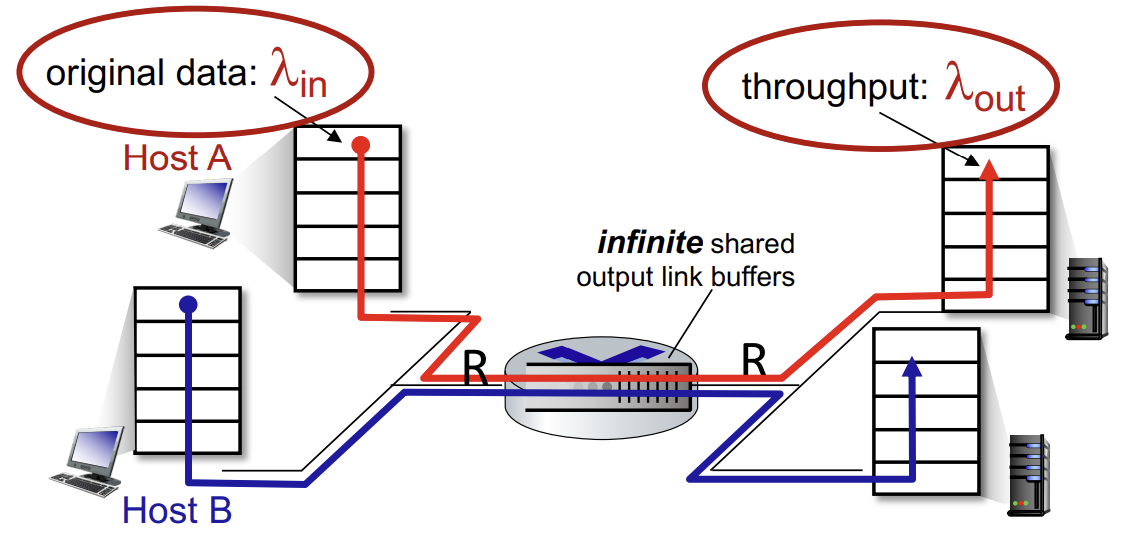
- router 1개, 무한 buffer
- input, output link capacity : R
- two flow만 존재
- retransmission이 필요 없음
- (retransmission을 고려하게 되면 네트워크에 더 많은 traffic이 발생함)
두 개의 flow가 하나의 router를 공유하고 있고, 최대 용량이 R인 상황이다.
Q. 만약 arrival rate in 이 R/2에 가까워지게 되면 어떻게 되는가?
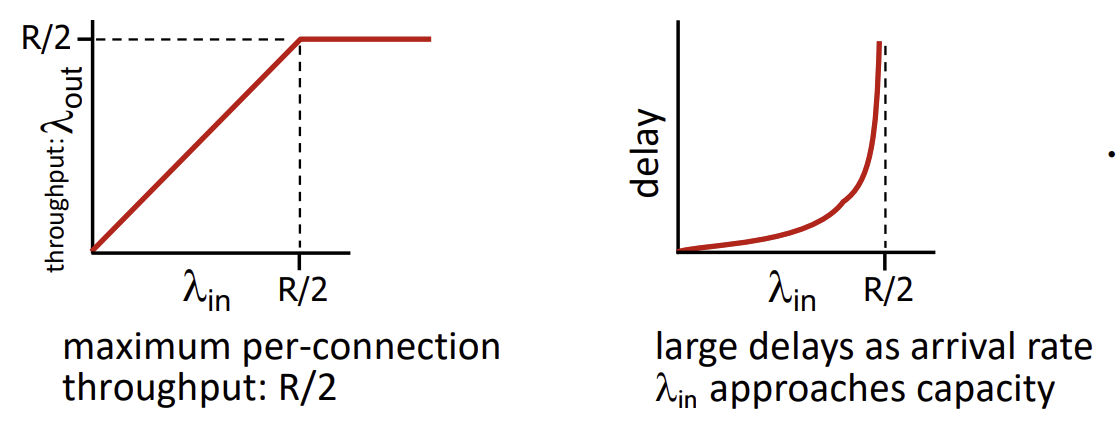
Original data와 throughput의 관계 그래프는 현재 retransmission이 없는 상황이기 때문에 손실 없이 넣는대로 나와야하니 1대 1의 비율을 가지게 된다. 따라서, host가 두 명이니 R/2가 max per-connection throughput이 된다. 또한, 무한 버퍼이니 R/2를 넘어서는 input이 들어와도 계속 버퍼에 넣어두면 되서 계속 R/2라는 throughput을 유지한다.
반면, original data와 delay의 관계 그래프는 R/2에 가까워질수록 무한히 발산하게 된다. 이는 이전에 배웠던 average queue delay for M/M/1 queue = (L/R)x(/(1-)) 식을 보면 알 수 있다. R/2에 가까워 질수록 traffic intensity는 1에 가까워지니, queueing delay 시간이 무한히 발산하게 되기 때문이다.
Causes/costs of congestion : scenario 2
이제부턴 buffer가 finite하다.
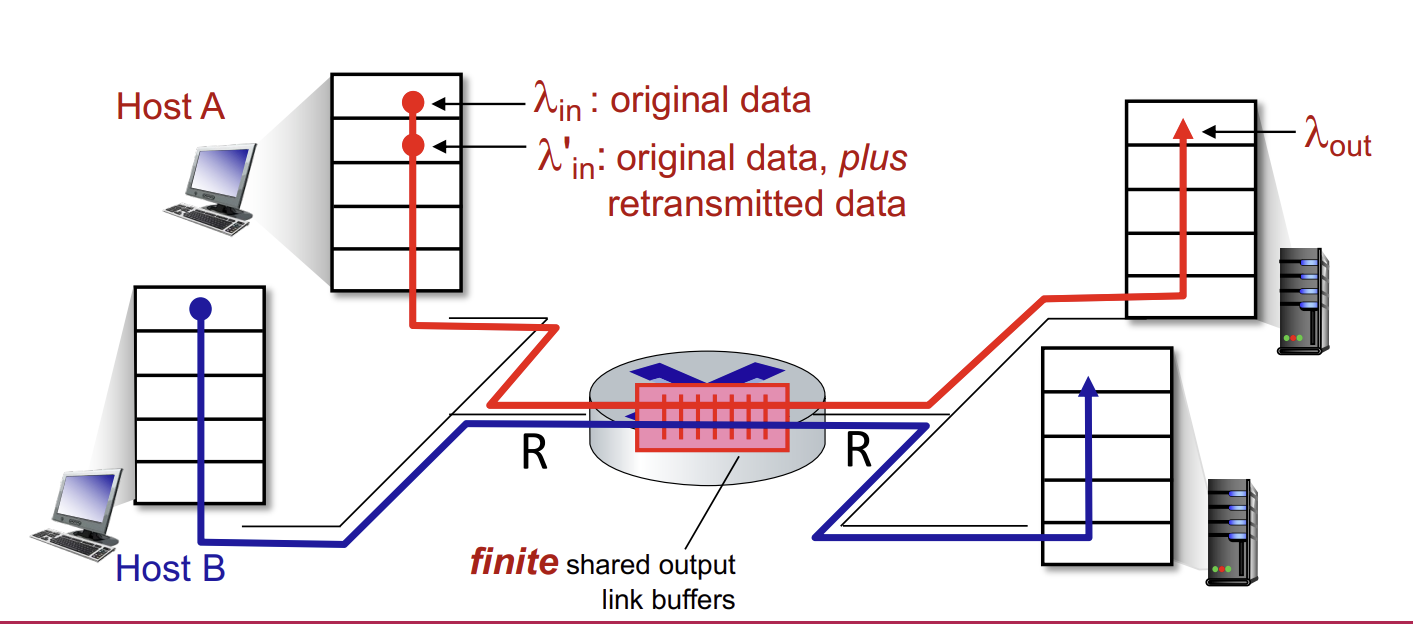
- sender가 lost가 일어나거나 time-out이 발생한 packet에 대해 retransmist을 해야 한다.
- application-layer input = application-layer output : in = out
- transport-layer input includes retransmissions : 'in >= in
- 즉, original data에 더해 retransmit data
이상적인 상황이라면 sender는 router buffer가 감당할 수 있을 만큼만 보내게 된다.
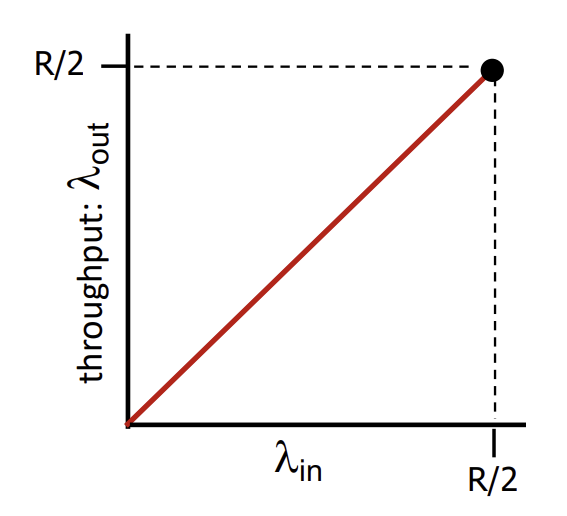
이상적인 상황에서는 retransmission이 필요없으니 1대 1의 비율을 가지고, R/2가 한계이며 그 이상은 전송 자체가 불가하다.
만약 조금은 덜 이상적인 상황을 가정해서, packet이 buffer가 가득차서 lost가 발생하는 경우를 보자. Sender는 packet이 언제 drop되어야 하는지 알기에, lost될 packet만 resend해도 된다.
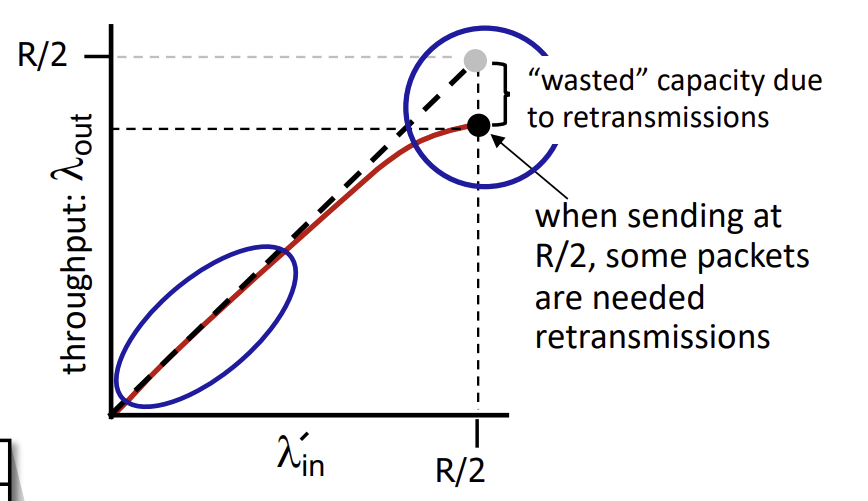
따라서, 보내고자 하는 데이터 양이 작을 때는 retransmit이 필요없으니 1 대 1의 비율을 가지나, R/2에 가까워질수록 일부 packet이 retransmit이 필요하니 capacity가 낭비되게 되어 최종적인 throughput이 R/2보다 낮아지게 된다.
하지만 진짜 현실적인 경우엔 sender가 packet을 언제 drop해야하는지 모르기 때문에 필요하지도 않는 duplicate까지 고려해야 한다. Packet은 lost될 수도 있고, full buffer에 의해 drop될 수 있으며, sender는 premature timeout 때문에 duplicate들을 전송할 수 있다.
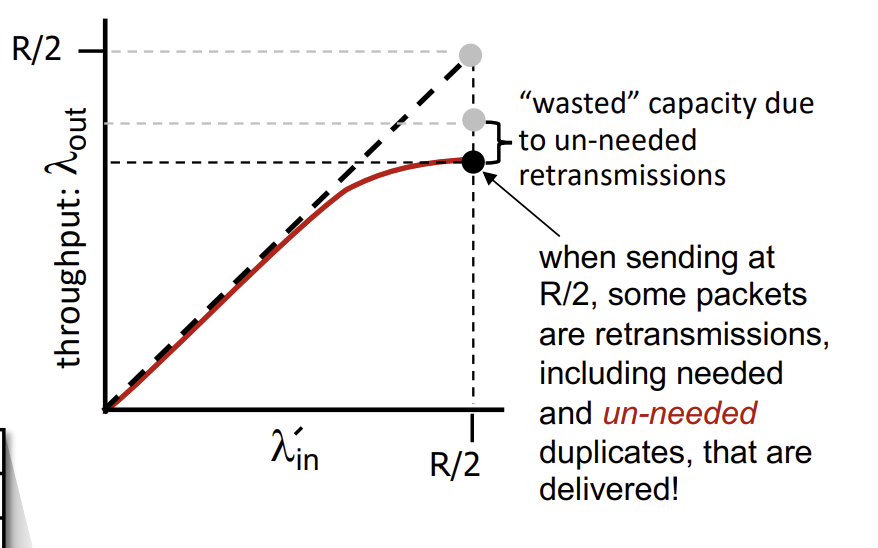
따라서 R/2에 가까워질수록 불필요한 duplicate을 포함해서 더 많은 packet들이 retransmit을 해야하였고, 필요하지 않는 retransmission 때문에 최종 throughput이 더 낮아지게 된다.
Causes/costs of congestion : scenario 3
이제는 4명의 sender가 있고, 경로들이 겹치며, timeout과 retransmit을 모두 고려해야 하는 복잡한 상황이다. 총 4종류의 flow가 흐르고 있다.
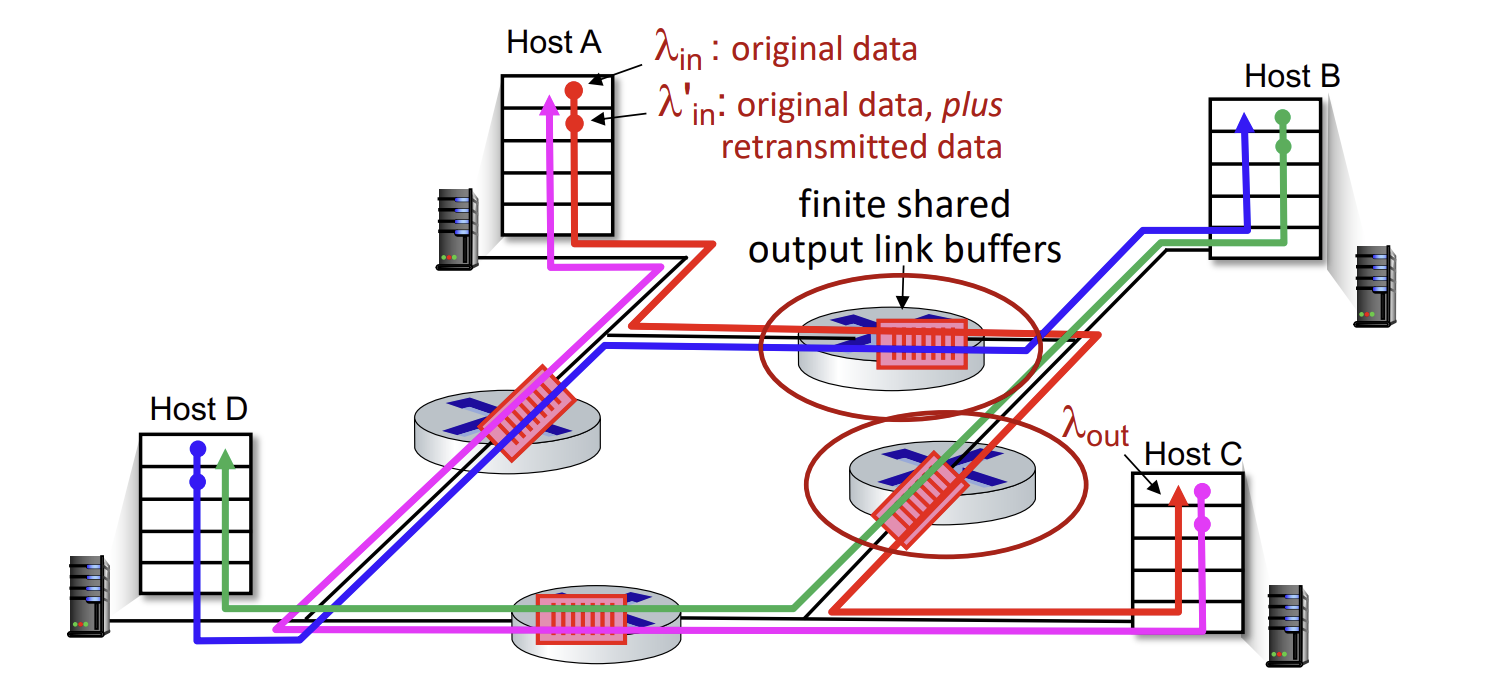
Q. in 와 'in가 증가할 때 무슨 일이 일어나는가?
A. 빨간 flow의 'in가 증가할수록, 같은 router를 경유하는 router에서 파란 packet들이 대부분 drop되며 파란 flow의 throughput이 0이된다.
이런 문제가 발생하는 이유는, 같은 router여도 경로에 따라 upstream일수도, downstream일수도 있기 때문이다. 앞서 예를 들었던 router의 경우 red flow의 upstream이자 blue flow의 downstream router였다. 이때 전송량이 많아질수록 router에서 buffer에 경쟁이 벌어지게 되는데, blue flow에선 이 곳이 downstream이기 때문에 upstream에선 상황을 알 수 없어 계속해서 packet을 보내려고 시도하게 된다. 그래서 packet loss로 이어지는 것이다.
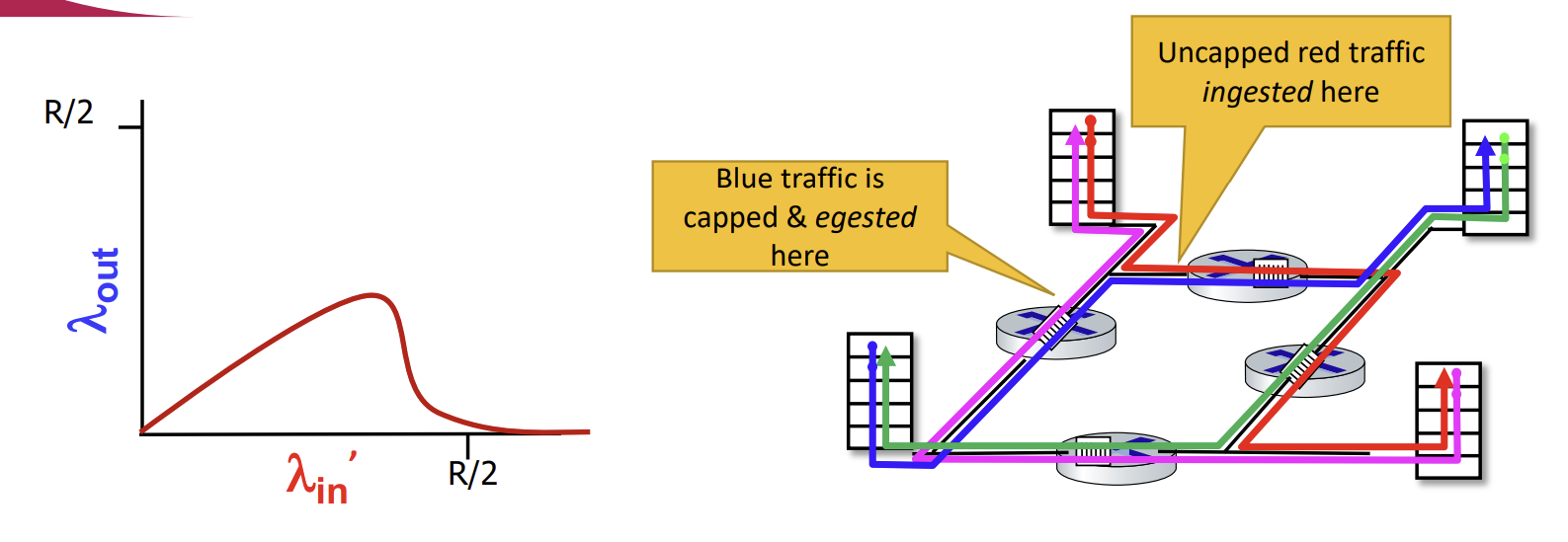
따라서 이 경우엔 'in가 증가할수록 throughput이 계속해서 증가하는 것이 아니라 특정 지점에서 max값을 찍고 감소하며, 0으로 수렴하는 그래프를 그리게 된다.
Packet이 downstream router에서 drop이 되면, 그를 거치는 모든 upstream router들은 transmission capacity와 buffering에 추가적인 cost를 쓰게 되는 것이다.
Causes/costs of congestion : insights
- throughput은 절대 capacity를 초과할 수 없다.
- delay는 capacity에 가까워질수록 급격히 증가한다.
- loss/retransmission은 effective throughput을 저해한다.
- 필요하지 않은 duplicate도 effective throughput을 저해한다.
- upstream transmission capacity/buffering이 downstream에서의 packet lost에 의해 낭비될 수 있다.
Approaches towards congestion control
End-end congestion control
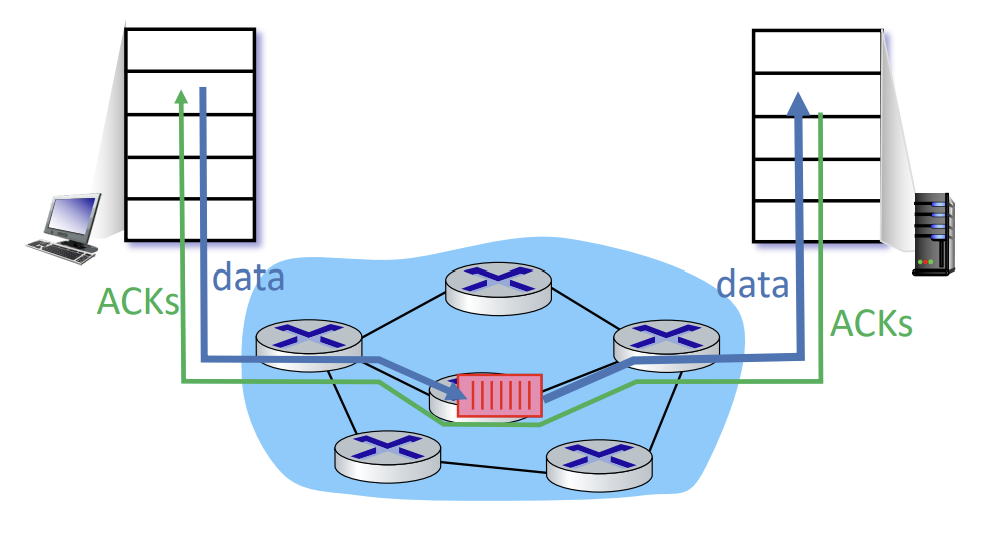
- 네트워크로부터 직접적인 피드백이 없다.
- congestion이 발생하였음은 loss와 delay로부터 추론된 것이다.
- TCP에 의해 채택되고 있는 방식이다.
Network-assisted congestion
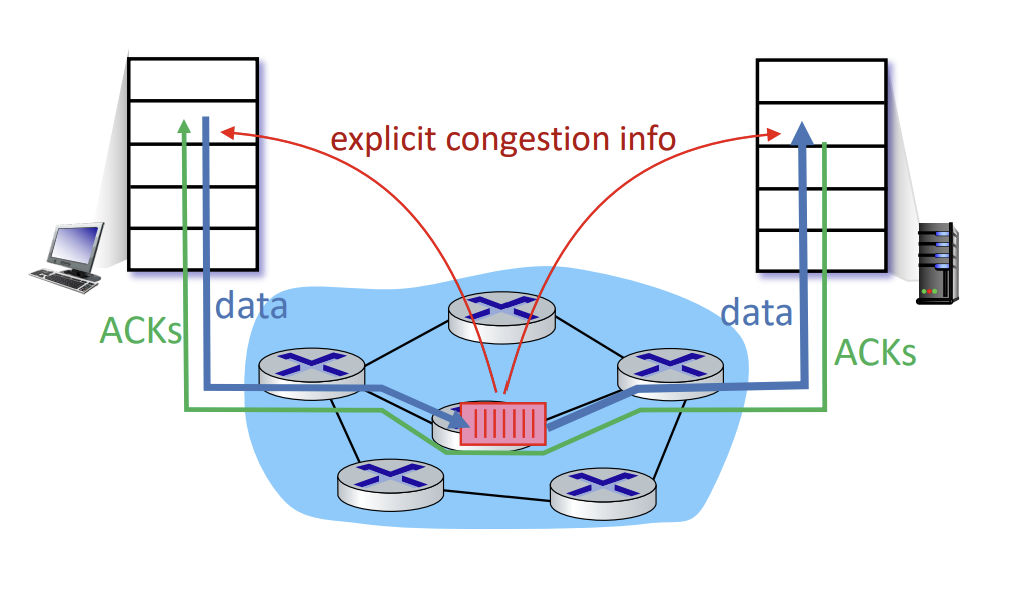
- router가 congested router를 지나는 flow를 가진 sending/receiveing host에게 직접적인 피드백을 준다.
- congestion level을 명시하거나, sending rate을 구체적으로 설정한다.
- TCP ECN, ATM, DECbit과 같은 protocol 따르는 방식이다.
- 여기서 TCP ECN은 IP header에 ECE(ECN Echo)이라는 flag를 통해 congestion이 발생했음을 알리고, 그 다음 packet은 CWR(congestion window reduce) flag를 가지고 전달된다.
