- Transport-layer services
- Multiplexing & demultiplexing
- Connectionless transport: UDP
- Principles of reliable data transfer
- Connection-oriented transport: TCP
- Principles of congestion control
- TCP congestion control
- Evolution of transport layer funcitonality
TCP congestion control
TCP congestion control: AIMD
Sender는 sending rate를 packet loss(congestion)이 발생할 때까지 증가시킬 수 있고, loss event가 발생할 경우 줄이게 된다.
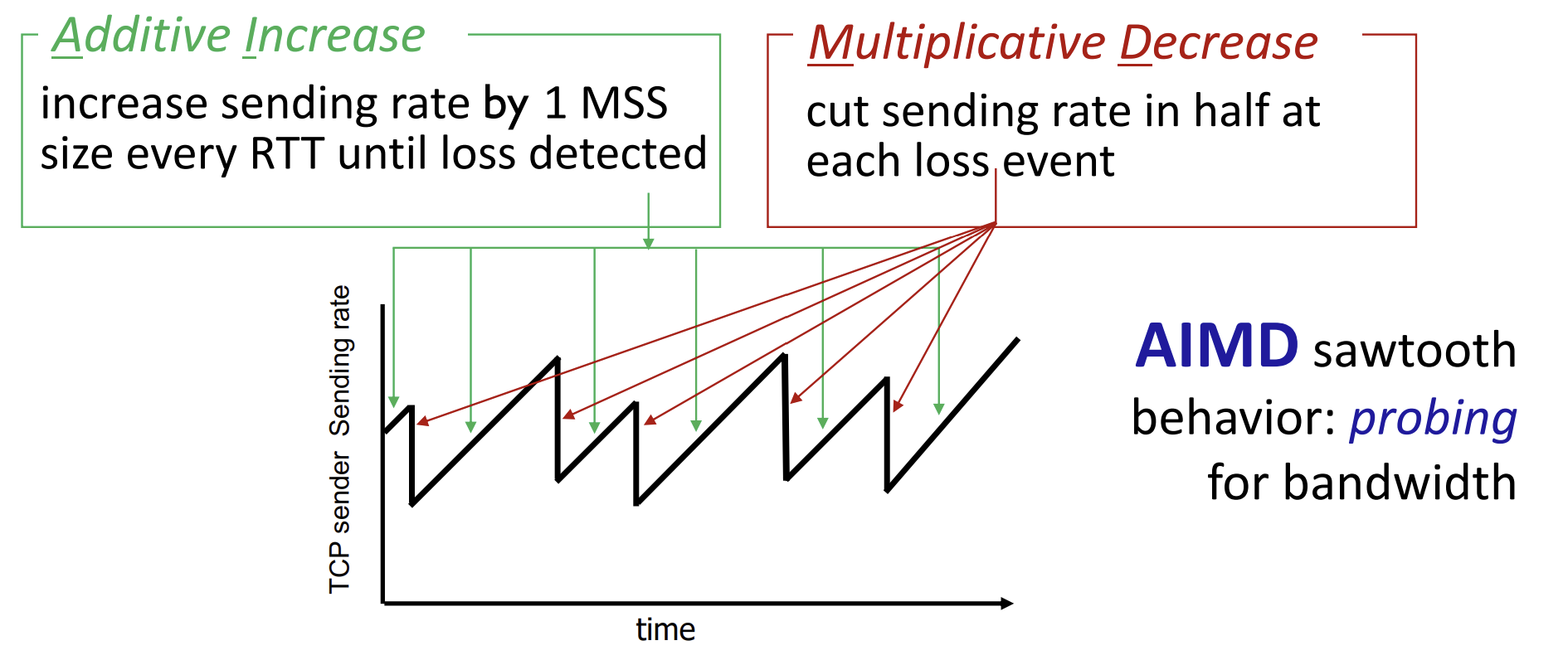
그래서 시간에 따라 TCP의 sender rate를 표기하면 톱날 모양의 그래프를 얻게 된다.
- Additive Increase
- loss가 detect되기 전까지 모든 RTT에서 1 MSS만큼 sending rate를 증가시킨다.
- Multiplicative decrease
- loss event가 발생시 sending rate를 절반으로 줄인다.
이런 방식을 채택한 이유는 congestion threshold가 어느 지점인지 알 수 없고, 따라서 congestion window 크기가 매번 바뀌니 loss가 발생하는 지점이 달라 AIMD(Additive Increase Multiplicative Decrease) 행동을 하게 되는 것이다. 따라서, congestion window의 크기가 클수록 해당 범위 내에서 대역폭을 잘 활용할 수 있게 된다.
- Multiplicative decrease detial
- TCP Reno 방식 (newer)
- loss가 triple duplicate ACK에 의해 감지되면 sending rate를 절반으로 줄인다.
- TCP Tahoe 방식 (older)
- loss가 timeout에 의해 감지되면 sending rate를 1 MSS로 줄인다.
- TCP Reno 방식 (newer)
Q. 왜 AIMD를 사용하는가?
A. AIMD는 distributed, asynchronous algorithm으로 혼잡된 flow rate를 전체 네트워크에서 최적화시킬 수 있으며, 안정적인 특성을 가지고 있기 때문이다.
TCP congestion control: details
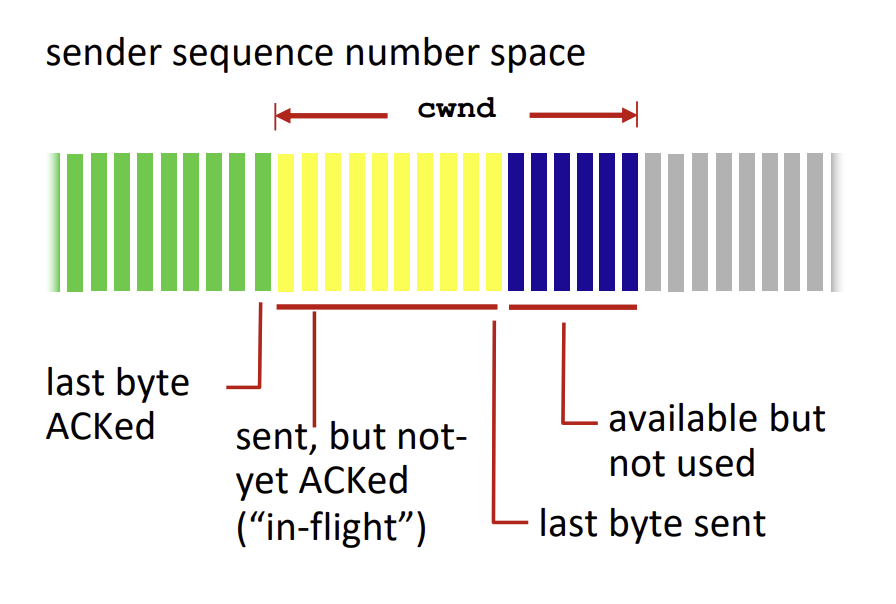
TCP sending behavior는 cwnd bytes만큼 보내고, ACK을 위해 RTT만큼 기다리고, 남은 byte를 보내는 방식으로 진행된다.
즉, TCP rate는 cwnd/RTT (bytes/sec)로 근사해서 표현할 수 있다.
TCP sender는 transmission을 제한하기 위해 LastByteSent - LastByteAcked <= cwnd 라는 조건식을 사용한다. cwnd는 관찰된 네트워크의 혼잡 상황에 따라 동적으로 정해지는 값이다.
TCP slow start
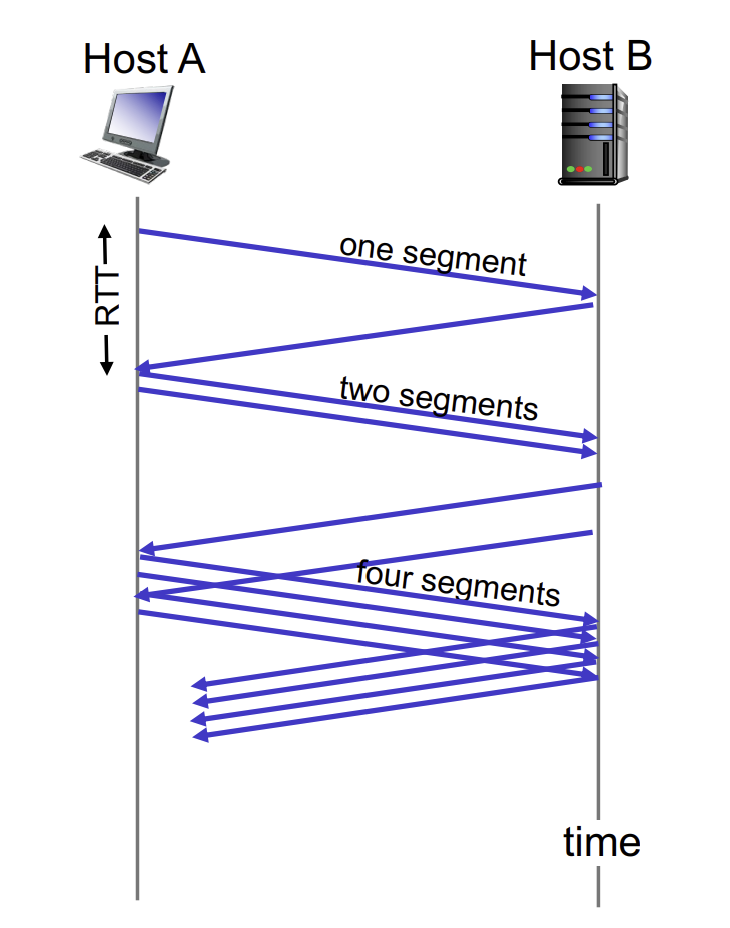
Connection이 시작되면, sending rate를 첫 번째 loss event가 발생하기 전까지 지수적으로 증가시킨다.
- initially cwnd = 1 MSS
- double cwnd every RTT
- done by incrementing cwnd for every ACK received
따라서, initial rate는 느린데, 지수적으로 증가시키는 방식이다.
TCP : from slow start to congestion avoidance
Q. 그렇다면 이 지수적 증가는 어느 시점에서 선형적인 증가로 대체되는가?
A. cwnd가 timeout이 발생하기도 전에 절반으로 감소하는 시점부터
이를 구현하기 위해, ssthresh라는 variable을 이용한다. Loss event가 발생하면, ssthresh가 lost event가 발생하기 직전의 cwnd의 1/2 값으로 설정된다. Congestion control 알고리즘이 혼잡 상황을 감지하면 ssthresh 값을 설정하고, 이후에 cwnd 값이 ssthresh보다 작은 상태를 유지하도록 Congestion Avoidance 과정을 거치게 된다.
Q. 그렇다면 cwnd를 2배씩 증가시키는 건 어떻게 구현하는가?
A. 각 packet의 ack을 받을 때마다 cwnd를 1씩 증가시킨다.
Summary : TCP congestion control
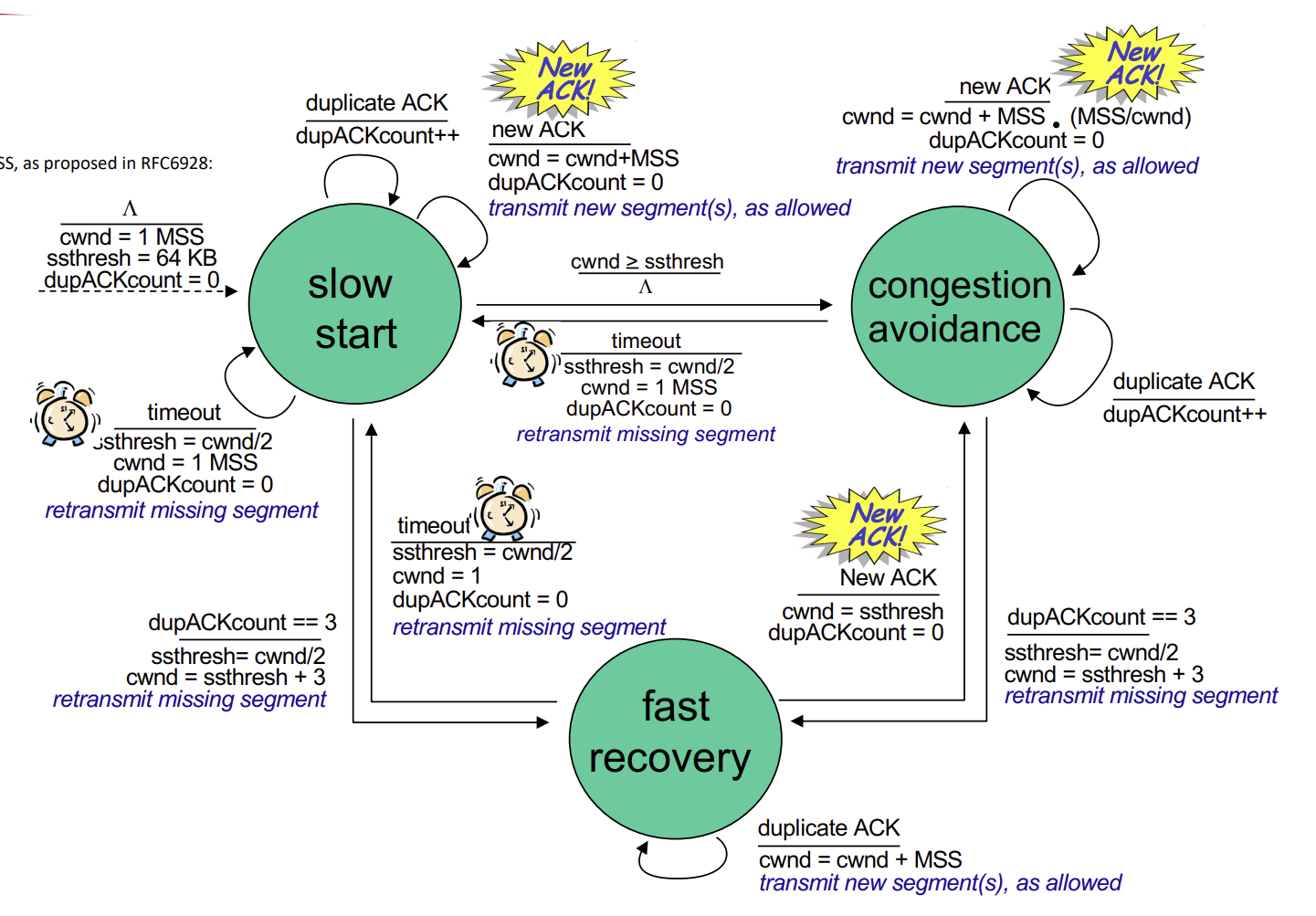
우선, cwnd는 1MSS로 초기화, ssthresh는 64KB, dupACKcount는 0으로 초기화된 상태이다.
- Slow start
- 새로운 ACK이 도착할 경우, cwnd를 1MSS만큼 증가시키고 dupACKcount를 0으로 초기화한다. 그 후, 허용되는 만큼 새 segment를 전송한다.
- 결과적으로 cwnd 2배. 지수적 증가.
- duplicate ACK이 도착할 경우 dupACKcount 1 증가.
- timeout이 발생한 경우, ssthresh를 현재 cwnd의 절반 값으로 할당, cwnd를 1MSS부터 시작. dupACKcount도 0으로 초기화. 잃어버린 segment retransmit.
- 만약 cwnd >= ssthresh가 되는 경우, congestion avoidance state로 이동.
- duplicate ACK이 3개가 되는 경우, ssthresh를 현재 cwnd의 절반 값으로 할당하고, cwnd를 ssthresh에 3만큼 더한 값으로 할당한다. 그리고 잃어버린 segment를 retranmsit한다.'
- 그리고 fast recovery state로 이동하게 된다.
- Congestion avoidance
- 새로운 ACK이 도착할 경우 cwnd를 (MSS x MSS)/cwnd 값만큼 증가시키고 dupACKcount를 0으로 초기화한다. 그 후, 허용되는 만큼 새 segment를 전송한다.
- 결과적으로 cwnd가 선형적으로 증가.
- duplicate ACK이 도착할 경우 dupACKcount 1 증가.
- duplicate ACK이 3개가 되는 경우, ssthresh를 현재 cwnd의 절반 값으로 할당하고, cwnd를 ssthresh에 3만큼 더한 값으로 할당한다. 그리고 잃어버린 segment를 retranmsit한다.'
- 그리고 fast recovery state로 이동하게 된다.
- 새로운 ACK이 도착할 경우 cwnd를 (MSS x MSS)/cwnd 값만큼 증가시키고 dupACKcount를 0으로 초기화한다. 그 후, 허용되는 만큼 새 segment를 전송한다.
- Fast recovery
- duplicate ACK이 들어오면 cwnd를 1 MSS만큼 증가시키고 허용되는 만큼 새 segment를 전송한다.
- 새로운 ACK이 도착할 경우 cwnd를 ssthresh로, dupACKcount를 0으로 초기화한다.
- 그리고 congestion avoidance state로 이동하게 된다.
- timeout이 일어나면 ssthresh를 현재 cwnd의 절반 값으로 할당하고, cwnd를 1로 초기화, dupACKcount도 0으로 초기화한다. 잃어버린 segment를 retransmit한다.
- 그리고 slowstart state로 이동하게 된다.
+) 각 state의 의미
Slow start state : Slow Start 상태는 TCP 연결이 처음 설정될 때와, 패킷 유실이 발생했을 때 사용. cwnd의 지수적 증가.
Congestion Avoidance state : Congestion Avoidance 상태는 Slow Start 상태에서 cwnd 값이 ssthresh(threshold) 값보다 커지는 경우에 전환. cwnd의 선형적 증가.
Fast Recovery state : Fast Recovery 상태는 Dup ACK 패킷이 수신될 때마다 혼잡 상황을 회피하기 위해 사용. 이 state로 들어오면서 ssthresh가 cwnd/2로 설정되고, 해당 state에 머무르며 현재 cwnd 값이 ssthresh 값보다 작아지게 만든다.
TCP CUBIC
AIMD의 경우, 반복적으로 sending rate를 증가시키고 감소시키는 과정을 통해 bandwith를 추측해 대응하였다. 이보다 더 좋은 방법으로 대응할 수 없을까?
- insight
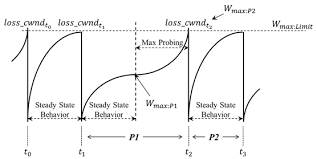
- Wmax : congestion loss가 발생했던 곳의 sending rate
- congestion의 원인이 되는 bottleneck link의 state는 크게 바뀌지 않을 것
- loss 이후에 rate/window를 절반으로 줄여도, Wmax를 처음에 더욱 빠르게 도달하고, 한계 지점 근처에서 느리게 접근하면 어떨까?
- K : TCP window size가 Wmax를 도달하는 시점.
- K값 자체는 조정할 수 있따.
- W를 현재 시간과 K 사이의 거리에 대해 세제곱 함수로 증가시킬 수 있다.
- K에서 멀수록 빠르게 증가
- K에 가까울수록 느리게 증가.
- TCP CUBIC은 리눅스에서 기본값이며, 유명한 웹서버에서 가장 많이 이용되는 TCP이다.
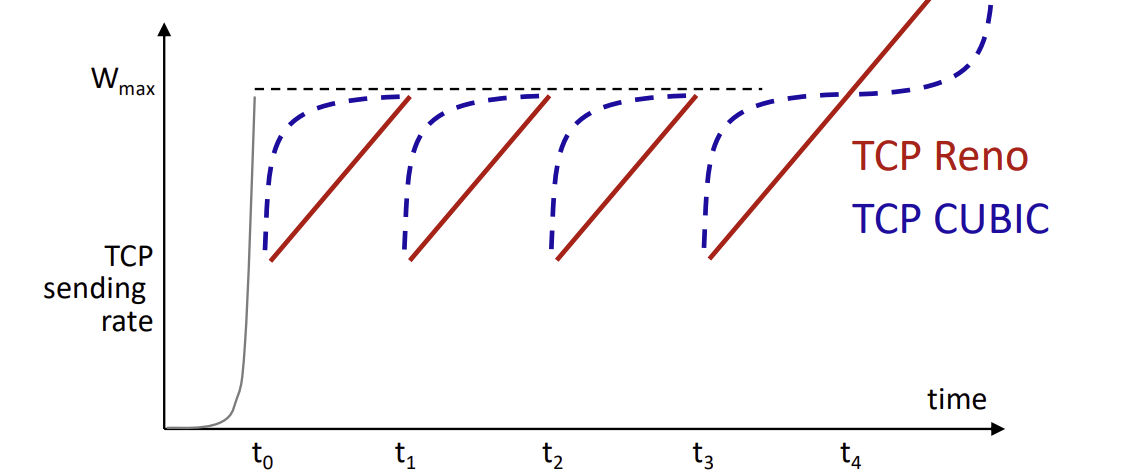
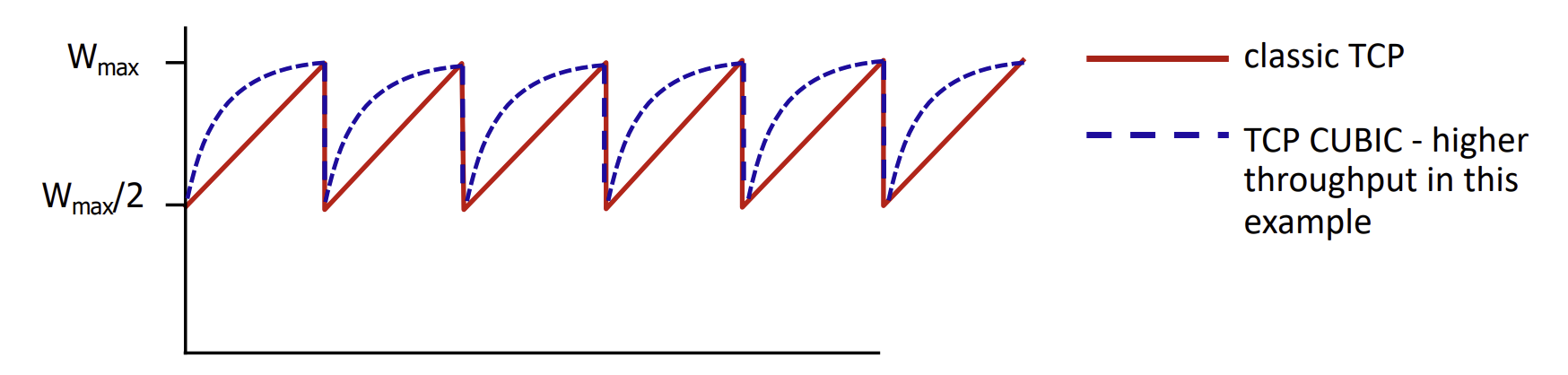
TCP Tahoe (86) vs TCP Reno (90) vs TCP CUBIC (06)
그래프를 보면, TCP Tahoe와 TCP Reno가 유사한 혼잡 제어 알고리즘을 사용한다는 것을 알 수 있습니다. 혼잡이 발생하면, 이들은 송신률을 반으로 줄이는 것처럼 혼잡 윈도우 크기를 급격히 줄입니다. 타임아웃 기간 후, 다시 다음 혼잡 이벤트가 발생할 때까지 혼잡 윈도우 크기를 선형적으로 증가시킵니다.
반면, TCP CUBIC은 다른 혼잡 제어 알고리즘을 사용합니다. 혼잡이 감지될 때까지 혼잡 윈도우 크기를 지수적으로 증가시키며, 그 이후에는 혼잡 윈도우 크기를 감소시킨 다음, 점진적으로 다시 증가시킵니다.
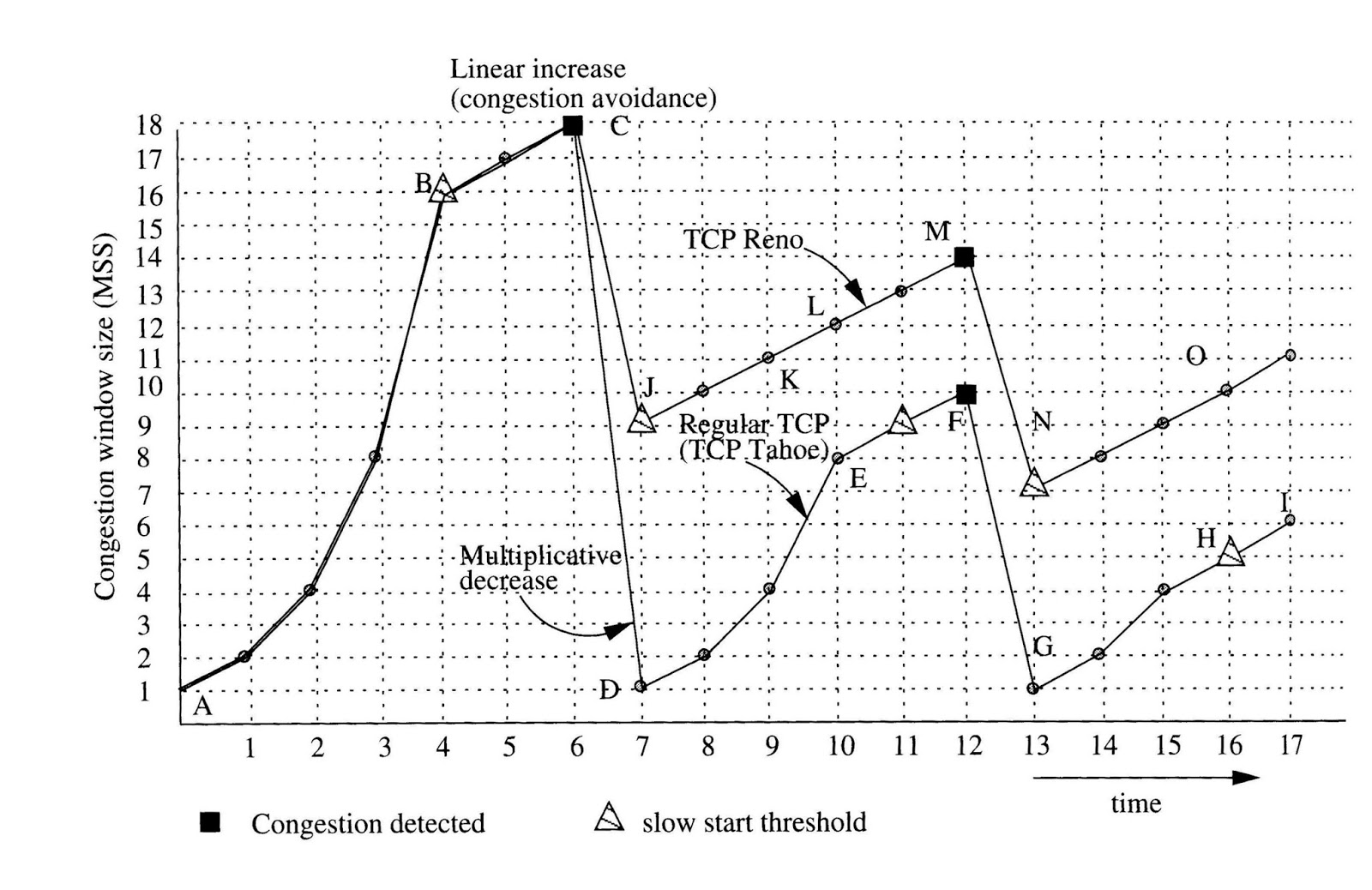
TCP Tahoe는 Congestion Avoidance 단계에서 패킷 손실이 발생하면 혼잡 윈도우 크기를 작게 조정합니다. 패킷 손실을 감지하면 Slow Start 단계로 돌아가서 혼잡 윈도우 크기를 작게 설정하고 다시 시작합니다. 이로 인해 TCP Tahoe는 패킷 손실을 지속적으로 경험하게 됩니다.
반면에 TCP Reno는 Congestion Avoidance 단계에서 패킷 손실을 감지하면, 혼잡 윈도우 크기를 반으로 줄이고 Fast Recovery 모드로 전환합니다. Fast Recovery 모드에서는 패킷 손실을 감지하지 않고도 혼잡 윈도우 크기를 증가시키면서 전송을 계속합니다. 이러한 방식으로 TCP Reno는 패킷 손실을 더 능동적으로 처리하며, 혼잡 윈도우 크기를 조절하는 데 더 정교한 방법을 사용합니다.
따라서, TCP Tahoe와 TCP Reno의 차이점은 Congestion Avoidance 단계에서 발생하며, TCP Reno가 더욱 효율적으로 혼잡 제어를 수행할 수 있도록 개선된 알고리즘을 사용한다는 것이 가장 큰 차이점입니다.
TCP and the congested bottleneck link
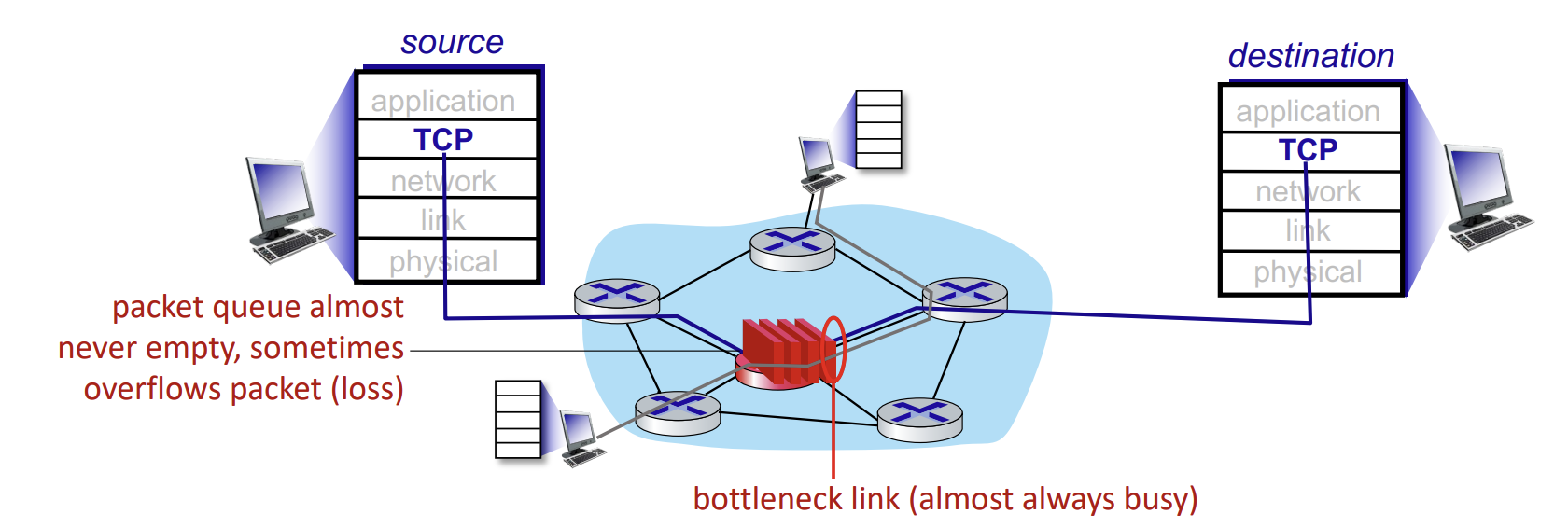
TCP (classic, CUBIC)은 어떤 임의의 router에서 packet loss가 발생할때까지 TCP의 sending rate를 증가시킨다. 즉, 특정 bottleneck link가 congestion의 원인인 것인데, 이곳에 TCP sending rate를 증가시키는 것은 RTT가 길어지는 것으로 이어지게 된다.
우린 end-end pipe를 최대한 이용하는 것이지, 더 넘치게 이용하고 싶은 것이 아니다. 즉, bootleneck link를 바쁘게 이용하되, 높은 delay/buffering을 피하고 싶은 것이다.
Delay based TCP congestion control
우리가 지금까지 배웠던 AIMD나 CUBIC congestion control 알고리즘은 packet loss가 발생하였을 때만 cwnd 크기를 조절하기 때문에, packet loss를 경험하지 않으면 congestion control에 대해 반응이 느리고 전송률이 불안정해질 수 있다.
Delay-based congestion control의 경우 RTT의 길이를 기반으로 cwnd의 크기를 동적으로 조절함으로써 packet loss를 경험하지 않더라도 congestion control이 가능하다. Uncongested path에 대해서 RTTmin을 관측하고, 현재 throughput이 uncongested throughput에 가까우면 cwnd를 선형적으로 증가시키고, 멀어지면 cwnd를 선형적으로 줄인다. 이 방식을 통해 delay를 낮으면서도 throughput을 최대화할 수 있다.
다수의 TCP는 이 delay-based 방식을 사용하며, 구글의 네트워크도 대표적인 delay-based 알고리즘인 BBR(Bottleneck Bandwidth and RTT) 알고리즘을 사용한다.
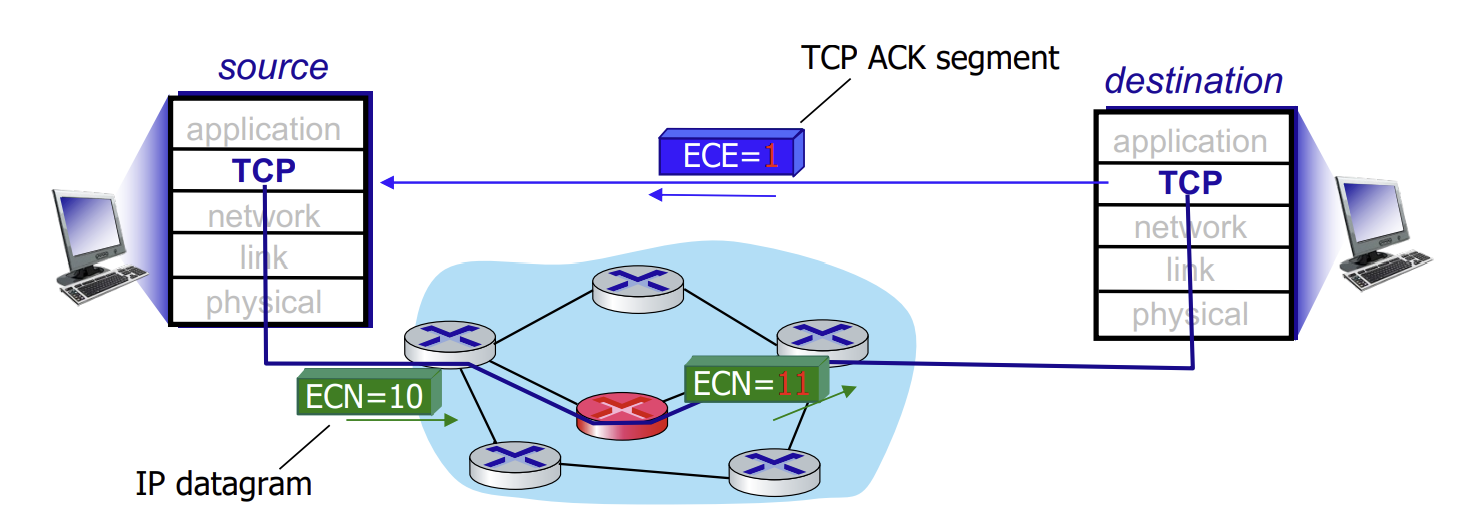
Network-assisted congestion control
이전에 소개되었던 end-to-end congestion control 방식과 달리, network-assisted congestion control은 네트워크 요소들이 congestion을 감지하고 이를 제어하는 데 직접적으로 개입한다. 위 그림에서도 볼 수 있듯이, TCP header 내부에 있는 CWR, ECE라는 두 flag를 이용해 congestion control을 수행한다.
Explicit congestion notification (ECN)
Explicit congestion notification은 network router에서 congestion이 발생하였음을 감지하면 IP header (ToS field)에 있는 두 개의 bit를 이용해 congestion이 일어났음을 명시한다. (네트워크 운영자가 선택한 표시를 결정하는 정책)
이렇게 congestion이 표시된 header는 destionation까지 전달되어, destination에서 ACK segment에 ENE bit로 설정되어 congestion의 sender에게 congestion이 발생하였음을 알리게 된다.
IP(IP header ECN bit marking)과 TCP (TCP header CWR, ECE bit marking)이 포함된다.
TCP fairness
TCP는 bandwith를 사용할 때 경쟁적인 방식으로 동작하나, 각각의 TCP connection이 bandwith를 공정하게 나누어 사용할 수 있도록 하는 것을 목표로 한다. 즉, K개의 TCP session이 있고 bandwith가 R이면 각 session이 R/K만큼씩 사용할 수 있게 하고자 한다.
Q. Is TCP fair?
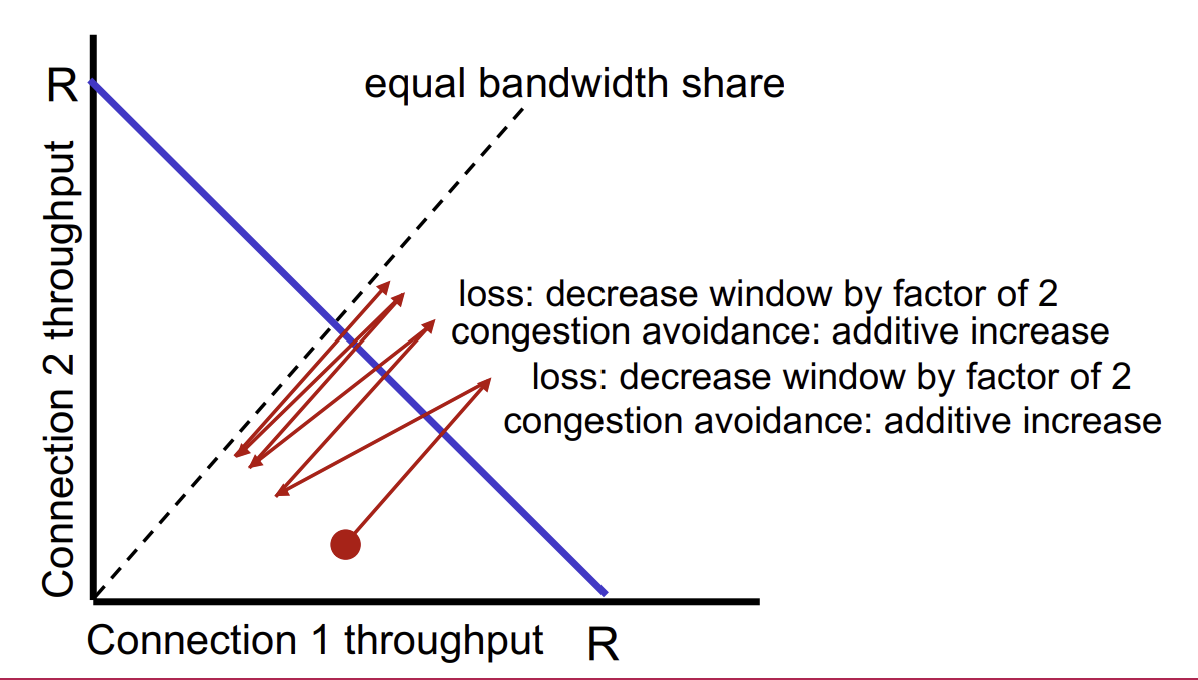
그래서 두 개의 TCP session이 경쟁하고 있는 상황을 보자. 첫 지점을 보면 connection 1과 2의 throughput이 결정되어 있는데 1이 2에 비해 적은 bandwith를 사용하고 있다. 따라서, connection 1이 additive increase를 사용해 equal bandwith share의 기울기를 따라 bandwith를 증가시킨다. (congestion avoidance state) 이때 두 connection의 합이 bandwith R을 넘어서면, multiplicative decrease를 이용해 throughput을 줄인다. 이 과정을 반복하여 bandwith를 공정하게 나누는 지점에 가까워지게 된다.
따라서 TCP는 각 connection이 같은 RTT를 가지고, 특정한 시점에서 전송중인 TCP session의 수가 고정되어있으며 해당 세션들이 congestion avoidance 상태라는 조건이 충족되면 fair하다고 말할 수 있다.
Fairness : must all network apps be fair?
-
Fairness and UDP
- multimedia app들은 종종 TCP를 사용하지 않는다.
- 이들은 congestion control 때문에 속도가 조절되길 원하지 않는다.
- 그래서 UDP를 사용해, audio/vedio를 일정 속도로 보내며 도중에 packet loss가 일어나도 감당한다.
- congestion control에 관련된 policy가 없다.
- multimedia app들은 종종 TCP를 사용하지 않는다.
-
Fairness, parallel TCP connections
- application들은 두 host 사이에서 multiple parallel connection을 열 수 있다.
- 웹 브라우져도 이에 해당된다.
- 만약 9개의 connection이 존재하고 bandwith가 R인 상황
- 새로운 app이 1TCP를 요청 -> rate R/10
- 새로운 app이 11TCP를 요청 -> rate R/2
- 만약 9개의 connection이 존재하고 bandwith가 R인 상황
-
Fairness, parallel TCP connections
