Word2Vec
word embedding에 사용되는 Word2vec에는 skipgram,cbow,negative sampling-skipgram, glove, gensim,fasttext 등이 있습니다
효과적인 word2vec학습을 위해서는 충분한 데이터양이 필요한데 이때 데이터 양은 많을 수록 좋지만 많아질 수록 최적화된 학습을 시키기에 더 오랜시간과 노력이 필요합니다.
특히 한국어는 영어에 비해 전처리도 힘들고 데이터 수집도 더 어렵습니다. 영어로 된 Word embedding이 아닌 네이버 영화 리뷰 댓글 데이터를 사용해 skipgram 모델을 직접 학습해 본 후 pretrained model 인 Fasttext의 결과와 비교해보도록 해보겠습니다.
Data
네이버 영화리뷰 댓글 데이터는 본래 문장을 보고 긍정적인 문장인지, 부정적인 문장인지 판별하는 Sentiment Analysis를 위한 dataset입니다.
train data : 150,000 문장,test data: 50,000 문장이 각각 긍정 : 1, 부정 : 0 으로 label이 존재하는 형태로 구성 되어 있습니다
 Fig 1.train dataset
Fig 1.train dataset
- 데이터 전처리
- 중복 문장 제거
- 한글 제외 특수문자 제거
- 공백 제거
- 전 처리 후 ''만 남은 문장 Nan 처리 후 Nan 제거
 Fig 2.Data with preprocessing
Fig 2.Data with preprocessing
한국어 문장 분석기 konlpy mecab을 사용하여 형태소 기준으로 tockenize
token 등장 횟수로 vocabulary 생성
 Fig 3.Vocab with counts
Fig 3.Vocab with counts
총 종류의 수는 48022가지지만 단어가 전체 문장 데이터셋에서 등장 횟수가 20번 이상인 단어들만 남기고 나머지는 <unknown>으로 처리 하였더니 4886가지가 남았습니다
Model training
기존 문장 datset에서 4886가지의 vocabulary를 사용해 skipgram training pair를 구축하였습니다
학습에 사용되는 pair sample은 2771024개로 4886개 단어 + unk로 총 4887 차원의 데이터를 100 차원으로 embedding하는 모델을 구축하였습니다.
 Fig 4.skipgram model
Fig 4.skipgram model
 Fig 5.train epoch - loss 그래프
Fig 5.train epoch - loss 그래프
Fasttext
Fasttext는 Facebook에서 학습 후 제공하는 opensource로
총 157개의 언어에 대한 word embedding을 제공합니다
 Fig 6.Fasttext Languages
Fig 6.Fasttext Languages
from gensim import models
ko_model = models.fasttext.load_facebook_model('./fasttext_korean/cc.ko.300.bin.gz')
for w, sim in ko_model.wv.most_similar('파이썬'):
print(f'{w}: {sim}')
-----
Python: 0.5650615692138672
자이썬: 0.5624369382858276
레일스: 0.5598082542419434
파이썬을: 0.5595802068710327
언어용: 0.5288202166557312
파이썬의: 0.5250024795532227
프로그래밍: 0.5225088596343994
wxPython: 0.5222088694572449
파이썬이나: 0.5201171636581421
함수형: 0.5187377333641052
---
print(ko_model.wv.similarity("코딩", '파이썬'))
print(ko_model.wv.similarity("파이썬", '자바'))
print(ko_model.wv.similarity("파이썬", '딥러닝'))
print(ko_model.wv.similarity("자바스크립트", '자바'))
print(ko_model.wv.similarity("아이스크림", '컴퓨터'))
---
0.3680165
0.43627012
0.33482772
0.44514233
0.1794334
---
print(ko_model.wv.most_similar(positive=['어벤져스', '아이언맨'], negative=['스파이더맨'], topn=1))
---
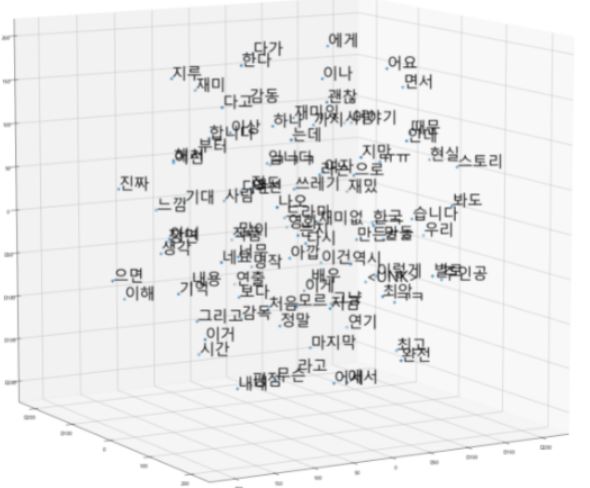
[('아이언맨2', 0.48837676644325256)]Visualize word embedding with T-sne
| T-sne | skipgram | Pretrained -Fasttext |
|---|---|---|
| 2 dim | 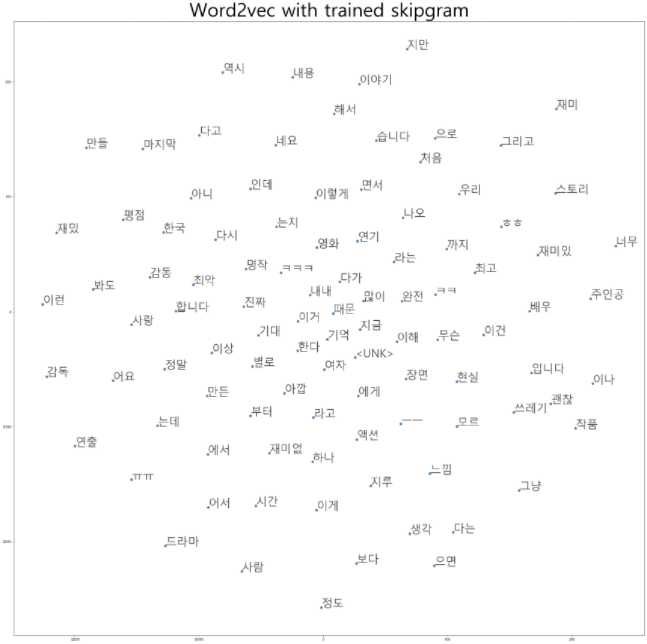 | 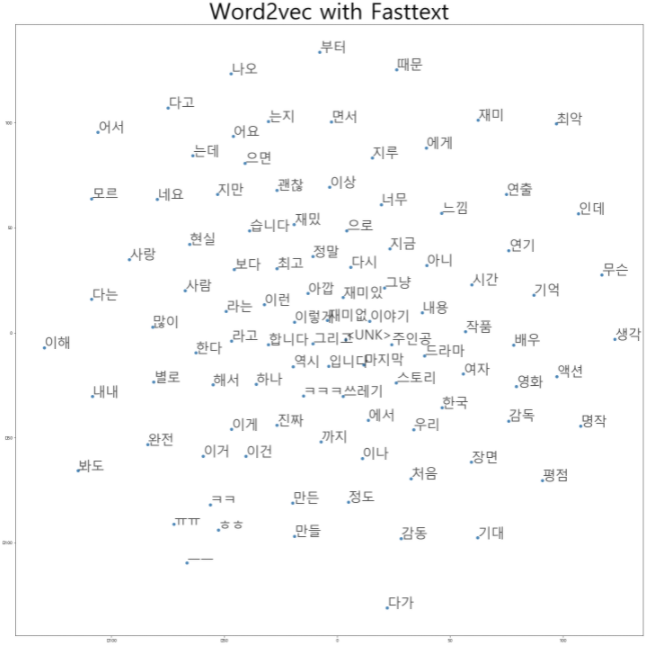 |
| 3dim | 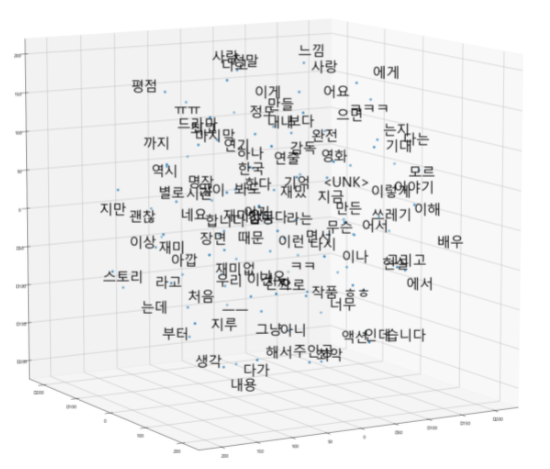 | 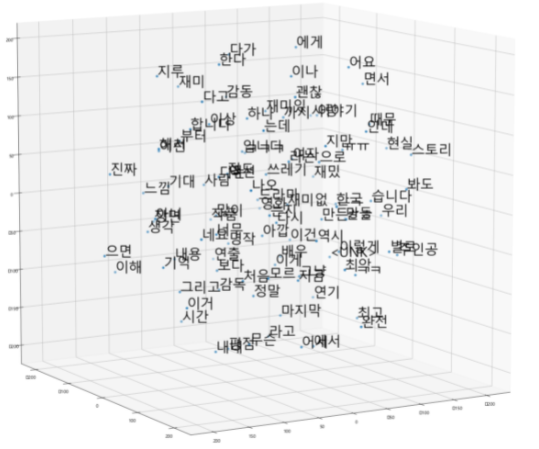 |
Fasttext에서 비슷한 단어들끼리 훨씬 잘 분포함을 느낄 수 있었습니다
- 출처
Naver 영화 리뷰 댓글 데이터 - https://github.com/e9t/nsmc/
Fasttext - https://fasttext.cc/docs/en/crawl-vectors.html
