DeepLearning
1.딥러닝을 활용한 자연어처리 개요

자연어 처리(Natural Language Processing) 사람의 언어를 컴퓨터가 알아듣도록 처리하는 인터페이스 딥러닝의 의해 비약적인 발전을 이루었다 자연어 처리가 어려운 이유 모호성 : 문장 내 정보의 부족으로 인한 모호성 발생 다양한 표현 : 사진 한장을
2.전처리
전처리 전처리 과정 코퍼스 수집 정제 문장 단위 분절 분절 병렬 코퍼스 정렬(생략) 서브워드 분절 Corpus 말 뭉치 라고도 불리며 여러 단어들로 이루어진 문장을 의미한다 단일 언어 moonolingual , 이중 언어 bilingual, 다중 언어 multil
3.유사성과 모호성
유사성과 모호성 단어의 의미 겉으로 보이는 형태 내에 여러 의미를 포함함 사람은 주변 정도에 따라 단어의 의미 파악 다르게 해석한 경우, 잘못된 의미로 이해 모호성을 발생시키는 어휘 동형어(Homonym) : 형태는 같으나 뜻이 서로 다른 단어 다의어(Polyse
4.단어 임베딩
차원 축소 높은 차원에서 데이터 표현시 희소성 문제발생. 같은 정보를 표현할 때 더 낮은 차원을 사용하는 것이 중요 PCA(Principal component analysys) 대표적인 차원 축소 방법으로 고차원을 저차원으로 축소한다. 주성분의 조건 투사점들의 사이
5.시퀀스 모델링
Sequential Modeling 기존 : $y= f(x)$ 시간 개념 또는 순서 정보를 사용하여 입력을 학습하는 것 RNN(Recurrent Neural Network) 순환 신경망(RNN)은 입력 xt와, 직전의 은닉 상태hidden state인 ht-1를 참
6.텍스트 분류
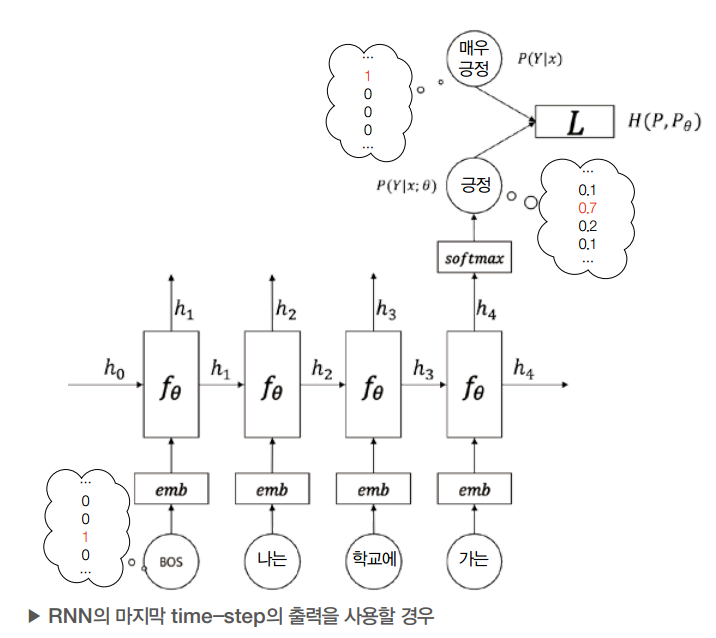
Text classification Naive Bayes 딥러닝을 적용하기 이전에 가장 간단한 부류 방식 Baye's Theorem: 데이터 D가 주어졌을 때 , 각 클래스 c의 확률 $P(D|c) \times P(c)$ 를 통해 Class 'Y' 예측 $P(
7.konlpy mecab 설치 window
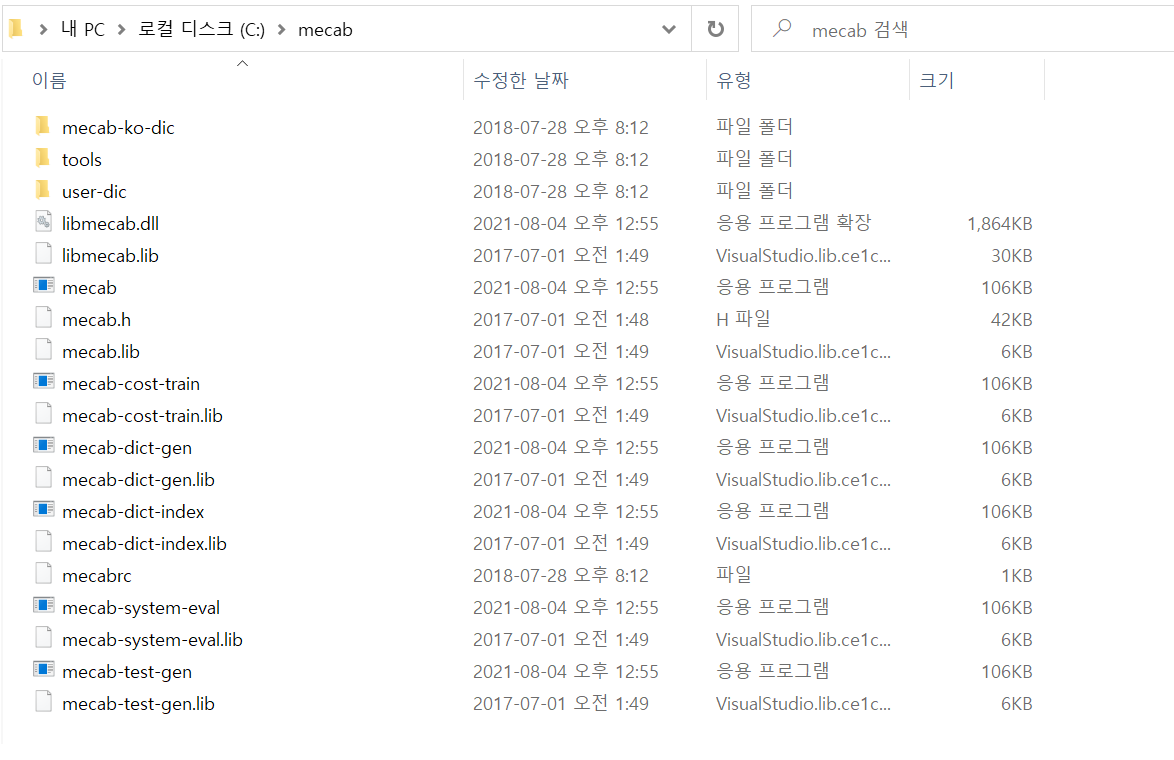
mecab-ko-msvc 설치 1.https://github.com/Pusnow/mecab-ko-msvc/releases/tag/release-0.9.2-msvc-3 2.pc window 버전에 맞는 파일 설치 3.C 드라이브에 mecab 폴더 생성 : c:\me
8.Attention & Transformers
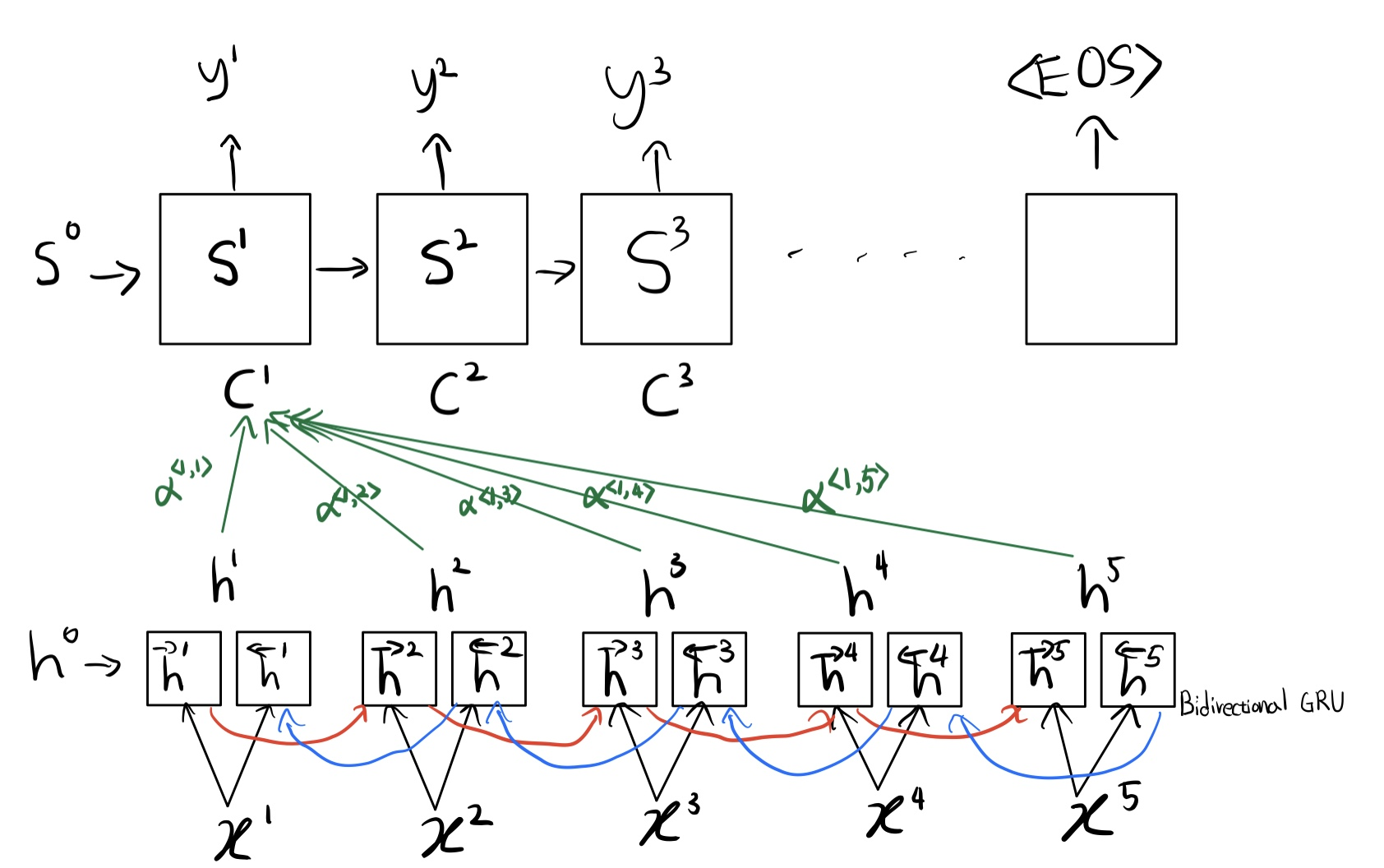
Sequence to Sequence model은 sequence를 입력으로 받아 다른 도메인의 sequence를 출력으로 반환하는 모델으로 Machine Translation, Chatbot,Text Summarization, Speech to Textr 등에서 사용
9.Word2Vec- skip gram &Fasttext (네이버 영화 리뷰 댓글 데이터)
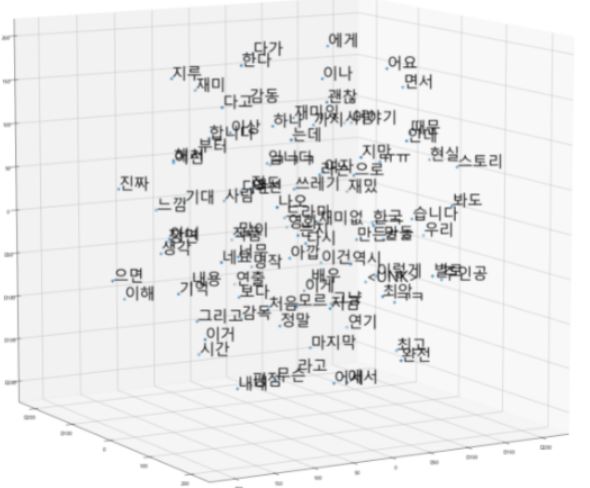
Word2Vec word embedding에 사용되는 Word2vec에는 skipgram,cbow,negative sampling-skipgram, glove, gensim,fasttext 등이 있습니다 효과적인 word2vec학습을 위해서는 충분한 데이터양이 필요한