차원 축소
- 높은 차원에서 데이터 표현시 희소성 문제발생. 같은 정보를 표현할 때 더 낮은 차원을 사용하는 것이 중요
PCA(Principal component analysys)
대표적인 차원 축소 방법으로 고차원을 저차원으로 축소한다.
주성분의 조건
1. 투사점들의 사이가 서로 최대한 멀어져야 함
2. 투사된 거리가 최소가 되어야함

불가피하게 정보의 손실이 생길 수 밖에 없고 너무 많은 정보가 손실되면 효율적으로 데이터를 사용할 수 없다, 따라서 고차원 정보를 지나치게 저차원으로 축소하여 표현하기가 어렵다
Manifold assumption
높은 차원에 존재하는 데이터들의 경우, 실제로는 해당 데이터들을 아우르는 낮은 차원의 다양체(manifold)가 존재한다.
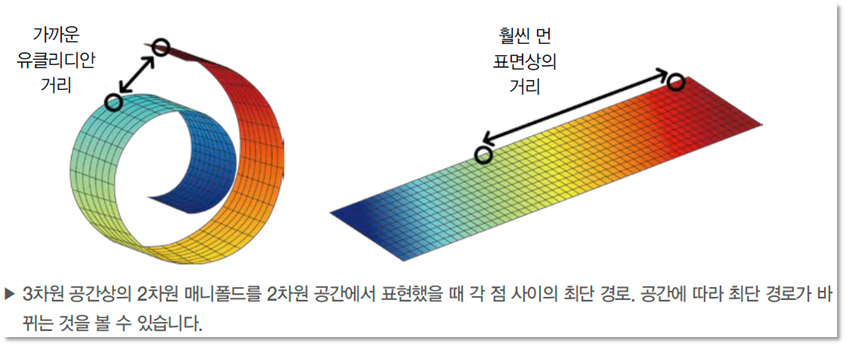
- PCA 와 같은 선형적인 방식에 비해 Deep Learning 은 비선형적인 방식으로 차원 축소를 수행하며, 가장 잘 해결하기 위한 Manifold를 잘 찾는다.
Word2Vec
Word Embedding을 포함한 NNLM의 느린 학습 속도와 정확도를 개선한 것
word2vec을 통해 얻은 단어 임베딩 벡터가 훌륭하게 단어의 특징을 잘 반영하고 있지만 모든 Task에서 문제를 해결할 수 있는 최적의 임베딩 벡터는 아니다.
Task 목적에 따른 임베딩 벡터를 형성해야 Task에 맞는 최적의 임베딩 벡터를 형성할 수 있다.
- Word2Vec 없이 신경망 훈련하기
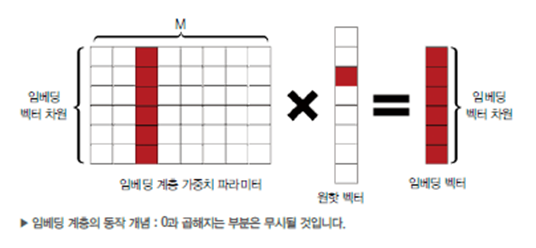
Embedding Layer 제공
복잡한 신경망 네트워크를 사용해 임베딩 벡터를 형성하는 데 의문을 가지면서 빠르고 쉬우면서 효율적으로 Embedding을 수행하는 Word2Vec을 제시
CBOW & Skip-gram
- 두 가지 Word2Vec 방법으로 모두 함께 등장하는 단어가 비슷할 수록 비슷한 벡터 값을 가질 것이라는 가정을 전데.
- 두 방법 모두 윈도우 크기가 주어지면 특정 단어를 기준으로 윈도우 내의 주변 단어를 사용하여 단어 임베딩을 학습
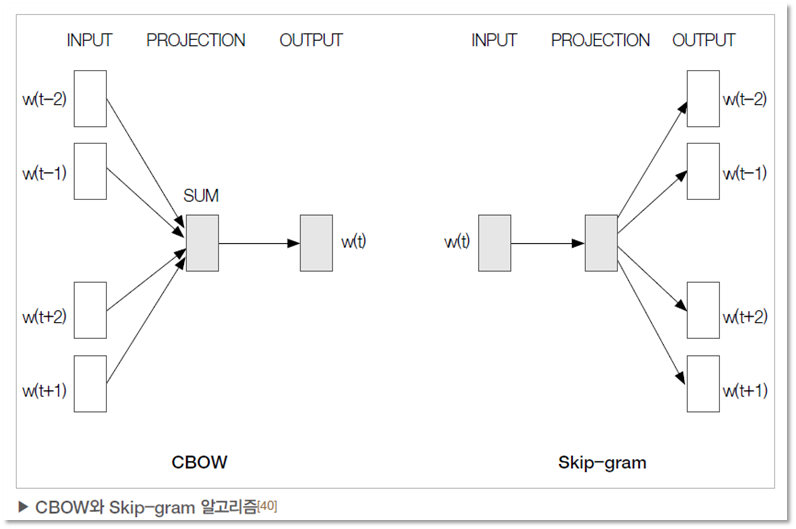
CBOW : 주변 단어를 원핫인코딩 벡터로 받아 대상 단어를 예측
Skip-gram : 대상 단어를 원핫인코딩 벡터로 받아 주변 단어를 예측
- Skip-gram : MLE를 통해 argmax 내의 수식을 최대로 하는 를 찾는다
Glove( Global Vectors for word representation)
Glove는 대상 단어에 대해서 corpus와 함께 나타난 단어별 출현 빈도를 예측
skip-gram 네트워크와 유사하며 분류 문제가 아니라 출현 빈도를 근사하는 회귀 문제이기 때문에 MSE를 사용하여 최적화
Skip-gram 과 달리 Glove는 처음 코퍼스를 통해 단어별 동시 출현빈도를 조사하여 그에 대한 출현 빈도 행렬을 만들고, 이후에는 해당 행렬을 통해 동시 출현 빈도를 근사하려 한다.
따라서 코퍼스 전체를 훑으며 대상 단어와 주변 단어를 가져와 학습하는 skip-gram과 달리 훨씬 학습이 빠르다
Word2Vec 예제
- Gensim : 공개 연혁이 상대적으로 오래 됨, FastText보다 느림
- FastText : 페이스북에서 공개한 라이브러리로 빠른 속도를 자랑
