자연어 처리(Natural Language Processing)
사람의 언어를 컴퓨터가 알아듣도록 처리하는 인터페이스
딥러닝의 의해 비약적인 발전을 이루었다
자연어 처리가 어려운 이유
- 모호성 : 문장 내 정보의 부족으로 인한 모호성 발생
- 다양한 표현 : 사진 한장을 보고 다양한 문장을 만들 수 가 있다
- 불연속적인 데이터 :
딥러닝에 적용하기 위하여 연속적인값으로 바꿔줘야 한다(단어 임베딩으로 변형하지만 여러 제약이 존재한다)
희소성 문제(단어 임베딩으로 적절한 수의 차원으로 축소한다),
노이즈와 정규화(데이터가 살짝 바뀌어도 의미변화가 크다, 단어가 바뀌면 전체 의미가 달라진다, 띄어쓰기, 어순 등의 처리 필요)
한국어 자연어처리를 어려운 이유
-
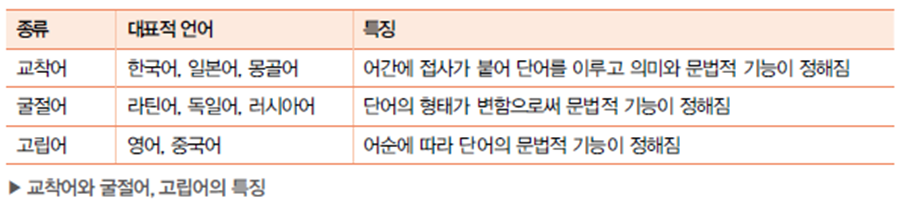
교착어 : 어근(의미) + 접사(문법)로 구성
-
굴절어 : 어근의 형태가 바뀜
-
교착어
- 어근 + 접사가 다양한 형태로 결합- 파싱, 형태소 분석, 언어 모델링 등에서 문제를 어렵게 만듬
- 접사로 인하여 비슷한 의미의 단어가 다수 발생
- 분절을 통하여 어근과 접사를 분리
- 어순은 상대적으로 중요하지 않다
-
띄어쓰기
- 동양권 언어에서 띄어쓰기는 근대에 들어서면서 도입되었다
- 띄어쓰기에 대한 표준이 계속 변화
- 추가적인 분절을 통해 띄어쓰기를 정제해주는 과정이 필요
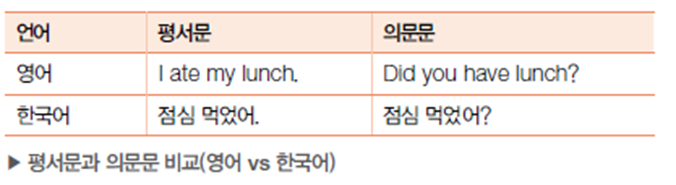
-평서문과 의문문
- 의문문과 평서문이 같은 형태의 문장 구조를 가짐
- 마침표나 물음표가 붙지 않으면 구분이 안됨
- 음성 인식의 결과물로 나오는 텍스트는 더욱 어려움
-
주어 생략
- 영어 : 명사의 역할이 중요, 주어 생략이 없음- 한국어 : 동사의 역할이 중요, 주어가 자주 생략
-
한자 기반의 언어
- 한자의 조합으로 이루어지는 단어가 많다
- 한글이 한자를 대체하면서 문제 발생(표의문자가 표음문자로 바뀌면서 정보 손실 발생)
자연어 처리 최근 추세
딥러닝의 자연어 처리 정복
-
Rnn을 활용한 언어 모델링 시도(2010) : n-gram 방식과의 결합하여 성능 향상
-
word2vec 개발(2013) : 단순한 구조의 신경말 사용,단어들을 잠재 공간( latent space)에 투사
-
Cnn으로 텍스트 분류(2014): 딥러닝으로 형태소 분석, 문장 파싱, 개체명 인식, 의미역 결정 등의 언어처리 문제 해결
-
자연어 생성(Natural language Generation)(2014) : seq2seq + attention-> NMT(Neural Machine Translation)
-
메모리를 활용한 심화 연구(Neural Turing Machine) : 여러 주소에서 연속적으로 정보를 읽고 쓰는 방법을 제시
-
강화학습의 자연어 처리 분야에 대한 성공적인 적용 : 강화학습을 활용하여 SeqGan
