Web Crawling

Web Crawling vs Web Scraping
🪱 웹 크롤링은 말 그대로 웹을 기어다닌다는 의미로, 전체 웹사이트의 구조와 링크를 따라가며 데이터를 수집하는 것이다.
👓 웹 스크래핑은 크롤링과 달리 특정 웹페이지에서 필요한 정보만을 선택적으로 추출하는 것을 말한다.
웹 크롤링이 조금 더 대규모의 데이터를 수집한다는 점에서 차이가 있지만 두 용어를 혼용하여 많이 사용하는 듯 하다.
Web Crawling Process
웹 크롤링의 절차는 크게 아래 세 과정을 거쳐 진행된다.
- HTML 소스코드 불러오기
- HTML 소스코드 파싱하기
- 원하는 정보 추출하기
1. HTML 소스코드 불러오기
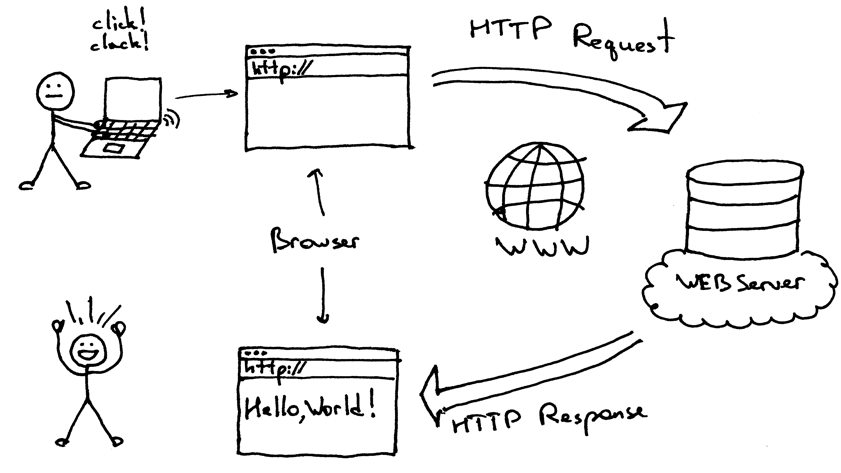
위 그림은 우리가 원하는 웹페이지를 불러와 받는 과정이다.
https://www.naver.com와 같은 도메인 주소를 웹 서버에 요청(Request)하면 웹 서버에서는 요청 받은 주소에 해당하는 웹 페이지 정보를 사용자에게 전달(Response)한다.
우리가 얻고자 하는 HTML 소스코드도 웹 서버가 보낸 정보에 포함되어 있고, 이는 웹페이지에서 F12 혹은 오른쪽 클릭 후 '페이지 소스 보기' 클릭을 통해 쉽게 확인해볼 수 있다.
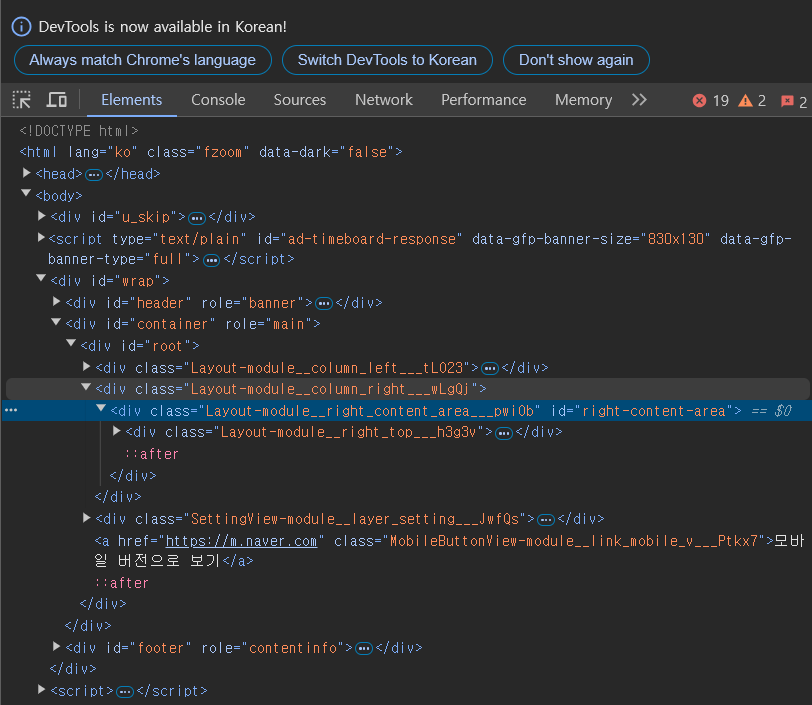
이 코드가 웹 서버로부터 받은 HTML 소스코드이고, 해당 코드를 바탕으로 우리가 웹페이지를 볼 수 있는 것이다.
이 HTML 소스코드를 파이썬으로 불러오기 위해 Requests 모듈을 사용할 것이다.
import requests
response = requests.get('https://www.naver.com/')requests.get(url)은 웹 서버에 url을 요청후 받은 서버의 응답 정보를 파이썬 객체로 받아온다. 해당 객체는 응답코드, HTML 소스코드, 인코딩 정보 등을 담고 있으며 아래와 같이 확인해볼 수 있다.
#응답코드
response.status_code
#HTML 소스코드
response.text
#인코딩 정보
resonse.encoding2. HTML 소스코드 파싱하기
❓ 그런데,, 파싱이 뭔가요,,,?
🎨파싱(Parsing)은 언어에서 구문을 분석하는 것을 말한다. 예를 들면 "나는 햄버거를 먹는다."라는 문장에서 주어는 "나는", 목적어는 "햄버거를", 서술어는 "먹는다"라고 분석하는 것이다. 따라서 HTML에서 소스코드를 파싱한다는 것은 HTML 소스코드의 문법을 분석한다는 것과 같은 말이다.
이 파싱을 도와주는 라이브러리로 BeautifulSoup가 존재한다.
import requests
from bs4 import BeautifulSoup
html = requests.get("https://www.naver.com/").text
soup = BeautifulSoup(html, 'html.parser')위 코드는 requests를 통해 가져온 html 소스코드를 'html.parser'라는 파서(parser)로 파싱 후 BeautifulSoup 객체로 만들어 soup에 할당한 것이다. 즉 soup에는 해당 주소의 html 정보가 담긴 것이다.
3. 원하는 정보 추출하기
BeautifulSoup에서는 html을 파싱한 후 해당 정보를 바탕으로 정보를 추출할 수 있는 방법들을 제공하며, 다음은 BeautifulSoup에서 정보 추출에 가장 많이 쓰이는 것들이다.
📌 .find(tag, attrs)
tag, attrs 조건에 맞는 첫 번째 태그 및 자식 태그를 모두 가져온다.#class가 'news_tit'인 첫 번째 ul 태그 및 자식 태그를 가져옴 soup.find('ul', attrs={'class':'news_tit'})📌.find_all(tag, attrs)
tag, attrs 조건에 맞는 모든 태그를 가져와 리스트로 저장한다.
📌.text
html 태그를 제거해준다.<span class="NewsList_title__DgFuU">[올림픽] 안세영 "부상에 안일했던 대표팀 실망…계속 가기 힘들 수도"(종합)</span>위와 같은 태그가 news_title에 저장되었을 때 아래와 같이 작성하면
news_title.text[올림픽] 안세영 "부상에 안일했던 대표팀 실망…계속 가기 힘들 수도"(종합)태그를 제외한 텍스트 정보만 추출된다.
📌.get(key)
html 태그의 속성 정보를 가져올 수 있다.news_title.get('class') #NewsList_title__DgFuU
Practice
💡 Yes24에서 도서 URL를 크롤링 해보자❕
우선 BeautifulSoup 클래스와 requests 모듈을 import하고, url에 대한 서버의 응답 정보를 response에 담는다.
from bs4 import BeautifulSoup
import requests
url = "https://www.yes24.com//Mall/Main/Book/001?CategoryNumber=001"
response = requests.get(url)다음은 응답코드를 확인하여 200인지 확인하는 코드로, 해당 코드가 200일 때 크롤링을 진행하도록 한다.
🔢응답코드(Status Code)
서버에서의 요청에 대한 처리 결과를 세 자리의 숫자로 나타내주는데, 이 세 자리 숫자를 응답코드(Status Code)라고 한다.( 번호 별 세부적인 의미를 갖고 있지만 특히 200번은 정보를 성공적으로 처리했음을 의미하는 코드이므로 여러모로 알아두면 쓸모있지 않을까 싶다. )
코드 의미 1XX Informational → 정보제공 2XX Success → 처리 성공 3XX Redirection → 리다이렉션 4XX Client Error →클라이언트 에러 5XX Server Error → 서버 에러
if response.status_code == 200:
print("웹 페이지를 성공적으로 가져왔습니다.")
else:
print("웹 페이지를 가져오는 데 실패했습니다.")응답 내용(response)을 BeautifulSoup 객체로 파싱한다.
soup = BeautifulSoup(response.text, 'html.parser')HTML 소스코드에서 a태그의 링크들이 공통적으로 갖는 'bgCateM' 클래스를 찾아 해당 링크들을 스크래핑한다.
a_list = soup.find_all('a','bgCateM')
part_url_list = list(map(lambda x: x.get('href'), a_list))
print(part_url_list)['javascript:void(0);', 'javascript:void(0);', '#', '#', '/Product/Goods/129366202', '/Product/Goods/129094642', '/Product/Goods/128902305', 'javascript:void(0)', '/Product/Goods/128712025', '/Product/Goods/129060701', '/Product/Goods/129060449', '/Product/Goods/129366517', '/Product/Goods/126845471', '/Product/Goods/115083494', '/Product/Goods/125992096', '/Product/Goods/63038113', '/Product/Goods/129422847', '/Product/Goods/129479023', '/Product/Goods/129369207', '/Product/Goods/67094041', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', '/Product/Goods/129085141', '/Product/Goods/128938074', '/Product/Goods/128914849', '/Product/Goods/128869653', '/Product/Goods/129368125', '/Product/Goods/129374769', '/Product/Goods/129080531', '/Product/Goods/129383425', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', '/Product/Goods/128849823', '/Product/Goods/127261797', '/Product/Goods/128850058', '/Product/Goods/129368189', '/Product/Goods/124999476', '/Product/Goods/127766405', '/Product/Goods/128120256', '/Product/Goods/127067698', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', '/Product/Goods/129063553', '/Product/Goods/129120227', '/Product/Goods/129392822', '/Product/Goods/129775270', '/Product/Goods/129060654', '/Product/Goods/128818096', '/Product/Goods/129391394', '/Product/Goods/129144880', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', '/Product/Goods/129123348', '/Product/Goods/129375440', '/Product/Goods/129392568', '/Product/Goods/129479023', '/Product/Goods/129365542', '/Product/Goods/129109015', '/Product/Goods/129132445', '/Product/Goods/129053063', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', 'javascript:void(0);', 'https://www.yes24.com/product/goods/128724816', 'https://www.yes24.com/product/goods/125131585', 'https://www.yes24.com/product/goods/126011798', 'https://www.yes24.com/product/goods/125075376', 'https://www.yes24.com/product/goods/128071226', 'https://www.yes24.com/product/goods/128548452', 'https://www.yes24.com/product/goods/128193282', 'http://www.yes24.com/24/goods/128860445', 'https://www.yes24.com/product/goods/118204268', 'https://www.yes24.com/product/goods/116604749', 'https://www.yes24.com/product/goods/125830202', 'https://www.yes24.com/product/goods/123054441', 'javascript:void(0);', 'javascript:void(0);']🕹️lambda 함수
람다 함수는 다음과 같은 형태로 정의한다.
lambda 인자: 표현식
람다 함수는 함수를 기존의 def보다 간단하게 정의하고 사용하기 위해 고안되었다.
따라서 아래의 def 함수는 람다 함수로 표현할 때 더 간단하게 표현할 수 있다.def sum(x,y): return x+ysum = lambda x,y: x+y이때 sum은 람다 함수를 참조하게 된다.
위 코드의 출력을 보면 javascript:void(0);, #, /Product/Goods/129366517 등 다양한 형태로 수집된 것을 볼 수 있다. 이들 중 /Product/Goods/129366517가 URL에서 보이는 경로와 유사하게 생긴 것을 알 수 있고, 실제로 https://www.yes24.com//Product/Goods/129366517 경로로 이동하면 도서 구매 페이지로 이동한다.
따라서 part_url_list 요소들 중 Product/Goods를 포함하는 요소들만 따로 추출하기로 한다.
url_list = []
full_url = 'https://www.yes24.com'
for part_url in part_url_list:
if '/Product/Goods' in part_url:
url = full_url + part_url
url_list.append(url)url_list에는 도서 구매 페이지로 이동하는 전체 경로가 담기게 된다.
