Dynamic Crawling

Static vs Dynamic
🪨 정적(Static) 크롤링은 말 그대로 정적인 데이터를 크롤링하는 것을 말한다. 이때 정적인 데이터는 변하지 않는 데이터로, 웹 페이지 상에서 url의 변화없이 그대로 수집가능한 데이터이다.
🏃♂️ 동적(Dynamic) 크롤링은 정적 크롤링과 달리 url의 변화가 필요한 데이터를 크롤링하는 방법을 말한다. 만일 네이버 메일 내용을 크롤링해야 한다면 네이버 로그인이 필요하고, 이때 로그인 후 메일 내용을 크롤링하는 과정이 동적 크롤링인 것이다. url이 고정되지 않고 변화함으로 정적 크롤링에 비해 상대적으로 오래 걸린다.
Selenium
Selenium은 웹 어플리케이션 테스트를 자동화하기 위해 고안된 프레임워크이지만, 동적 웹 크롤링에서 웹을 동작시키는 데에 매우 유용하다. 동적 크롤링을 할 시에 로그인을 해야하는 경우, 마우스 호버(Hover)나 스크롤 다운 등의 웹의 동작으로만 정보가 등장하는 경우에 selenium을 사용하면 된다.
다음은 selenium에서 자주 사용되는 것들이다.
📌 .get(URL)
해당 URL로 이동한다.
📌 .find_element(By.~, " ")
~에는 CLASS_NAME, ID, CSS_SELECTOR, TAG_NAME, XPATH 등의 HTML 태그 속성(attribute)이 쓰일 수 있고 " "에는 해당 속성의 값(value)가 쓰인다. 해당 메서드는 인자로 받은 조건을 바탕으로 요소를 찾는 역할을 한다.
만약 ID가 'jyoung'인 요소를 찾아 선택하고 싶다면 아래와 같이 작성하면 된다.jyoung = driver.find_element(By.ID, "jyoung")📌 .click()
말 그대로 요소를 클릭해준다.
앞선 예시의 jyoung 요소를 클릭하고 싶다면 아래와 같이 작성하면 된다.jyoung.click()📌 .send_keys(key)
요소에 정보를 보내주는 역할을 한다.
만약 id가 'search_bar'인 검색창에 '딥다이브'를 검색하고자 한다면 아래와 같이 작성하면 된다.search = driver.find_element(By.ID, 'search_bar') search.send_keys('딥다이브')📌 .page_source
웹 페이지의 html 소스 코드를 가지고 오는 역할을 수행한다.
❓ selenium으로 소스코드를 가져올 수 있는 거라면 굳이 requests를 사용해야 할까요?
실제로 Selenium만 가지고도 웹 크롤링은 가능하다. 그러나 Selenium은 무겁기에 반복 작업이 많아질수록 속도가 매우 느려지는 단점을 가지고 있다. 따라서 최대한 Selenium을 동적 크롤링을 위한 도구로써만 사용하며 필요에 따라 적절히 혼용해 사용하는 것이 좋을 듯하다.
Practice
💡 파리 2024 올림픽 네이버 뉴스 기사 제목을 수집해보자!
우선 필요한 프레임워크, 라이브러리, 모듈을 불러오자.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
import requests
import sys
import os
import time동적 웹 크롤링을 위해 webdriver를 통해 크롬을 열어줘야 한다.
webdriver는 파이썬으로 웹 브라우저를 제어할 수 있도록 해준다.
driver = webdriver.Chrome()해당 코드를 실행시키면 자동화된 소프트웨어로 제어된다는 문구가 나오며 크롬이 자동으로 열리게 된다.
다음으로 드라이버로 파리올림픽 뉴스 페이지(https://m.sports.naver.com/paris2024/news?date=20240803&sort=popular&isPhoto=N)로 접속 후 페이지 소스 코드를 불러오자.
url = "https://m.sports.naver.com/paris2024/news?date=20240803&sort=popular&isPhoto=N"
driver.get(url)
html = driver.page_source아주 잘 접속한 것을 볼 수 있다😎
해당 웹페이지를 개발자도구로 살펴보면
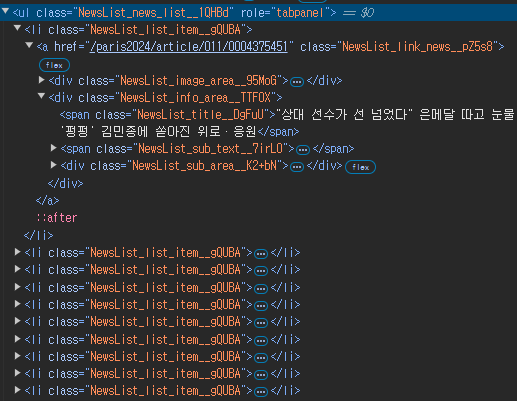
class가 "NewsList_news_list__1QHBd"인 ul 태그 안에 class가 "NewsList_list_item__gQUBA"인 li 태그들이 담겨있는 것을 볼 수 있다. 이 li 태그 안에 뉴스 기사 정보가 담겨있는 것이다.
여기서 뉴스 기사 제목을 수집하는 과정은 다음과 같다.
- 앞서 가져온 소스코드를 활용하여 BeautifulSoup 객체 생성
- 뉴스 기사를 담은 li 태그들을 감싼 ul 태그를 find로 선택
- 선택한 ul에서 li 태그들을 find_all로 모두 가져오기
- map 함수를 활용하여 제목만을 추출후 리스트에 저장
# 앞서 가져온 소스코드를 활용하여 BeautifulSoup 객체 생성
soup = BeautifulSoup(html, 'html.parser')
# 뉴스 기사를 담은 li 태그들을 감싼 ul 태그를 find로 선택
news_section = soup.find('ul','NewsList_news_list\__1QHBd')
# 선택한 ul에서 li 태그들을 find_all로 모두 가져오기
news_tag_list = news_section.find_all('li', 'NewsList_list_item__gQUBA')
# map 함수를 활용하여 제목만을 추출후 리스트에 저장
news_title_list = list(map(lambda x: x.find('span', 'NewsList_title__DgFuU').text, news_tag_list))['"상대 선수가 선 넘었다" 은메달 따고 눈물 \'펑펑\' 김민종에 쏟아진 위로·응원',
'"왜 우리만 의심하나" 中선수 폭발…파리서도 미∙중 갈등, 무슨 일',
'“상대 선수, 선넘었다”…은메달 따고 눈물 펑펑 김민종에 쏟아진 응원',
"금메달 따고 동성 연인에 달려가 쪽…伊유도선수 '깜짝 세리머니'",
'“올림픽 정신은 어디로?”...징계받은 조지아 유도 선수, 대체 어땠길래',
"신유빈 '천적' 잡고 동메달 기회…'손목 부상' 하야타, 기권 가능성도",
'금메달 딴 뒤 짝꿍에 청혼…한국 꺾은 중 배드민턴 혼복 선수에 환호',
'\'한 발 0점\' 퇴장마저 극적... 김예지 "빅이벤트 선사해 실망 크셨을 것"',
'“돌아가신 엄마 폰에 난 ‘금메달리스트’”...정나은, 銀 걸고 눈물',
'“왜 나만 갖고 그래”…동메달 딴 中 미모의 수영선수 ‘울분’, 무슨일이']잘 된 것만 같지만 이런 의문이 들어야 한다.
🧐 왜 기사 개수가 10개 밖에 없지,,,?
다시 웹페이지로 돌아가보면
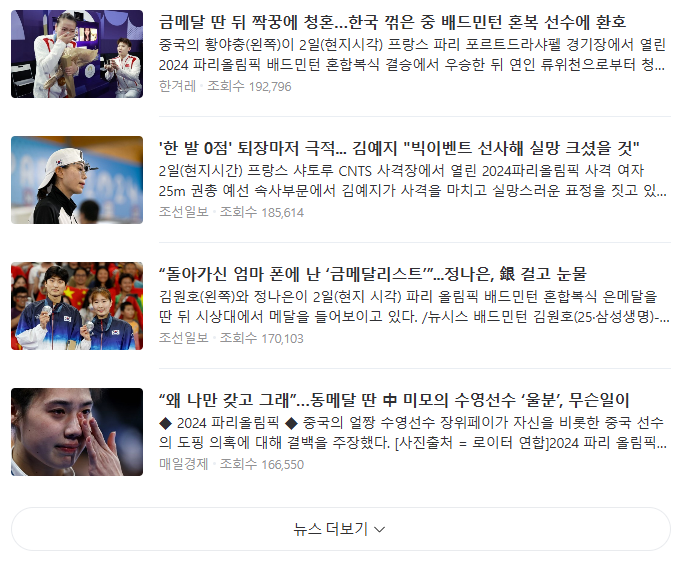
어이쿠,,,🫨 뉴스 더보기를 누르지 않으면 우선 10개의 기사만을 가져오고, 더보기를 눌러야 기사 10개를 더 볼 수 있다. 따라서 기사 50개를 보고싶다면 더보기 버튼을 4번을 눌러야 하는 것이다.😭
이때 ⭐동적 크롤링⭐이 필요한 것이다!!!
더보기 버튼의 button 태그를 개발자 도구에서 우클릭하면 XPATH를 복사할 수 있고, 우리는 이 XPATH로 버튼을 선택할 것이다.
news_more_button = driver.find_element(By.XPATH, "//*[@id="content"]/div[2]/div/div[1]/div[1]/div[2]/button")마지막으로 버튼을 5번 클릭한 후의 크롤링 결과를 보고 마무리하겠다.
n = 0
for i in range(5):
news_more_button.click()
time.sleep(1)
n+=1
print(f'{n}회 클릭했습니다.')
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
news_section = soup.find('ul', 'NewsList_news_list\__1QHBd')
news_tag_list = news_section.find_all('li', 'NewsList_list_item__gQUBA')
news_title_list = list(map(lambda x: x.find('span', 'NewsList_title__DgFuU').text, news_tag_list))
print(f'크롤링한 뉴스 기사의 개수: {len(news_title_list)}') #60🚨 time.sleep()이 필요한 이유
웹 페이지의 내용이 바뀔 때, 문서의 정보가 순식간에 바뀌는 것이 아니라 웹 서버와의 통신 과정에서 작은 딜레이가 발생한다. 따라서 동적 웹 크롤링을 할 때 time.sleep()을 하지 않을 경우 웹 페이지를 불러오기도 전에 다음 코드를 실행하여 오류가 발생하거나 크롤링하고자 하는 정보가 크롤링되지 않는 경우가 발생할 수도 있다.
또한 동적 웹크롤링 시에 반복적인 동작의 웹페이지 접속 등 비이상적인 행동이 감지될 경우 웹페이지에서 봇으로 감지하여 크롤링을 하지 못하도록 웹페이지에서 막을 수도 있다. 이를 방지하기 위해서는 특정 동작을 많이 반복해야 하는 경우, sleep 시간을 고정적으로 하는 것이 아닌 2~6 사이의 랜덤한 정수로 sleep하여 우회하는 방법이 존재한다.
