IRIS
Setosa, Versicolor, Virginica 꽃의 품종을 분류하는 데이터셋인 IRIS 데이터셋을 이용한 딥러닝
데이터 가져오기
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target데이터 전처리
💡One hot encoding
표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 벡터 표현 방식이다. 원핫 인코딩을 적용하기 위해서는 각 범주를 고유한 숫자 값으로 대응시켜야 한다.
타겟 변수인 Setosa, Versicolor, Virginica 0, 1, 2 로 고유한 숫자값으로 표현 되어있다.
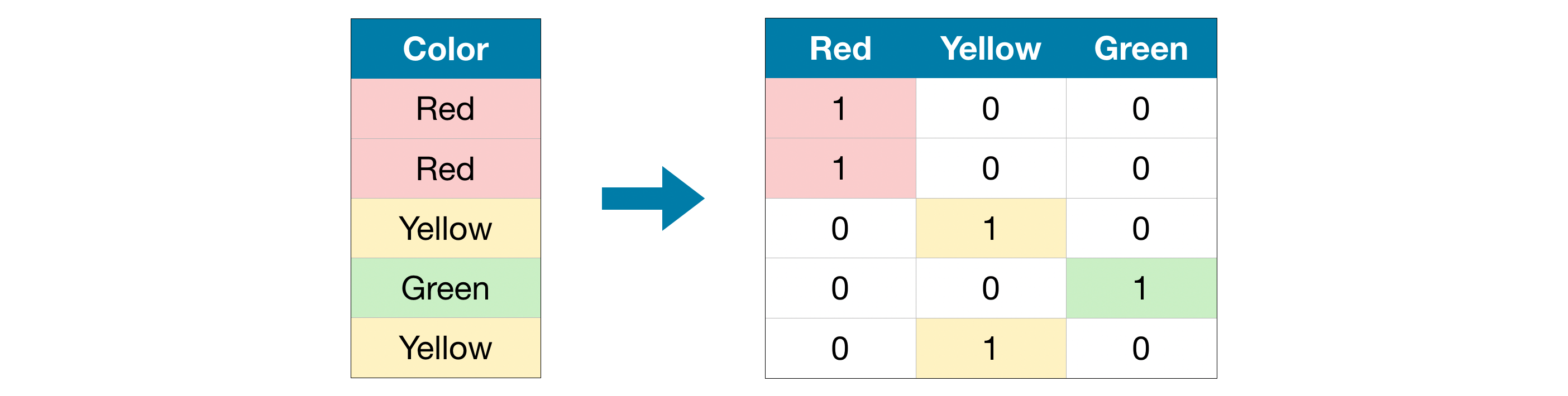
Image by One hot encoding in TensorFlow
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(sparse= False, # 반환되는 희소 행렬을 밀집 배열로 설정
handle_unknown='ignore') # 알려지지 않은 범주를 무시
enc.fit(y.reshape(len(y),1))y_onehot = enc.transform(y.reshape(len(y),1))
y_onehot[::20]array([[1., 0., 0.],
[1., 0., 0.],
[1., 0., 0.],
[0., 1., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.],
[0., 0., 1.]])모델 생성
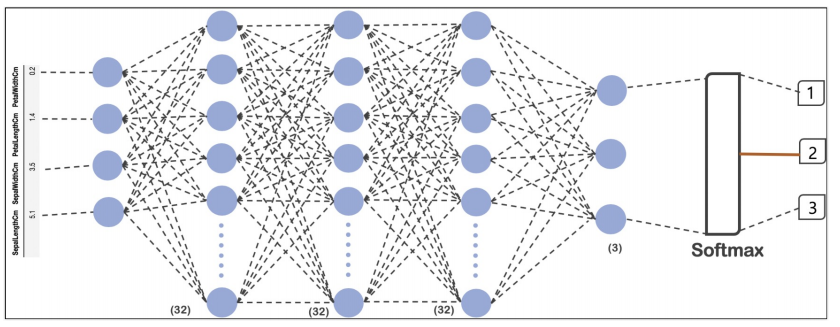
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, input_shape=(4,), activation = 'relu'),
tf.keras.layers.Dense(32, activation = 'relu'),
tf.keras.layers.Dense(32, activation = 'relu'),
tf.keras.layers.Dense(3, activation = 'softmax'),
])model.compile(optimizer = 'adam', loss = 'categorical_crossentropy', metrics = ['accuracy'])
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 32) 160
dense_5 (Dense) (None, 32) 1056
dense_6 (Dense) (None, 32) 1056
dense_7 (Dense) (None, 3) 99
=================================================================
Total params: 2,371
Trainable params: 2,371
Non-trainable params: 0모델 훈련
hist = model.fit(X_train, y_train, epochs = 100)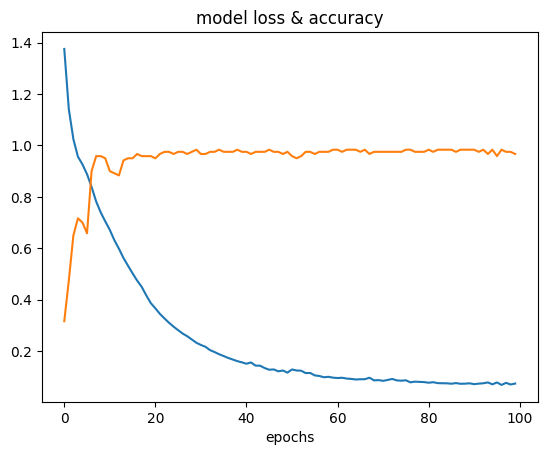
MNIST - handwritten
MNIST는 손으로 쓴 숫자들로 이루어진 대표적인 데이터셋이다.
28x28 픽셀 크기의 흑백 이미지로 구성되어 있다.
모델 생성
OneHot Encoding 대신에 손실 함수 sparse_categorical_crossentropy 을 이용해준다
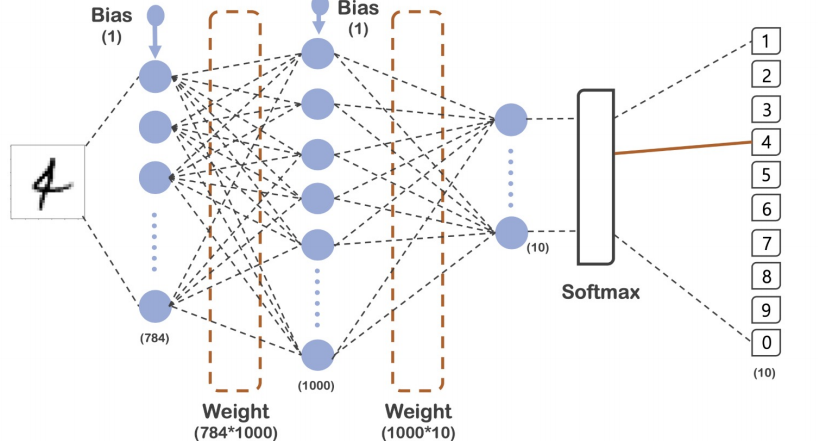
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(1000, activation = 'relu'),
tf.keras.layers.Dense(10, activation = 'softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 1000) 785000
dense_1 (Dense) (None, 10) 10010
=================================================================
Total params: 795,010
Trainable params: 795,010
Non-trainable params: 0
_________________________________________________________________
결과 확인
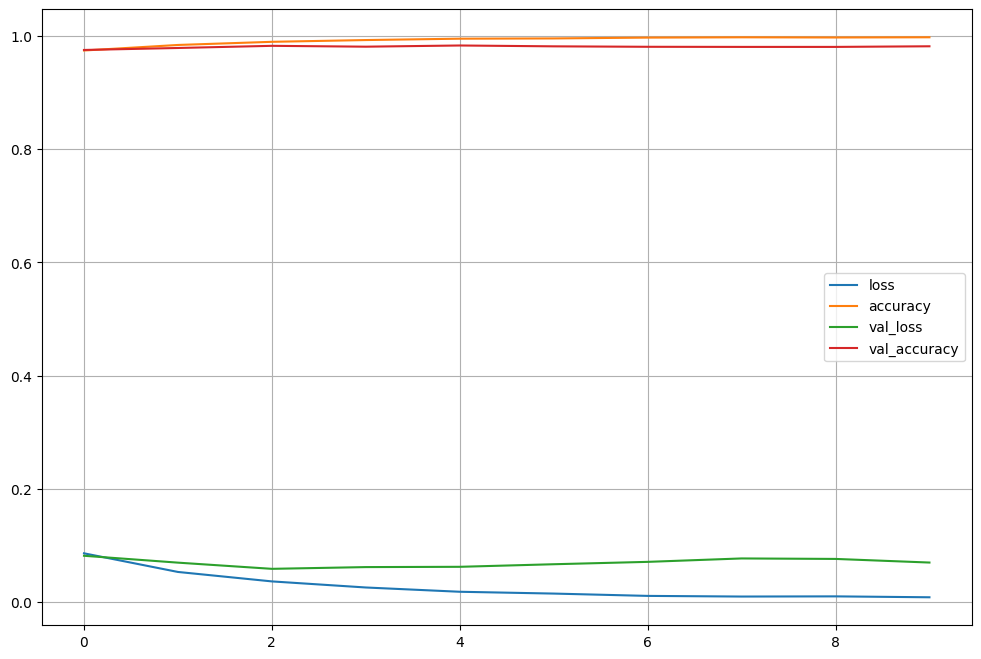
predicted_result = model.predict(x_test)
#0.99999 확률로 7인 수
predicted_result[0]array([3.7143352e-10, 4.3178858e-10, 2.9585712e-10, 3.3190058e-06,
2.0779830e-12, 6.6891874e-11, 2.9610419e-15, 9.9999666e-01,
4.1313983e-11, 4.6481560e-08], dtype=float32)np.argmax 이용하여 예측 라벨 리스트 생성
predicted_label = np.argmax(predicted_result, axis = 1)
predicted_label[:10]samples = random.choices(population = wrong_result, k=10)
plt.figure(figsize=(14, 12))
for idx, n in enumerate(samples):
plt.subplot(4, 4, idx+1)
plt.imshow(x_test[n].reshape(28,28), cmap='Greys')
plt.title('Label: ' + str(y_test[n]) + ' | Predict: ' + str(predicted_label[n]))
plt.axis('off')
plt.tight_layout()
plt.show()

개발하고싶은사람