[DL] SlowFast
SlowFast
video recognition에서 slow motion과 fast motion의 기여도가 다르며 이런 관점에서 spatial structures와 temporal events를 분리해서 봐야한다고 말합니다.
spatial semantics of visual content는 느리게 변합니다. 예를 들어 손을 흔드는 것은 손이라는 identity를 바꾸진 않습니다. 마찬가지로 사람은 사람이 걷다가 뛰더라도 항상 사람입니다. 이런 categorical sementic을 인식하는 것은 상대적으로 느리게 인식됩니다. 반면에 모션은 물체의 identity에 비해 상대적으로 빠르게 변화됩니다.


모델 구조
이런 직관을 통해 Two-pathway SlowFast 모델을 제안합니다.
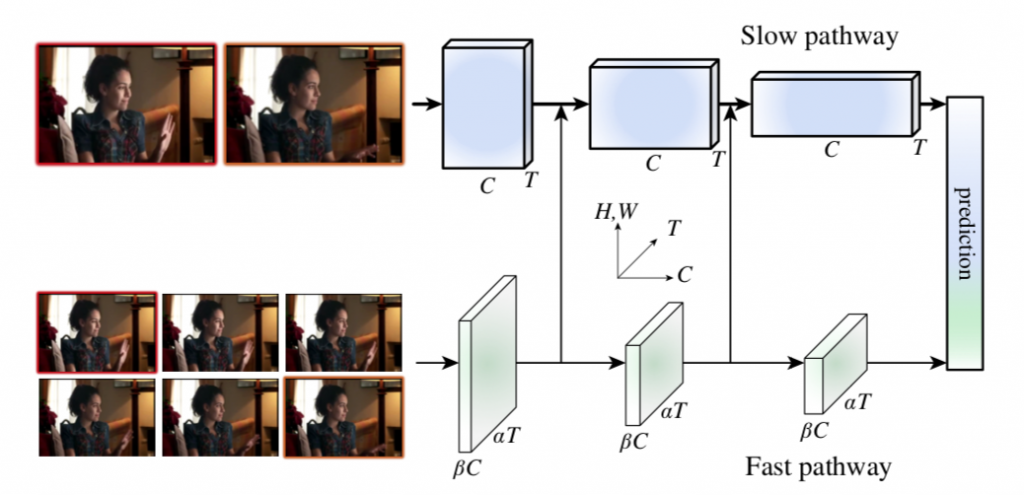
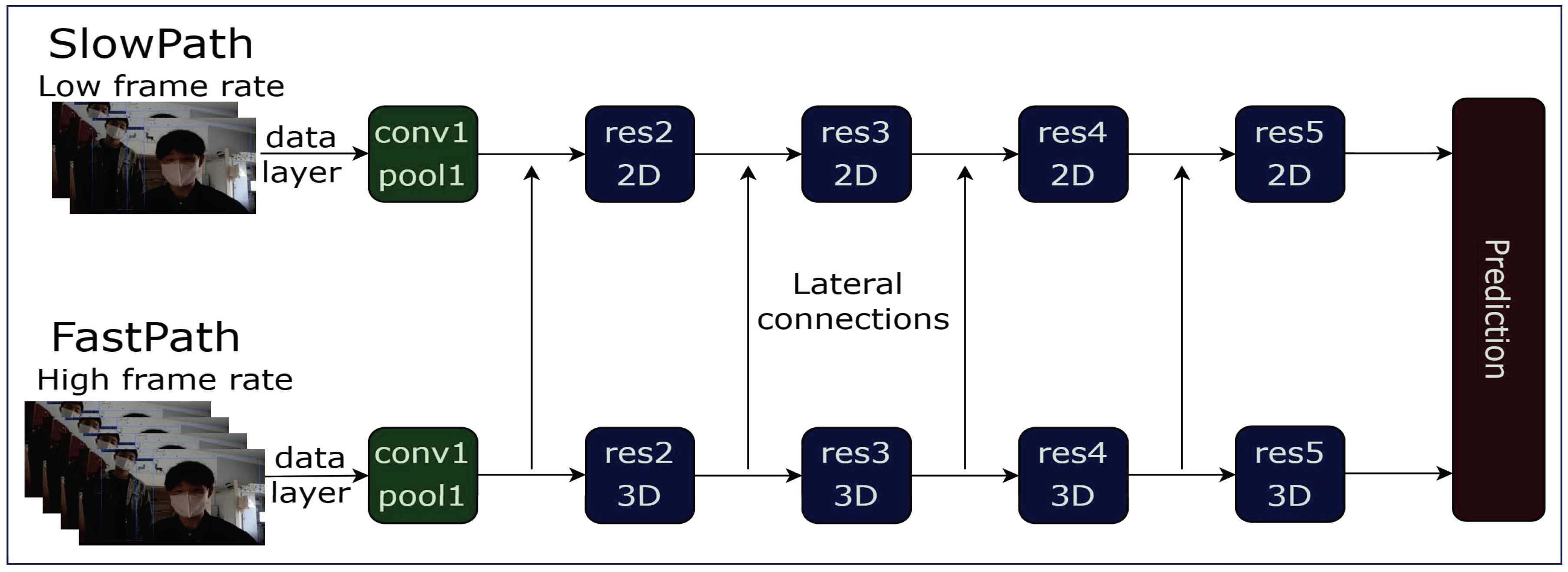
이 모델은 영상 분석을 위한 새로운 접근 방식을 제시하며, Slow pathway와 Fast pathway 두 가지 경로를 활용하여 시맨틱 정보와 빠르게 변하는 모션 정보를 효과적으로 추출하는데 초점을 맞추고 있습니다.
-
Slow pathway : 이 경로는 영상의 시맨틱 정보를 잡아냅니다. 이는 느린 프레임 속도로 변화하는 정보를 포착하는데 적합합니다. (spatial structure)
-
Fast pathway : 이 경로는 고속 업데이트 프레임(높은 시간적 비율)을 통해 빠르게 변하는 모션을 감지합니다. 이를 통해 빠른 움직임에 대한 정보를 빠르게 파악할 수 있습니다. 이 경로는 전체 계산량의 20%를 차지하며, 적은 채널과 공간 정보를 사용하여 설계되었습니다. (temporal events)
기존 optical flow와는 다르게 End-to-End 방식으로 학습이 가능합니다. slow pathway는 전체 계산량의 80%를 차지하고 fast pathway는 전체 계싼량의 20% 를 차지합니다.
두 경로는 lateral connection을 통해 통합됩니다. 즉, 이후에 이들 경로에서 추출된 특징들이 합쳐져 최종적으로 영상을 분석하는데 활용됩니다.
Biological Derivation
이 연구는 뇌의 망막 망상세포(retinal ganglion cells)에 관한 연구 결과에 영향을 받아 모델을 설계한 것으로 나타납니다. 인간의 시각 시스템은 대부분 Parvocellular(P-cells) 및 Magnocellular(M-cells)이라는 두 가지 유형의 망상세포로 이루어져 있는데, 이러한 연구 결과가 모델 설계에 중요한 영향을 미쳤습니다.
M-cells은 높은 시간 주파수에서 연산을 수행하며, 빠르게 변하는 시간적 변화에 민감합니다. 그러나 공간적 디테일이나 색상에는 반응하지 않습니다.
P-cells는 공간적 디테일과 색상에 민감하며, 시간적 정보에는 상대적으로 느리게 반응합니다.
이러한 망상세포의 특성을 기반으로하여 저자는 모델을 설계하였으며, 이 모델은 유사한 결과를 보여줍니다. 특히 주목할 만한 점은 두 경로(Slow와 Fast)의 계산량 비율이 8:2로, 망상세포의 분포 비율(P-cells와 M-cells)과 매우 유사하다는 것입니다. 이는 인간의 시각 인지 시스템을 딥러닝 모델로 구현하고 적용함으로써 좋은 결과를 얻은 사례로 볼 수 있습니다.
Hyper Parameter
본 논문에서 실험을 통해 확인하고 제안하는 Hyper Parameter는 다음과 같습니다.
S = 영상을 정사각형으로 crop한 height 혹은 width 정보
T = Temporal length= 4
α = speed ratio = 8
β = channel ratio = 1/8
τ = temporal stride = 16
- 원본 비디오 클립은 총 T x τ = 64 frame입니다.
Fast pathway에 들어가는 frame은 αT=32, Slow pathway에 들어가는 frame은 T=4입니다
Slow Pathway
- Spatiotemporal volume 을 가지고 있는 any convolution model이 될 수 있음
- 핵심 개념 : input frame의 킨 temporal stride τ (τ frame 마다 하나씩 처리)
- 일반적으로 τ=16 을 사용 (1초당 2 frame sampling )
- Sampling frame 수가 T 라면 raw clip length = T x τ
Fast Pathway
- High frame rate
- Small temporal stride (α>1)을 사용 (α : Fast와 Slow pathway 의 frame rate ratio)
- α = 8 을 일반적으로 사용
- α 의 존재가 SlowFast의 핵심
- Sampling frame = α x T - High temporal resolution feature
- Path 전체의 high resolution 을 유지하기 위해 classification 전의 global pooling 전까지 Temporal downsampling layers (temporal pooling , time-strided convolutions) 사용 X
- 즉, 네트워크 전체에 high resolution feature를 유지 - Low channel capacity
- 좋은 정확도를 달성하기 위해 lower channel capacity 사용한 점에서 다른 model과 구별

참고 자료
SlowFast Networks 리뷰 : ChaCha's blog
SlowFast Networks for Video Recognition 리뷰 : Juns-K's BLOG
Paper Review. SlowFast Networks for Video Recognition@ICCV' 2019 : JooChan Parkg

훌륭한 글 감사드립니다.