LRCN: Long-term Recurrent Convolutional Network
RNN 기반 비디오 분류 모델은 컴퓨터 비전 분야에서 연속적인 이미지로 이루어진 비디오 데이터를 처리하는데 사용되는 모델입니다. 이 모델은 비디오에서 나타나는 변화를 포착하고 시간적 패턴을 학습하여 영상 데이터를 분류하는 역할을 수행합니다. 일련의 이미지 프레임을 입력으로 받아들이고, 이를 순차적으로 처리하여 비디오의 특징을 추출합니다.
RNN은 시간이나 순서가 있는 언어, 음성, 주가 데이터 모델링에 적합하다. RNN의 뉴런은 동일한 레이어에서 정보를 전파라며 입력 데이터 간의 시간 정보를 네트워크에 저장하지만, 기울기 소실과 장기 의존성 등의 문제를 가지고있다. RNN의 단점을 극복하기 위한 방안으로 셀 상태를 저장 할 수 있는 LSTM 셀을 이용한다.
CNN은 네트워크에 단시간 정보를 구현할 수 있지만 전체 데이터의 시간 정보를 모델링하기는 어렵다. 반면 LSTM은 장기간 데이터 모델링에 적합하지만 공간정보를 학습하기 어렵다. 따라서 행동 특성을 추출하고 시간 매커니즘을 파악하기 위해 두 방법을 결합한 LRCN 모델을 사용한다.
LRCN (Long-Term Recurrent Convolutional Networks)
LRCN (Long-Term Recurrent Convolutional Networks)은 이러한 목적을 달성하기 위한 아키텍처로, 합성곱(Convolutional) 레이어와 장기적인 시간적 연속성을 다루기 위한 순환(RNN) 레이어를 조합한 구조입니다. 이 모델은 아래와 같은 특징을 가지고 있습니다:
-
이미지와 시간적 정보 처리: 비디오의 일부 프레임을 선택하여 합성곱 신경망(CNN)을 통과시킨 후, LSTM(RNN의 일종)에 입력으로 전달합니다. 이를 통해 이미지의 공간적 특징과 프레임 간의 시간적 패턴을 함께 학습합니다.
-
LSTM의 활용: LSTM은 순차적인 데이터를 처리하며, 이전 시간 단계에서의 정보를 현재 예측에 활용할 수 있습니다. 이를 통해 비디오의 연속성과 순서를 이해하고 분류 결정에 활용합니다.
-
다양한 입력 길이 처리: 비디오의 프레임 수가 다를 수 있기 때문에 LSTM은 다양한 길이의 입력 시퀀스를 처리하는 데 용이합니다.
-
출력 및 예측: 각 입력 프레임에 대한 LSTM 셀은 활동 클래스를 예측하며, 최종 예측은 이들의 평균 또는 다수결 방식으로 결정됩니다.
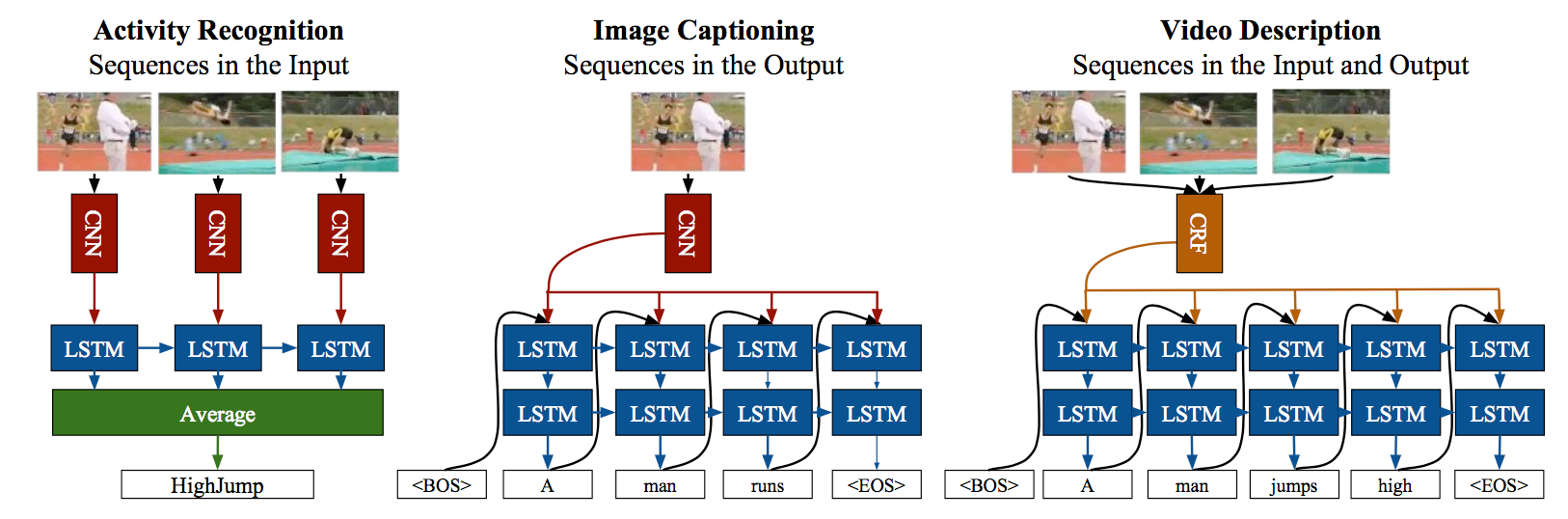
Activity Recognition
Activity Recognition 모델인 LRCN은 비디오에서 각 time step마다 활동 클래스(activity class)를 예측합니다. 각 time step에서의 레이블 확률을 평균하여 전체 비디오 클립에 대한 하나의 레이블을 생성합니다.
Image Captioning
Image Captioning은 하나의 정적 이미지를 입력으로 받는 작업입니다. 각 time step에서 이미지의 특징(feature)과 이전 단어가 LSTM 모델로 전달되며, LSTM은 시간에 따라 변화하는 문장의 동적을 학습하여 캡션을 생성합니다.
Video Description
Video Description은 전통적인 방식의 활동 및 비디오 처리 기법을 사용하여 LSTM의 입력을 생성합니다. 이 방법은 Conditional Random Fields (CRF) 활동 인식 방법으로 비디오 전체 클립에 대한 모든 활동, 도구, 물체, 위치를 인식하고 LSTM의 입력으로 사용합니다. 이 모델은 시간 단계마다 비디오 전체를 참조하며 CRF-max나 CRF-prob 방식을 사용하여 입력을 생성합니다.
-
LSTM Encoder-Decoder : LSTM을 decoder뿐만 아니라 encoder로도 사용하며, one-hot vector를 생성하는 CRF-max 방법을 사용한다.
-
LSTM Decoder (CRF-max) : LSTM은 decoder로 사용하며, 앞 방법과 마찬가지고 CRF-max 방법을 사용한다.
-
LSTM Decoder (CRF-prob) : LSTM은 decoder로 사용하며, 앞 방법과 다르게 one-hot vector가 아니라 probability가 그대로 LSTM의 입력으로 사용된다.
출처
📌 RNN based Video Models
📌 Recurrent Convolutional Networks
📌 LRCN을 이용한 리튬 이온 배터리의 건강 상태 추정
