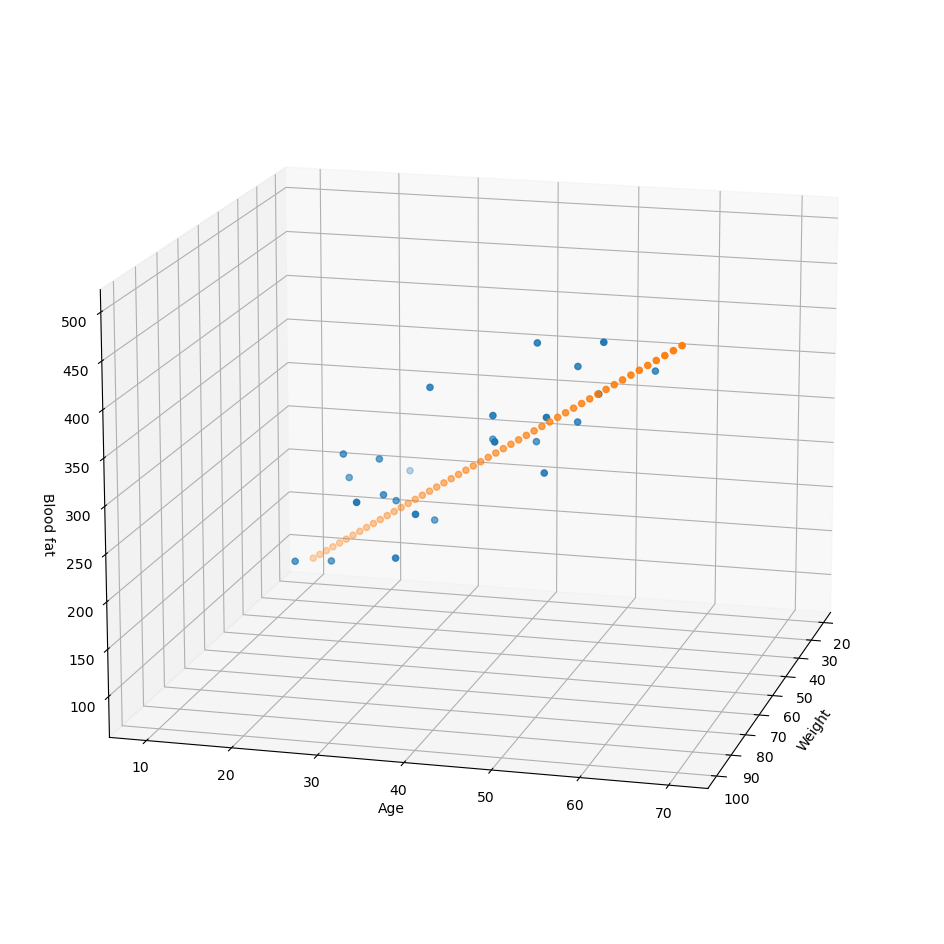
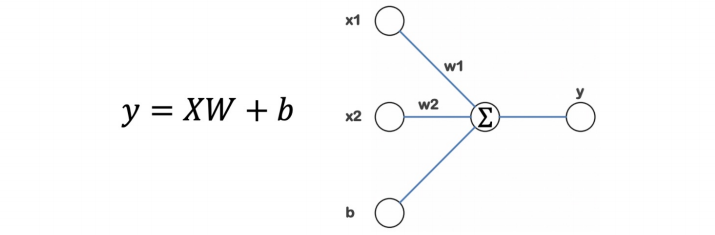
간단한 딥러닝 모델
- 목적 : 나이와 몸무게를 입력하면 blood fat 출력
- x1, x2를 입력해서 y가 나오게하는 Weight와 bias를 구하기
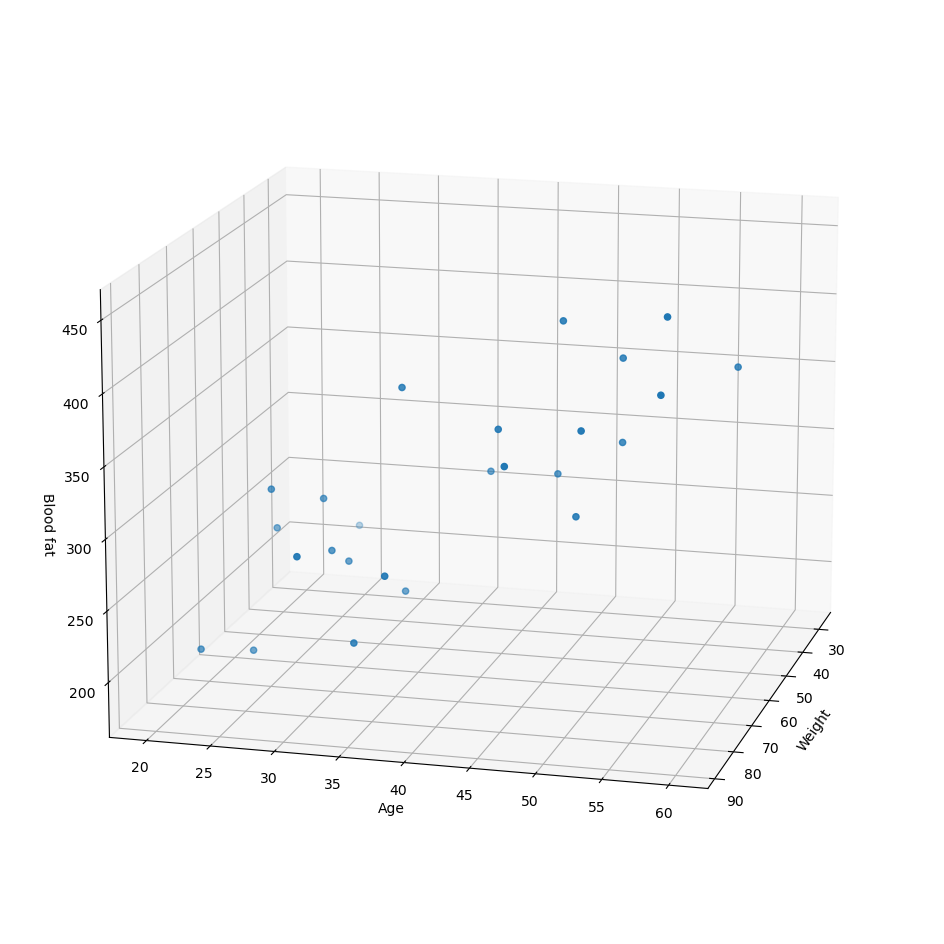
데이터
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/x09.txt'
raw_data = np.genfromtxt(url, skip_header=36)
5 columns (Index, One, Weight(kg), Age, Blood fat) 과 25 rows 으로 이루어진 데이터

scatter 그래프
데이터 전처리
x_data = np.array(raw_data[:, 2:4], dtype=np.float32)
y_data = np.array(raw_data[:, 4], dtype=np.float32)
x_data (몸무게, 나이)

y_data (blood fat)

Dimension 맞추기
y_data는 (25,) 형태이고 x_data는 (25,2) 형태이다.
y_data를 (25,1)로 reshape하여 차원을 맞춰준다.
y_data = y_data.reshape((25,1))
모델 만들기
입력 차원이 2인 데이터를 받아 하나의 출력을 내는 간단한 신경망 모델 생성
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, input_shape = (2,))
])
loss 함수
손실 함수(loss function)는 딥러닝 모델의 학습 과정에서 모델의 출력값과 실제값 사이의 차이를 계산하는 함수이다.
학습 중에 손실 함수의 값을 최소화하는 방향으로 모델의 가중치와 편향을 조정하여 모델을 학습시킨다.
손실 함수는 주어진 문제의 특성에 따라 선택되며, 다양한 손실 함수가 있으나 이번에는 평균 제곱 오차(Mean Squared Error, MSE) 사용
옵티마이저
옵티마이저(optimizer)는 딥러닝 모델의 학습 과정에서 손실 함수를 최적화하기 위해 사용되는 알고리즘이다.
옵티마이저는 모델의 가중치와 편향을 조정하여 손실 함수를 최소화하는 방향으로 모델을 업데이트 한다.
model.compile(optimizer = 'rmsprop', loss='mse')
model.summary()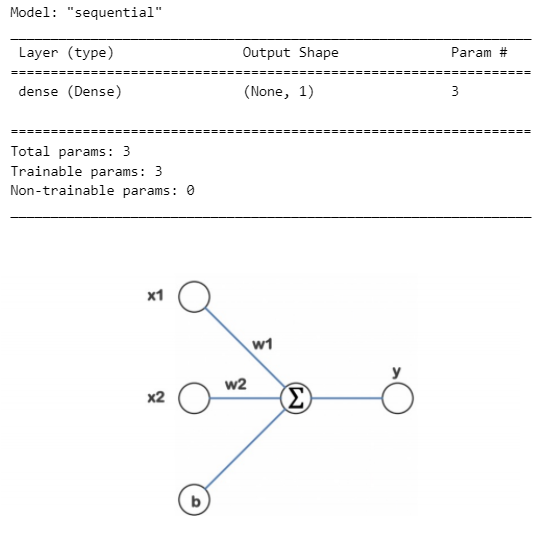
모델 학습하기
epochs : 학습 알고리즘이 주어진 데이터셋을 몇 번 반복해서 학습하는지를 결정하는 하이퍼파라미터.
모델이 한 epoch을 마치면 모든 학습 데이터를 한 번씩 사용하여 업데이트를 수행하고, 새로운 가중치를 계산합니다. 이러한 과정은 모델이 데이터의 패턴을 학습하고 예측을 개선하는 데 도움을 준다.
epochs 값을 크게 설정하면 모델은 더 많은 학습 반복을 수행하며 데이터에 더 적합해질 수 있으나 epochs 값을 너무 크게 설정하면 과적합(overfitting)의 위험이 있을 수 있으므로 주의해야 한다.
과적합 : 모델이 훈련 데이터에 너무 맞춰져 다른 데이터에 대한 일반화 성능이 떨어지는 현상.
epochs 값은 적절한 값으로 조정하는 것이 중요하며, 이는 실험과 검증을 통해 결정해야 한다.
hist = model.fit(x_data, y_data, epochs=2500)
결과 예측
100kg 44살인 사람의 blood fat 추측 결과 : 399.17593
model.predict(np.array([100,44]).reshape(1,2)) #100kg 44살 blood fat 추측 array([[399.17593]], dtype=float32)
가중치와 bias 확인
W_, b_ = model.get_weights()
W_, b_(array([[2.3759224],
[3.6161911]], dtype=float32),
array([2.4712954], dtype=float32))y = XW + b 확인
x = np.linspace(20, 100, 50).reshape(50,1)
y = np.linspace(10, 70, 50).reshape(50,1)
X = np.concatenate((x, y), axis=1)
Z = np.matmul(X, W_) + b_