[NLP] BERT (Bidirectional Encoder Representations from Transformers)
[Machine Learning & Deep Learning]
자연 언어 처리(NLP)를 위한 종래의 방법을 넘은 성능을 발휘한다. BERT는 자연언어 처리 태스크를 교사 없이 양방향으로 사전학습하는 첫 시스템이다.
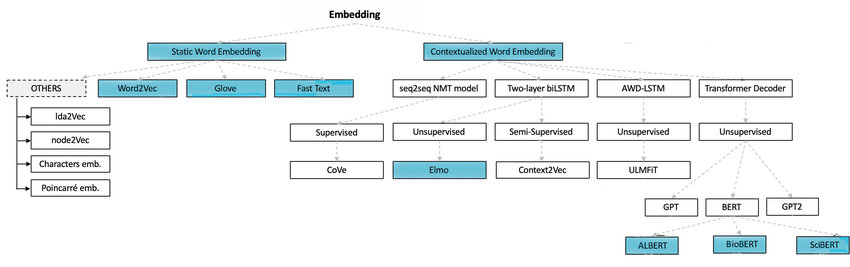
BERT는 Contextual Embedding 방법에 속한다. Contextualised Word Embedding은 단어마다 벡터가 고정되어 있지 않고 문장마다 단어의 Vector가 달라지는 Embedding 방법을 뜻한다 대표적으로 ELMo, GPT, BERT가 있다.
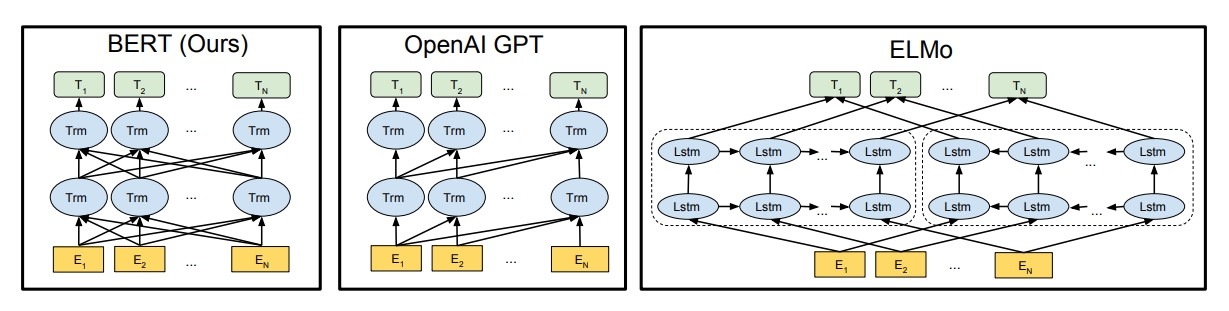
BERT는 양방향이며 OpenAI GPT는 단방향이며 ELMo는 양방향이다
Static Word Embedding 문제점
Static Word Embedding은 단어마다 벡터가 고정되어 있는 방법을 뜻하면 대표적으로 Word2vec, Fasttext, Glove이 존재한다.
Problem : 단어의 Vector가 모든 문맥에서 동일하다.
에를 들어 "배를 타고 떠났다"와 "맛있는 배를 먹었다"라는 문장에서 "배를"은 같은 벡터 값을 가진다.
"배를" 이란 단어는 One-hot Encoding 방식으로 표현하면 [ 0 0 0 1 0 ]의 값을 가진다.
첫번째 문장에서도 [ 0 0 0 1 0 ]을 가지고 두번째 문장에서도 [ 0 0 0 1 0 ]을 가진다.
즉, 모든 문장에서 고정된 One-hot Encoding 값을 가진다.
모든 단어들이 고정된 One-hot Encoding을 가지는 상태에서 Weight Vector를 곱하면 모든 문장에서 똑같은 Vector 값을 가지게 된다.
그리고 Static Word Embedding 에서는 문맥 정보가 반영되지 않는 Shallow Neural Net을 사용해서 학습을 진행했었다.

BERT
BERT는 문맥을 고려하여 단어의 표현을 학습하는 방법으로 구축되었다.
예를 들어, I made a bank deposit라는 문장은 bank의 단방향 특징표현은 단지 I made a만에 의해 결정되며, deposit은 고려되지 않는다. 몇개의 이전의 대응에서는 분리한 좌문맥모델과 우문맥모델에 의한 특징표현을 조합하고 있었지만,이것은 얕은 양방향 방법이다. BERT는 bank를 왼쪽과 오른쪽 양쪽의 문맥 I made a ... deposit을 딥 뉴럴 네트워크(Deposit)의 최하층에서 이용해 특징을 표현하기 때문에 BERT는 '딥 양방향(deeply bidirectional)'이다.
Masked language model
BERT는 간단한 접근법을 사용한다. 입력에서 단어의 15%를 숨기고 딥 양방향 Transformer encoder를 통해 전체 시퀀스를 실행한 다음 마스크 된 단어만 예측한다.


문장에 MASK를 씌우는 거는 Pre-trained 학습에서만 하지 실제 fine-tuning 할 때는 씌우지 않기 때문에 생기는 간극을 해결하기 위해서 Mask token의 80%는 mask로 10%는 random word로 10%는 unchanged word로 넣어준다.

Next Sentence Prediction
NSP는 두 문장이 주어졌을 때 두 번째 문장이 첫 번째 문장의 바로 다음에 오는 문장인지 여부를 예측하는 방식이다. 두 문장 간 관련이 고려되어야 하는 NLI와 QA의 파인튜닝을 위해 두 문장이 연관이 있는지를 맞추도록 학습한다
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNext
Input = [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flight
Label = NotNext첫번째 문장과 두번째 문장을 입력값으로 넣어 앞 뒤 문장이 연속되는 문장인지 분류하는 학습을 추가로 진행하였다.
BERT 구조
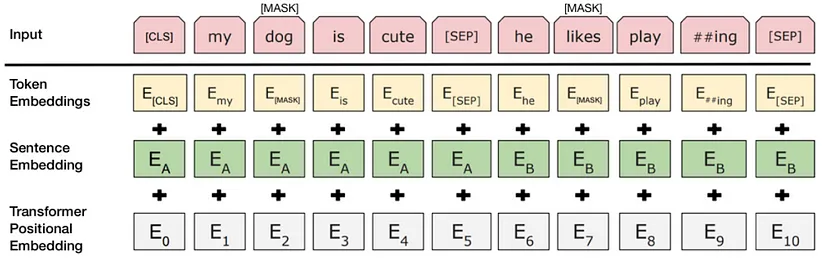
Image by BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
1) Token Embeddings
Token Embeddings은 Word Piece 임베딩 방식을 사용한다. Word Piece 임베딩은 자주 등장하면서 가장 긴 길이의 sub-word를 하나의 단위로 만든다. 자주 등장하는 단어(sub-word)는 그 자체가 단위가 되고, 자주 등장하지 않는 단어(rare word)는 더 작은 sub-word로 쪼개어진다.
입력받은 모든 문장의 시작으로 [CLS] 토큰(special classification token)이 주어지며 여기에 간단한 classifier을 붙이면 단일 문장이나 연속된 문장을 분류할 수 있다. 분류 작업이 아닐 경우에는 이 토큰을 무시한다. 또한 문장의 구분을 위해 문장의 끝에 [SEP] 토큰을 사용한다.
2) Segment Embeddings
단어가 첫번째 문장에 속하는지 두번째 문장에 속하는지 알려준다.
토큰으로 나누어진 단어들을 다시 하나의 문장으로 만들고 첫 번째 [SEP] 토큰까지는 0으로 그 이후 [SEP] 토큰까지는 1 값으로 마스크를 만들어 각 문장들을 구분한다.
3) Position Embeddings
Position Embeddings는 토큰의 순서를 인코딩한다.
BERT는 transformer의 encoder를 사용하는데 Transformer는 Self-Attention 모델을 사용한다. Self-Attention은 입력의 위치에 대해 고려하지 못하므로 입력 토큰의 위치 정보를 주어야 한다.
Transformer 에서는 Sigsoid 함수를 이용한 Positional encoding을 사용하였고, BERT에서는 이를 변형하여 Position Encodings을 사용한다.
각 임베딩들의 토큰 별로 모두 더하여 입력 벡터로 사용한다.
Fine Tuning
BERT는 사전 학습된 대용량의 레이블링 되지 않는(unlabeled) 데이터를 이용하여 언어 모델(Language Model)을 학습하고 이를 토대로 특정 작업( 문서 분류, 질의응답, 번역 등)을 위한 신경망을 추가하는 전이 학습 방법이다.
전이학습(Fine-tuning)은 저렴하며, 사전학습이 끝난 모델을 사용하여 하나의 Cloud TPU를 이용, 1시간 GPU를 사용하면 2, 3시간만에 재현할 수 있다.
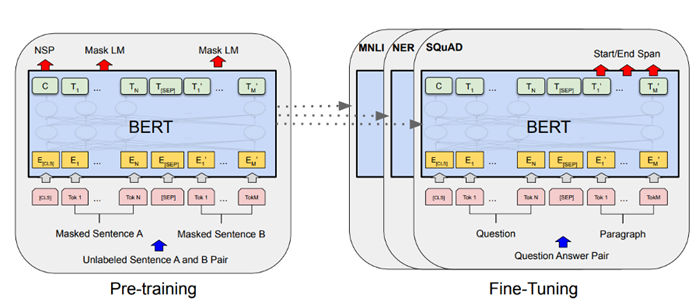
그림과 같이 BERT를 이용한 자연어 처리는2단계로 진행되며 거대 Encoder가 입력 문장들을 임베딩하여 언어를 모델링하는 Pre-training 과정과과 이를 fine-tuning하여 여러 자연어 처리 Task를 수행하는 과정으로 구분된다.
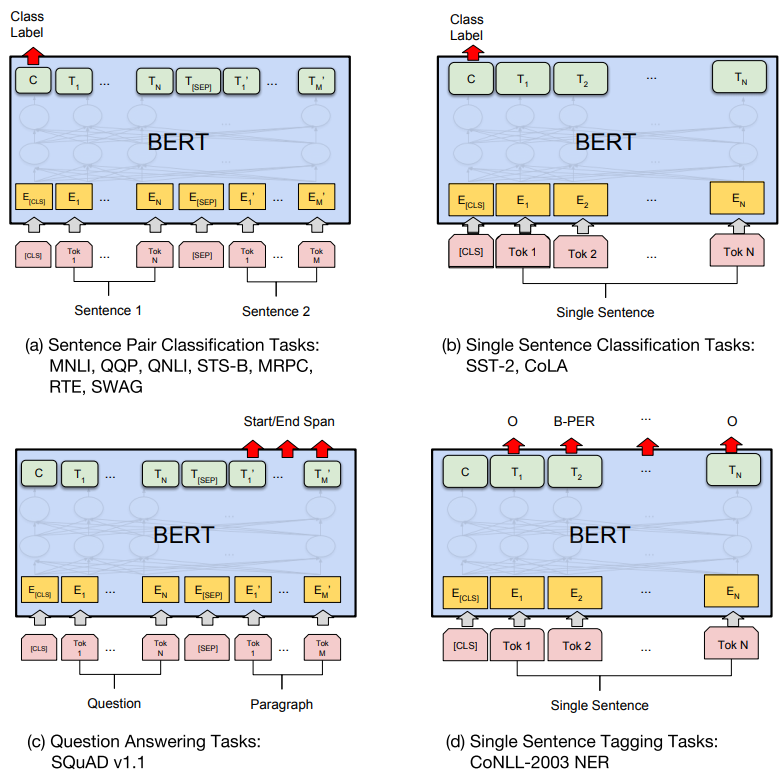
BERT를 각 Task에 쓰기위한 예시는 위 그림과 같다.
- (a)는 문장 쌍 분류 문제로 두 문장을 하나의 입력으로 넣고 두 문장간 관계를 구한다.
- (b)는 한 문장을 입력으로 넣고 문장의 종류를 분류하는 문제이다.
- (c)는 문장이나 문단 내에서 원하는 정답 위치의 시작과 끝을 구한다.
- (d)는 입력 문장 Token들의 개체명(Named entity recognigion)을 구하거나 품사(Part-of-speech tagging) 를 구하는 문제이다. 다른 Task들과 다르게 입력의 모든 Token들에 대해 결과를 구한다.
📌 참고
인공지능 신문 : 인공지능(AI) 언어모델 ‘BERT(버트)'는 무엇인가
데이터 분석 공부하는 오복이 : BERT 개념 정리(특징/구조/동작 방식/종류/장점/BERT 모델 설명)
슬기로운 연구 생활 : Classification - [13] BERT
AI, NLP를 연구하는 엔지니어 : BERT를 파해쳐 보자!!
A Survey on Language Models 이미지 참조
