INSERT문 기본
INSERT는 테이블에 데이터를 삽입하는 명령어입니다.
- 기본형 : INSERT [INTO] 테이블[(열1,열2,...)] VALUES (값1,값2)
- 우선 테이블 이름 다음에 나오는 열은 생략이 가능합니다.
- 하지만, 생략할 경우에 VALUES 다음에 나오는 값들의 순서 및 개수가 테이블이 정의된 열 순서 및 개수와 동일해야합니다.
USE sqldb;
CREATE TABLE testTbl1 (id int, userName char(3), age int);
INSERT INTO testTbl1 values (1,'홍길동', 25);- 만약 위의 예에서 id와 이름만을 입력하고 나이를 입력하고 싶지 않다면 다음과 같이 테이블 이름 뒤에 입력할 열의 목록을 나열해줘야 합니다.
INSERT INTO testTbl1(id,userName) VALUES(2, '설현');- 이 경우 생략한 age에는 NULL값이 들어가게 됩니다.
- 열의 순서를 바꿔서 입력하고 싶을 때는 꼭 열이름을 입력할 순서에 맞춰 나열해 줘야 합니다.
INSERT INTO testTbl(userName, age, id) VALUES('하니',26, 3);자동으로 증가하는 AUTO_INCREMENT
테이블의 속성이 AUTO_INCREMENT로 지정되어 있다면, INCREMENT로 지정되어 있다면, INSERT문에서는 해당 열이 없다고 생각하고 입력하면 됩니다.
- AUTO_INCREMENT는 자동으로 1부터 증가하는 값을 입력해 준다.
- AUTO_INCREMENT로 지정할 때는 꼭 PRIMARY KEY또는 UNIQUE로 지정해 줘야 하며 데이터 형은 숫자 형식만 사용할 수 있습니다.
- AUTO_INCREMENT로 지정된 열은 INSERT문에서 NULL값을 지정하면 자동으로 값이 입력됩니다.
USE sqldb;
CREATE TABLE testTbl2
(id int AUTO_INCREMENT PRIMARY KEY,
userName char(3),
age int);
INSERT INTO testTbl2 VALUES(null, '지민', 25);
INSERT INTO testTbl2 VALUES(null, '유나', 22);
INSERT INTO testTbl2 VALUES(null, '유경', 21);
SELECT *FROM testTbl2;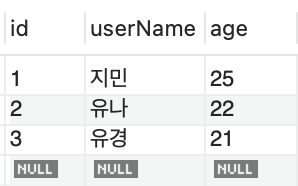
- 계속 입력을 하다 보면 현재 어느 숫자까지 확인할 필요도 있습니다.
- SELECT LAST_INSERT_ID();쿼리를이용하면 마지막에 입력된 값을 보여줍니다.
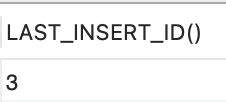
- 그런데, 이후에는 AUTO_INCREMENT 입력값을 100부터 입력되도록 변경하고 싶다면 다음과 같이 수행합니다.
USE sqldb;
CREATE TABLE testTbl2
(id int AUTO_INCREMENT PRIMARY KEY,
userName char(3),
age int);
INSERT INTO testTbl2 VALUES(null, '지민', 25);
INSERT INTO testTbl2 VALUES(null, '유나', 22);
INSERT INTO testTbl2 VALUES(null, '유경', 21);
SELECT *FROM testTbl2;
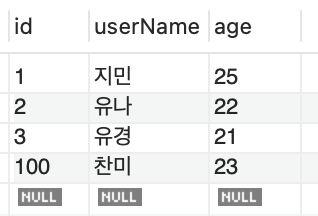
- 증가값을 지정하려면 서버 변수인 @@auto-increment_increment변수를 변경시켜야합니다.
- 다음 예제는 초기값을 1000으로 하고 증가값은 3으로 변경하는 예제입니다.
use sqldb;
CREATE TABLE testTbl3
(id int AUTO_INCREMENT PRIMARY KEY,
userName char(3),
age int);
ALTER TABLE testTbl3 AUTO_INCREMENT=1000;
SET @@auto_increment_increment=3;
INSERT INTO testTbl3 VALUES( Null,'나연',20);
INSERT INTO testTbl3 VALUES( Null,'정연',18);
INSERT INTO testTbl3 VALUES( Null,'모모',19);
SELECT * FROM testTbl3;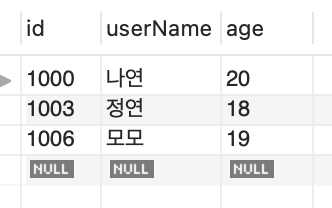
한꺼번에 INSERT
- 여러개의 행을 한꺼번에 입력할 수도 있습니다. 3건을 입력하기 위해서 지금까지 3개의 문장으로 입력했었지만 3건의 데이터를 한 문장에서 다음과 같이 입력할 수 있습니다.
- INSERT INTO 테이블이름 VALUES(값1,값2...),(값3,값4...),(값5,값6...);
INSERT INTO testTbl3 Values(null,'미미',20),(null,'수미',23);대량의 샘플 데이터 생성
- 지금까지 했던 방식으로 직접 키보드로 입력하려면 시간이 많이 걸릴것입니다.이럴때
INSERT INTO...SELECT 구문을 사용할 수 있습니다. - 이는 다른 테이블의 데이터를 가져와서 대량으로 입력하는 효과를 냅니다.
형식 : INSERT INTO 테이블이름 (열 이름1, 열 이름2,...)
SELECT문 ;- 물론 SELECT문의 결과 열의 개수는 INSERT를 할 테이블의 열 개수와 일치해야 합니다.
use sqldb;
CREATE TABLE testTbl4(id int,Fname varchar(50),Lname varchar(50));
INSERT INTO testTbl4
SELECT emp_no, first_name, last_name
FROM employees.employees;데이터의 수정 : UPDATE
기존에 입력되어 있는 값을 변경하기 위해서는 UPDATE문을 다음과 같은 형식으로 사용한다.
UPDATE 테이블이름
SET 열1=값1, 열2=값2, ...
WHERE 조건;- UPDATE는 사용방법은 간단 하지만 이것을 꼭 주의해야합니다.
- 바로! WHERE절은 생략이 가능하지만 WHERE절을 생략하면 테이블의 전체의 행이 변경됩니다.
UPDATE testTbl4
SET Lname ='없음'
WHERE Fname = ' kimchi';- 이렇게 실수로 WHERE절을 빼먹고 UPDATE testTbl4 SET Lname='없음'을 실행했다면 전체 행 Lname이 모두 '없음'으로 변경된다.
- 이렇게 된다고 하면 원상태로 복구하기 위해서는 많은 복잡한 절차가 필요할 뿐만 아니라 다시 되돌릴 수 없는 경우도 있습니다.
- 예외는 있습니다. 전체 테이블의 내용을 변경하고 싶을 때 WHERE를 생략할 수도 있는데, 예로 구매 테이블에서 '현재의 단가가 모두 1.5배 인상된다'라고 한다면 아래처럼 쓸 수 있습니다.
USE sqldb;
UPDATE buytbl SET price * 1.5; 데이터의 삭제 : DELETE FROM
DELETE 또한 UPDATE와 거의 비슷한 개념입니다. DELETE는 행 단위로 삭제합니다.
DELETE FROM 테이블이름 WHERE 조건;- 여기서 또한 WHERE문이 생략되면 전체 데이터를 삭제합니다.
- 예를들어 testTbl4에서 'Aamer'을 모두 지우는 것이 아니라 'Aamer'중에서 상위 몇건만 삭제하려면 LIMIT구문과 함께 사용하면 됩니다.
- 예제로 'Aamer'중에서 상위 5건만 삭제해보겠습니다.
DELETE FROM testTbl4 WHERE Fname = 'Aamer' LIMIT 5;DROP문은 테이블 자체를 삭제합니다.
DROP TABLE 테이블이름;TRUNCATE문의 효과는 DELETE와 동일하지만 트랜잭션 로그를 기록하지 않아서 속도가 빠릅니다.
- 그러므로 대용량의 테이블 전체 내용을 삭제할 때는 테이블 자체가 필요 없을 경우에는 DROP으로 삭제하고, 테이블 구조는 남겨놓고 싶다면 TRUNCATE로 삭제하는 것이 효율적입니다.
조건부 데이터 입력,변경
- 앞에서 INSERT문이 행 데이터를 입력해 주는 것에 대해 배웠습니다.
- 그렇다면 기본 키가 중복된 데이터를 입력하면 어떻게 될까..?
-당연히 입력되지 않습니다. - 하지만 100건을 입력하고자 하는데 첫 번째 한건의 오류 때문에 나머지 99건도 입력되지 않는 것도 문제가 될 수 있습니다. MYSQL은 오류가 발생해도 계속 진행하는 방법을 제공합니다.(java의 예외처리와 비슷한 느낌)
- 이번에는 입력 시에, 기본 키가 중복되면 데이터가 수정되도록 해보겠습니다.
insert into membertbl values ('BBK','비비코','미국')
on duplicate key update name ='비비코', addr='미국';
insert into membertbl values('DJM','동짜옹','일본')
on duplicate key update name ='동짜옹',addr='일본';
select * from membertbl;- 첫번째 행에서는 BBK는 중복이 되었으므로 UPDATE문이 수행되었습니다.
- 그리고 두번째 입력한 DJM은 없으므로 일반적인 INSERT처럼 데이터가 입력되었습니다.
- 결국 ON DUPLICATE UPDATE는 PK가 중복되지 않으면 일반 INSERT가 되는 것이고, PK가 중복 되면 그 뒤에 UPDATE문이 수행됩니다.

블로그 이전합니다! https://jyyoun1022.tistory.com/