📕 Numpy 객체
-
배열 생성 :
array함수 사용-> 1차원부터 다차원 구조 배열 생성 가능
import numpy as np
np.array([1,2,3])
# 1차원 배열 생성
# array([1, 2, 3]) 출력됨
array = np.array([[2,3], [4,5]])
# 2차원 배열 생성
# 2차원 배열 생성할 떄 [] 안에 다시 배열을 넣어야 함
array[0]
# array([2, 3]) 출력됨
array[1][0]
# 4 출력됨
array[0, :1]
# array([4]) 출력됨
# 0번 인덱스의 1번 인덱스 미만으로 출력
array[1, 1]
# 5 출력됨
# 1번 인덱스의 1번 인덱스 추출📗 Numpy 객체의 메서드
-
.sum(): 합계 -
.min(): 최소값 -
.max(): 최대값 -
.mean(): 평균 -
.std(): 표준편차
-
len(): 배열의 길이 -
set(): 중복 되는 원소 제외하고 출력 -
unique(): 중복 제외 고유한 원소만 출력
.where(): 조건에 맞으면 첫 번째 값 리턴, 조건과 부합하지 않으면 두 번째 값 리턴
nums = np.array([1, 2, 2, 3])
len(nums)
# 4 출력됨
set(nums)
# {1, 2, 3} 출력됨
np.unique(nums)
# array([1, 2, 3]) 출력됨
np.where(nums == 2, 1, 0)
# nums의 원소가 2일 경우 1 출력, 아닐 경우 0 출력
# array([0, 1, 1, 0]) 출력됨📕 Pandas 객체
-
value와 index로 구성
-
Series()함수와 대괄호 사용하여 생성
⭐ 입력
pd.Series([1, 2, 3])📌 출력
0 1
1 2
2 3
dtype: int64⭐ 입력
pd.Series([1, 2, 3], index = ["a", "b", "c"])📌 출력
a 1
b 2
c 3
dtype: int64📗 Pandas 객체의 메서드
-
sum()- 합계 -
min()- 최소값 -
max()- 최대값 -
mean()- 평균 -
std()- 표준편차 -
unique()- 고유값 -
idxmax()- 최대값의 위치 -
isin()- 포함 여부 검사
ser = pd.Series([1,2,3])
ser.idxmax()
# 2 출력됨
ser.isin([1,2])
# True, false 리턴함
# 0 True
# 1 True
# 2 False
# dtype: bool 출력됨
📗 시리즈의 색인
ser = pd.Series([1, 2, 3, 6, 9])
ser[0]
# 1 출력됨
ser[[1, 3]] # 인덱스 번호 찾는 거임
# 1 2
# 3 6 출력됨
# 앞에 숫자는 인덱스 번호, 뒤에 숫자는 값
ser[2:]
# 2 3
# 3 6
# 4 9 출력됨
# 2번 인덱스부터 끝까지 출력
ser[:3]
# 0 1
# 1 2
# 2 3 출력됨
# 첫 번째 인덱스부터 3번 미만 인덱스(2번 인덱스)까지 출력
ser[:-1]
# 첫 번째 인덱스부터 제일 마지막 인덱스 앞 인덱스까지 출력📗 데이터 프레임
-
Pandas 객체의 2차원 프레임
-
value, row index, column index로 구성
-
변수별로 문자, 숫자 등 다른 속성 지정 가능
-
딕셔너리 활용하여 생성
df = pd.DataFrame({"aa" : [1, 2, 3], "bb" : [4, 5, 6]})
df.aa
# 0 1
1 2
2 3
Name: aa, dtype: int64 출력됨
df["aa"]
# 위와 같은 코드
df["aa"][2]
# 3 출력됨✔ loc
-
location 의 약자
-
데이터 프레임의 행 또는 칼럼의 label이나 boolean array로 인덱싱하는 방법
-
두 번째 파라미터에 문자가 들어감
< 기본 문법 >
df.loc[행 인덱싱 값, 열 인덱싱 값]
df = pd.DataFrame({"aa" : [1, 2, 3], "bb" : [4, 5, 6]})
df.loc[:, "aa"]
# 처음부터 키 값이 "aa"인 인덱스 찾음
# 0 1
# 1 2
# 2 3
# Name: aa, dtype: int64 출력됨⭐ 입력
df = pd.DataFrame({"aa" : [1, 2, 3], "bb" : [4, 5, 6]})
df[:, :]
# 전체 행, 전체 열 출력📌 출력

✔ iloc
-
integer location의 약자
-
데이터프레임의 행이나 칼럼 순서를 나타내는 정수
-
정수만 들어갈 수 있기 때문에 두 번째 파라미터에도 숫자 들어감
< 기본 문법 >
df.iloc[행 인덱싱 값, 열 인덱싱 값]
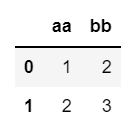
df = pd.DataFrame({"aa" : [1, 2, 3], "bb" : [4, 5, 6]})⭐ 입력
df.iloc[:2, :]
// 행 2번 미만(1번 인덱스)까지 출력, 열 전체 출력📌 출력
⭐ 입력
df.iloc[:, 0]
// 행 전체 출력, 열 0번 인덱스("aa")만 출력📌 출력
0 1
1 2
2 3
Name: aa, dtype: int64📗 crosstab
-
두 변수를 조합할 때 사용하는 Pandas 함수
-
normalize 인자에 True, 1, 0 값 할당하여 값 정규화 가능
📗 groupby
-
특정 변수를 기준으로 요약 연산할 때 활용
-
두 개 이상 변수를 기준으로 할 경우 변수명 리스트로 묶음
