라미리포트를 개발하면서 처음 LLM 프로젝트를 시작했을 때만 해도 별로 어렵지 않을 거라 생각했습니다. API 호출해서 결과 보여주면 되는 거 아닌가? 하지만 실제로 부딪혀보니 생각보다 훨씬 복잡한 문제들이 기다리고 있었죠.

<개발중인 서비스>
프론트엔드 개발자의 고민
가장 먼저 마주친 건 모델별로 제각각인 인터페이스였습니다. 어떤 모델은 스트리밍을 지원하고 어떤 모델은 지원하지 않고, 시스템 프롬프트 처리 방식도 다르고... 모델이 추가될 때마다 프론트엔드 코드가 점점 복잡해져갔습니다.
두 번째로는 사용자 경험 문제였죠. 텍스트가 화면에 뚝뚝 끊겨 나오는 걸 보면서 '이걸 어떻게 하면 좀 더 자연스럽게 만들 수 있을까?' 고민하기 시작했습니다. 서버 응답은 빠른데 화면에서 답답해 보이는 것도 문제였고, 네트워크 상황에 따라 체감 속도가 크게 달라지는 것도 해결해야 했습니다.
우리가 해결해야 할 과제들
이 글에서는 라미리포트를 개발하면서 마주친 주요 문제들과 그 해결 과정을 공유하려고 합니다. 특히 다음 내용들에 초점을 맞춰보겠습니다:
- 여러 LLM 모델들의 차이를 우아하게 다루는 방법
- 스트리밍 응답을 자연스럽게 보여주는 UI 최적화 기법
- 네트워크 상황과 무관하게 일관된 경험을 제공하는 전략
실제 개발 과정에서 겪은 시행착오와 그 속에서 찾아낸 해결책들을 통해, 비슷한 고민을 하고 계신 분들에게 조금이나마 도움이 되었으면 합니다.
모델 하나에 분기문하나?
"GPT-4O 연동했던 코드를 O1에도 붙여볼까?" 라미리포트에 새로운 모델을 추가하려 할 때마다 마주하게 된 현실. 겉보기에는 비슷해 보이는 LLM 모델들이 실제로는 전혀 다른 인터페이스를 가지고 있다는 걸 알게 됐죠.
그래서 일단 if문으로...
처음에는 단순하게 접근했습니다. "모델별로 분기 처리하면 되겠지?"
// 최초의 순진한 접근법
if (modelType === 'o1') {
// O1용 처리 로직
// 시스템 프롬프트? 여기선 [SYSTEM] 붙여서...
} else if (modelType === 'gpt4o') {
// GPT-4O용 처리 로직
// 여기선 role: system 지원하니까...
}이렇게 시작했던 코드는 모델이 하나 둘 늘어날 때마다 점점 더 무서운 형태가 되어갔습니다. 새로운 모델이 추가될 때마다 프론트엔드 전체를 손봐야 했고, 테스트는 점점 더 복잡해졌죠.
프로바이더 패턴의 등장
프로바이더 패턴(또는 어댑터 패턴)은 서로 다른 인터페이스를 가진 객체들을 일관된 방식으로 사용할 수 있게 해주는 디자인 패턴입니다. LLM 서비스에서는 각 모델의 특성을 캡슐화하고, 동일한 인터페이스로 접근할 수 있게 해줍니다.
// 공통 인터페이스 정의
interface LLMProvider {
chat(messages: Message[]): Promise<any>;
}
// 기본 메시지 타입
interface Message {
role: 'system' | 'user' | 'assistant';
content: string;
}팩토리 패턴을 통한 모델별 프로바이더 생성
각 모델의 특성에 맞는 프로바이더를 생성하기 위해 팩토리 패턴을 활용합니다:
class LLMFactory {
static create(modelType: string): LLMProvider {
switch (modelType) {
case 'o1':
return new O1Provider({
// O1 모델의 설정
});
case 'gpt4o':
return new GPT4OProvider({
// GPT-4O 모델의 설정
});
// 새로운 모델은 여기에 추가
}
}
}
// 사용 예시
const llm = LLMFactory.create('o1');
const response = await llm.chat(messages);프로바이더 패턴의 실제 활용 예시
시스템 프롬프트 처리
O1 모델은 role: "system"을 지원하지 않는 문제가 있습니다. 프로바이더 패턴을 사용하면 이를 자연스럽게 해결할 수 있습니다:
class O1Provider implements LLMProvider {
async chat(messages: Message[]) {
// system 역할을 user 메시지로 변환
const processed = messages.map(msg => {
if (msg.role === 'system') {
return {
role: 'user',
content: `[SYSTEM] ${msg.content}`
};
}
return msg;
});
return this.sendRequest(processed);
}
}
class GPT4OProvider implements LLMProvider {
async chat(messages: Message[]) {
// GPT-4O는 system role을 직접 지원하므로 변환 불필요
return this.sendRequest(messages);
}
}스트리밍 응답 처리
스트리밍 지원 여부에 따른 분기 처리도 프로바이더 내부로 캡슐화할 수 있습니다. 먼저 분기 처리가 필요한 상황을 보겠습니다:
// 분기 처리가 필요한 경우의 프론트엔드 코드
async function handleChat(messages: Message[]) {
if (modelType === 'o1') {
// O1은 스트리밍 미지원
const response = await fetchO1Response(messages);
displayFullResponse(response);
} else if (modelType === 'gpt4o') {
// GPT-4O는 스트리밍 지원
const stream = await fetchGPT4OStream(messages);
handleStreamingResponse(stream);
}
}이를 프로바이더 패턴으로 해결하면:
// 모든 응답을 스트리밍 형태로 통일
abstract class BaseLLMProvider implements LLMProvider {
async chat(messages: Message[]): Promise<ReadableStream> {
const response = await this.sendRequest(messages);
// 스트리밍을 지원하지 않는 경우 변환
if (!this.supportsStreaming()) {
return this.createStreamFromResponse(response);
}
return response;
}
protected createStreamFromResponse(response: string): ReadableStream {
return new ReadableStream({
start(controller) {
controller.enqueue(response);
controller.close();
}
});
}
}
// 프론트엔드 코드는 단순화됨
const llm = LLMFactory.create(modelType);
const stream = await llm.chat(messages);
handleStreamingResponse(stream); // 모든 모델에 동일한 처리프로바이더 패턴의 이점
-
일관된 인터페이스
- 모든 모델을 동일한 방식으로 사용
- 프론트엔드 코드의 분기문 제거
-
확장성
// 새로운 모델 추가가 쉬움 class NewModelProvider extends BaseLLMProvider { // 새 모델의 특성에 맞게 구현만 하면 됨 } -
유지보수성
- 모델별 특성을 프로바이더 내부로 캡슐화
- 기존 코드 수정 없이 새로운 모델 추가 가능
- 테스트와 디버깅이 용이
이러한 패턴은 특히 LLM 생태계가 빠르게 진화하는 현재 상황에서 큰 가치를 발휘합니다. 새로운 모델이 계속해서 출시되더라도, 해당 모델의 프로바이더만 추가하면 되므로 기존 코드의 변경 없이 유연하게 대응할 수 있습니다.
스트리밍 UI 맛나게 구현하기
LLM 스트리밍 UI를 구현하면서 가장 까다로웠던 것은 텍스트를 자연스럽게 표시하는 것이었습니다. 청크가 불규칙하게 도착하는 상황에서 어떻게 부드러운 사용자 경험을 만들어낼 수 있을까요?
처음엔 단순할 줄 알았죠
1. 청크 즉시 표시하기
가장 단순한 첫 번째 접근법은 청크가 도착하는 대로 바로 화면에 표시하는 것이었습니다:
시간(ms) |--100--|--100--|--800--|--50---|--400--|
청크도착 "안녕하" "세요!" "열심히" "코" "딩해요"
화면갱신 뚝! 뚝! 뚝! 뚝! 뚝!
체감효과 ....불규칙한 끊김.... ....답답한 기다림....사용자 입장에서는 마치 인터넷이 불안정한 것처럼 느껴졌고, 텍스트가 불규칙하게 툭툭 끊기면서 나타나는 게 보기 좋지 않았습니다.
2. 글자 단위로 표시하기
두 번째 시도는 requestAnimationFrame을 사용해 한 글자씩 출력하는 방식이었습니다:
시간(ms) |--16--|--16--|--16--|--16--|--16--|--16--|
실제응답 "안녕하세요!"(이미 서버에서 전체 응답 수신 완료)
화면갱신 "안" "녕" "하" "세" "요" "!"
프레임 RAF RAF RAF RAF RAF RAF
체감효과 ...서버 응답은 왔는데 화면에는 왜 이렇게 천천히...이번에는 반대로 너무 느린 문제가 있었습니다. 서버에서 응답은 이미 다 받았는데도, 브라우저의 프레임 간격(16.67ms)에 맞춰 한 글자씩 출력하다 보니 불필요하게 지연이 발생했죠. 사용자 입장에서는 답답함을 느낄 수밖에 없었습니다.
청크 도착의 불규칙성
실제 청크 도착 패턴을 시간순으로 보면 이렇습니다:
시간(ms) |--100--|--100--|--800--|--50---|--400--|
청크크기 [ㅁㅁㅁ] [ㅁㅁ] [ㅁㅁㅁㅁ][ㅁ] [ㅁㅁㅁ]
실제응답 "안녕하" "세요!" "열심히" "코" "딩해요"모델의 처리 속도와 네트워크 상황에 따라 청크의 크기와 도착 간격이 제각각입니다. 이런 불규칙한 데이터를 어떻게 자연스럽게 보여줄 수 있을까요?
동적 스케줄링으로 해결하기
해결책은 '패턴 분석기'를 통한 동적 스케줄링입니다. 청크들의 도착 패턴을 분석하고 이에 맞춰 유연하게 대응하는 거죠.
class StreamPatternAnalyzer {
private chunks: Array<{
timestamp: number; // 청크 도착 시간
queueSize: number; // 현재 큐 크기
}> = [];
private readonly MAX_HISTORY = 8; // 최근 8개 청크만 분석패턴 분석의 핵심 포인트들을 살펴보겠습니다:
-
최근 이력 관리
if (this.chunks.length > this.MAX_HISTORY) { this.chunks.shift(); // 오래된 패턴은 폐기 }최근 8개의 청크만 저장하여 현재 상황에 더 민감하게 반응합니다.
-
보수적인 초기 설정
if (this.chunks.length < 3) { return { avgInterval: 350, // 보수적인 초기값 avgChunkSize: 4, confidence: 0 // 데이터 부족시 신뢰도 0 }; }충분한 데이터가 쌓일 때까지는 안전하게 접근합니다.
-
변동성 기반 신뢰도 계산
const variance = intervals.reduce( (sum, interval) => sum + Math.pow(interval - avgInterval, 2), 0 ) / intervals.length; const stdDev = Math.sqrt(variance); const confidence = Math.min( 1.0, (this.chunks.length / 5) * // 샘플 수가 적으면 신뢰도 감소 (1 - stdDev / avgInterval) // 변동성이 크면 신뢰도 감소 );도착 간격의 표준편차로 패턴의 안정성을 판단하고, 이를 바탕으로 신뢰도를 계산합니다.
-
안전 마진 확보
return { avgInterval: avgInterval * 1.25, // 25% 추가 여유 avgChunkSize: Math.ceil( this.chunks.reduce((sum, chunk) => sum + chunk.queueSize, 0) / this.chunks.length ), confidence: confidence };예상 간격에 25%의 여유를 더해 안전성을 확보합니다.
이러한 패턴 분석을 바탕으로, 스케줄러는 상황에 따라 적절한 전략을 선택합니다:
// 패턴이 불안정할 때는 보수적 접근
if (pattern.confidence < 0.8) {
return { needsBatch: queueSize > 8, batchSize: 2 };
}
// 시간이 빠듯할 때는 제한적으로 배치 처리
if (estimatedProcessingTime > safeProcessingTime) {
const portionToBatch = Math.ceil(queueSize * 0.35); // 큐의 35%만 배치
return { needsBatch: true, batchSize: Math.min(portionToBatch, MAX_BATCH_SIZE) };
}결과적으로 이런 섬세한 최적화를 통해 다음과 같은 자연스러운 출력을 만들어낼 수 있습니다:
시간(ms) |--50--|--50--|--50--|--50--|--50--|
출력결과 [ㅁㅁ] [ㅁㅁ] [ㅁㅁ] [ㅁㅁ] [ㅁㅁ]
체감효과 자연스럽게 흐르는 텍스트...........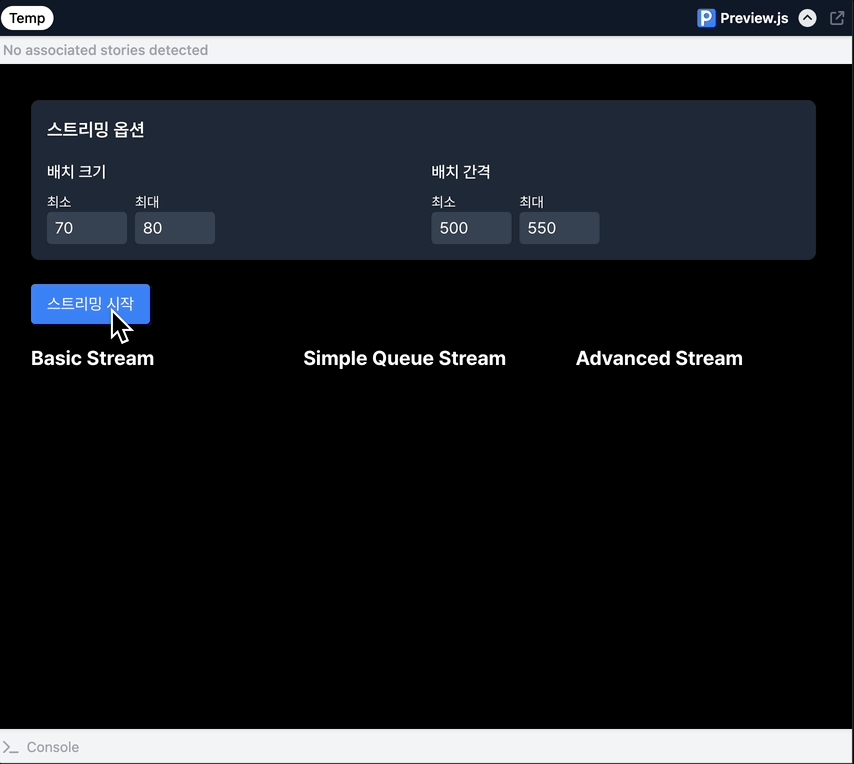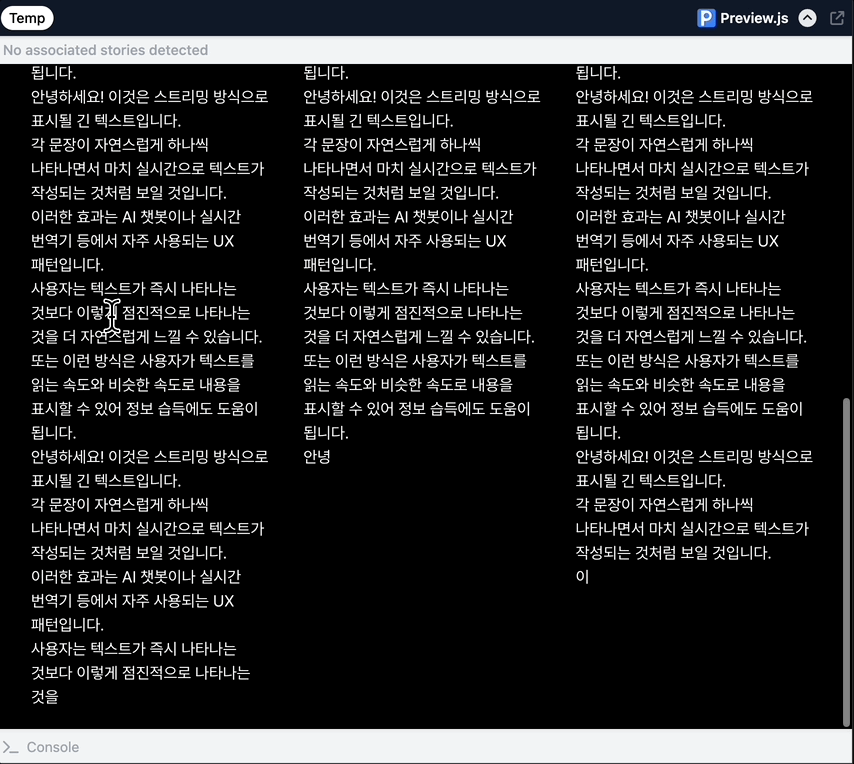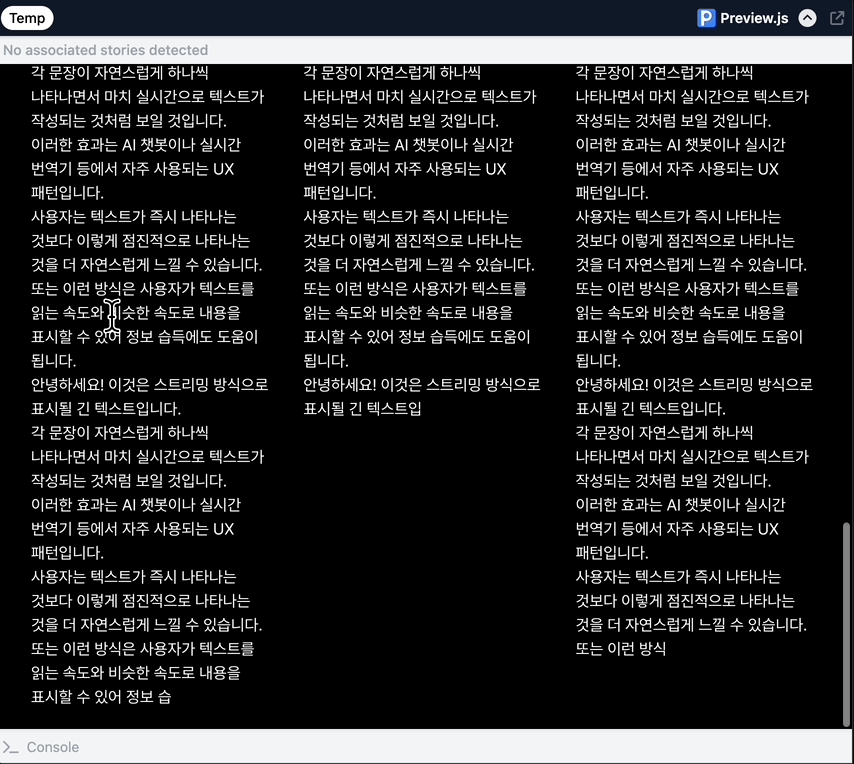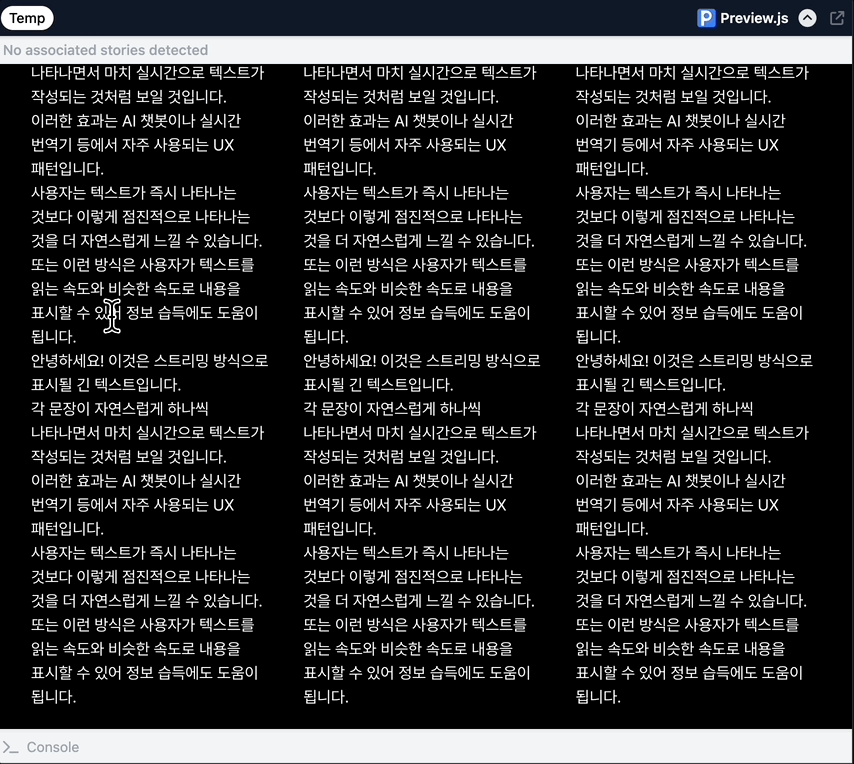
<1: 바로보여주기, 2: 한글자씩 랜더링, 3: 동적 스케줄링>
LLM UI 개발에서 배운 것들
LLM 서비스의 프론트엔드를 개발하면서 많은 것을 배웠습니다. 처음에는 단순히 API를 연결하고 응답을 표시하는 것이 전부일 거라 생각했지만, 실제로는 훨씬 더 깊이 있는 고민과 해결책이 필요했죠.
기술적 도전이 가져다 준 인사이트
모델별 인터페이스 차이를 다루고, 스트리밍 응답을 자연스럽게 처리하는 과정에서 프론트엔드 개발자로서 중요한 인사이트를 얻을 수 있었습니다:
-
추상화의 중요성
- 프로바이더 패턴을 통한 모델 차이 흡수
- 일관된 인터페이스로 복잡성 감소
-
사용자 경험에 대한 깊은 이해
- 기술적 제약을 사용자가 느끼지 못하게 하는 것의 중요성
- 섬세한 최적화가 만드는 큰 차이
-
동적 대응의 가치
- 패턴 분석을 통한 지능적 대응
- 상황에 따른 유연한 전략 선택
앞으로의 과제
LLM 기술은 계속해서 발전하고 있습니다. 새로운 모델이 등장하고, 기존 모델도 업데이트되면서 프론트엔드 개발자의 역할은 더욱 중요해질 것입니다. 특히 다음과 같은 부분에서 더 깊은 고민이 필요할 것 같습니다:
-
더 나은 추상화 방법
- 새로운 모델과 기능을 쉽게 통합할 수 있는 구조
- 확장성과 유지보수성의 균형
-
더 섬세한 사용자 경험
- 네트워크 상태에 따른 적응형 UI
- 모델 특성을 고려한 최적화 전략
결국 프론트엔드 개발자의 가치는 이러한 기술적 복잡성을 얼마나 우아하게 다루느냐에 달려있다는 것을 배웠습니다. 작은 UI/UX 디테일 하나하나가 모여 서비스의 완성도를 결정하게 되니까요.




저도 llm 프로젝트를 진행하면서 많이 어려웠는데 도움 됐습니다 ㅎㅎ 감사합니다