오늘 배워간 것
LSTM
LSTM의 input은 ct(cell state vector)와 ht 이고, 식은 아래와 같다.
ct,ht=LSTM(xt,ct−1,ht−1)
LSTM의 핵심은 cell state vector이다.
hidden state vector는 cell state vector를 한 번 더 가공하여 필요한 정보만 뽑은 벡터이다.
Forget gate
ft=σ(Wf⋅[ht−1,xt]+bf)
이전 time 스텝에서 넘어온 정보 중 일정 부분만 유지하도록 한다.
Input gate
it=σ(Wi⋅[ht−1,xt]+bi)
Gate gate
Ct=tanh(Wc⋅[ht−1,xt]+bc)
Output gate
ot=σ(Wo⋅[ht−1,xt]+bo)
New Cell State
Ct=ft⋅Ct−1+it⋅Ct
New hidden state
ht=ot⋅tanh(Ct)
GRU
Cell state와 Hidden state의 일원화
GRU의 Hidden state는 LSTM의 Cell state와 유사하다.
zt=σ(Wz⋅[ht−1,xt])
rt=σ(Wr⋅[ht−1,xt])
ht=tanh(W⋅[rt⋅ht−1,xt])
ht=(1−zt)⋅ht−1+zt⋅ht : 가중치의 합이 항상 1로 나옴
역전파를 진행할 때 이전 cell state에 forget gate를 곱하여 업데이트하고, 필요한 정보를 덧셈을 통해서 만들기 때문에 Gradient vanishing/explode 문제를 해결한다.
Seq2Seq
Encoder와 Decoder로 이루어진다.
Decoder의 입력은 <SoS> 토큰으로 시작하고 <EoS> 토큰으로 끝난다.
Attention
디코더에서 어떤 단어에 집중해서 가져올 지 정함
결과가 별로면 다시 attention 수정 수행
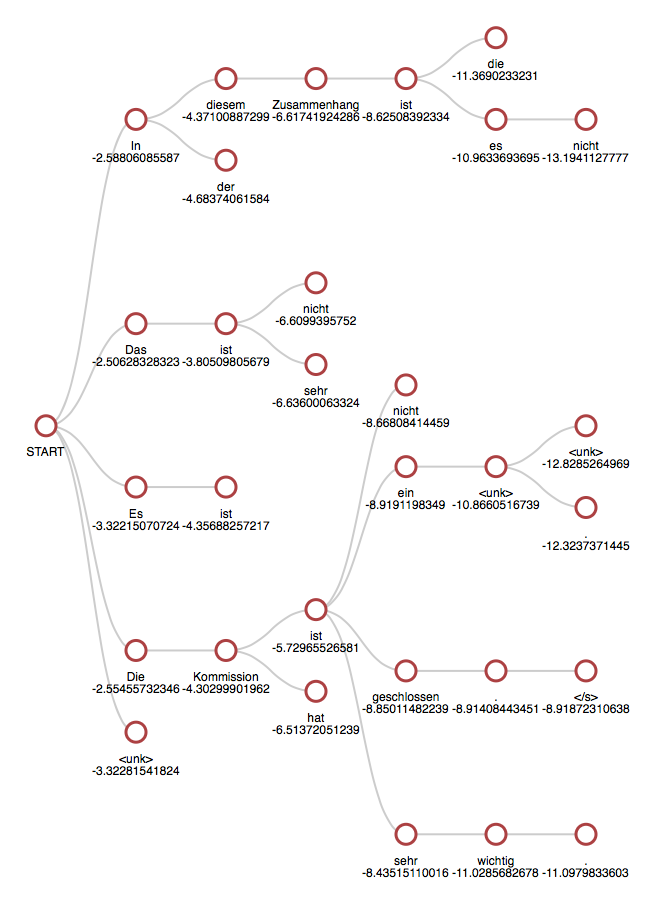
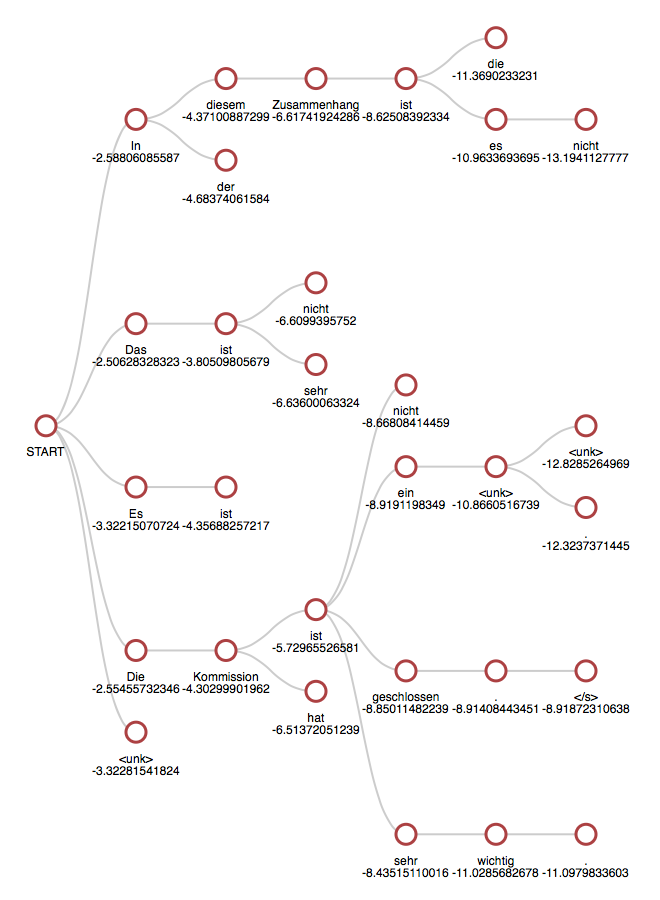
Beam search
보통 다음 단어를 예측하는 과정을 통해 생성을 진행한다.
하지만 그런 경우 한 단어라도 잘못 예측하면 원래 생성하려고 했던 문장과 다른 결과가 나온다.
각 단어가 등장할 확률에 대해서 모두 곱하고 로그를 씌워서 최대 확률을 가지는 경우를 찾아낸다.
k가 5일 때의 beam search의 예시이며, k는 보통 5에서 10으로 둔다고 한다.
<출처: https://opennmt.net/OpenNMT/translation/beam_search/>
score의 식은 다음과 같다.
score(y1,...,yt)=i=1∑tlogPLM(yi∣y1,...,yi−1,x)
그렇기 때문에 길이가 긴 문장일수록 점수가 낮아지게 된다.
이를 보완해주기 위해서 길이에 따라서 정규화 해준다.
score(y1,...,yt)=t1i=1∑tlogPLM(yi∣y1,...,yi−1,x)
BLEU
precision=length_of_prediction#(correctwords)
recall=length_of_reference#(correctwords)
F−measure=21(precision+recall)precision∗recall
위와 같은 지표는 순서가 달라져도 성능이 높게 나오므로 새로운 지표가 필요하다.
그렇게 등장한 BLEU(BiLingual Evaluation Understudy)
재현율보다는 정확도를 더 고려한 점수.
BLEU=min(1,length_of_referencelength_of_prediction)(i=1∏4precisioni)41
전항은 Brevity penalty로 길이값을 비교해서 가중치를 준다.
길이가 짧은 문장들이 높은 점수가 나오는 것을 방지하기 위함
위 식이 시사하는 바는, 1-gram 부터 4-gram precision을 모두 계산해서 연속된 단어들이 잘 나오는지 확인하는 것이다.
서두르지 말고,
한 발짝씩 나아가기