오늘 배워간 것
Bi-Directional RNN
RNN의 경우 long-term dependancy에 대한 문제가 발생한다.
정보가 유실, 혹은 변질될 가능성이 높다.
그렇기 때문에 단방향이 아닌, 양쪽 방향에서 RNN을 진행하여 이를 보완할 수 있다.
양방향에서의 hidden state를 concat하여 각 단어에 대한 hidden state를 계산한다.
Transformer
Query : 주어진 벡터들 중에 어떤 벡터를 선별적으로 가중치를 가져올 지 기준이 되는 벡터
Key :내적을 통한 유사도를 구할 때, Query와 곱하는 벡터
Value: 가중치가 실제로 적용되어 가중 평균을 구하는 벡터
각 input vector가 query, key, value로 변환될 때 사용하는 가중치인 , , 가 있다.(선형 변환 행렬)
query 벡터와 key 벡터를 각각 내적한 후 softmax를 적용해서 합이 1인 확률 분포를 구한다.
위에서 구한 확률 분포와 value 벡터를 곱하여 최종 벡터를 구한다.
위 과정을 stack하여 하나의 softmax로도 계산할 수 있다.
가 커지면
의 분산이 증가한다.
softmax 내에서의 값이 커진다.
softmax의 값이 한 쪽으로 몰린다.
gradient의 값이 작아진다.(vanishing)
=> 이를 해결하기 위해 Scaled Dot-Product Attention을 이용한다.
Multi-Head Attention
어떤 시퀀스가 주어졌을 때 동일한 쿼리에 대해서 여러 측면에서 정보를 뽑을 필요가 있는 경우가 생김.
- 여러 Head에 대해서 encoding을 진행한 후 모두 concat
- 로 Linear tansform
Block-Based Model
Residual connection : 입력 vector와 encoding vector 간의 잔차를 학습하게끔 하여 Gradient vanishing 해결, 학습 안정화
Layer Normalization : 학습을 안정화하고 성능을 끌어올리기 위함.
각각의 word 별로 벡터의 값을 정규화한 후 각 node 별로 affine transform(y=ax+b, 계수는 최적화하는 파라미터가 됨)
Positional Encoding
Transformer는 RNN과 달리 순서에 대한 정보를 학습할 수 없어서 적용된 기법.
각 dimension에 따라서 다른 주기를 가지는 삼각함수를 적용한다.
각 word가 등장하는 위치에 따라서 vector의 값에 PE 값을 더해준다.
Warm-up Learning Rate Scheduler
학습률을 일정 정도까지 끌어올렸다가 다시 감소.
극소값이 아닌 최대값으로 수렴할 수 있도록 도와준다.
High level view
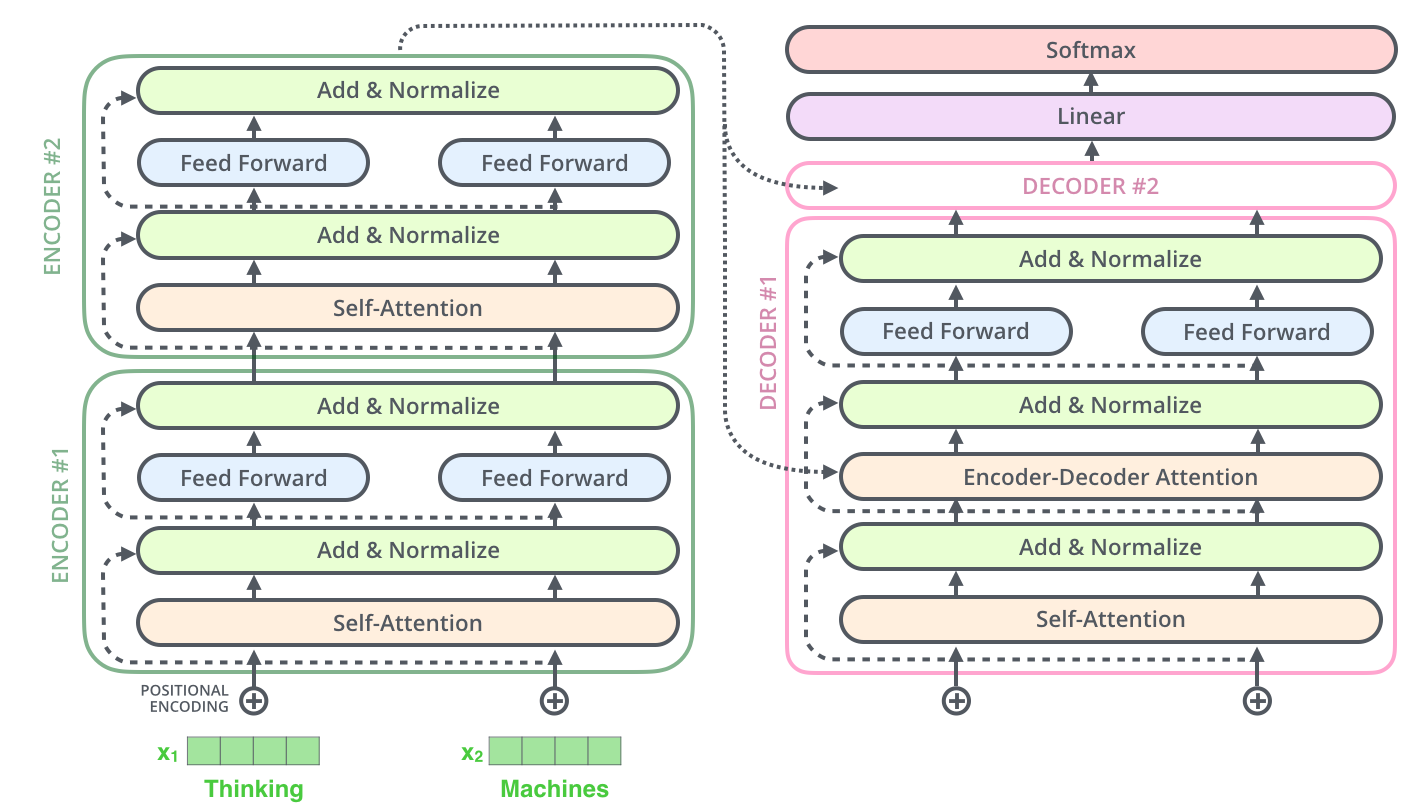
Decoder
Masked Self-Attention
의 연산 결과로 나온 행렬에서, 상삼각배열을 0으로 만든 후 다시 row 별로 정규화를 진행한다.
서두르지 말고,
한 발짝씩 나아가기
