Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(T5) 논문 리뷰
언어모델

T5 논문은 기존의 Transformer의 구조를 가지고 얼마나 많은 일을 할 수 있는지에 대해 보여주기 위해 쓰인 논문으로 보인다.
실제로 행해졌을 때의 성능 향상 때문에, 매우 큰 unlabeled text data를 통한 unsupervised pre-training은 NLP에서 주류로 자리잡았고, 이 때문에 web page에서 크롤링 된 매우 큰 데이터를 이용해 large size model을 학습하는 것이 더 좋은 성능을 낸다는 것이 가능하다는 것이 보여졌다. 지금 보면 당연한 이야기이지만 이 때는 무조건 Transformer의 크기를 키우는 것이 아니라 방법론적으로 해결하려는 시도가 많았기 때문에 결국 크기를 키우는게 모델을 여러모로 사용할 수 있다는 것을 알려준 이 T5 논문이 큰 의의가 있는 것 같다.
그리고 모든 text processing problem을 text-to-text problem으로 간주 하는 것이 이 논문에서의 기본 아이디어라고 한다.
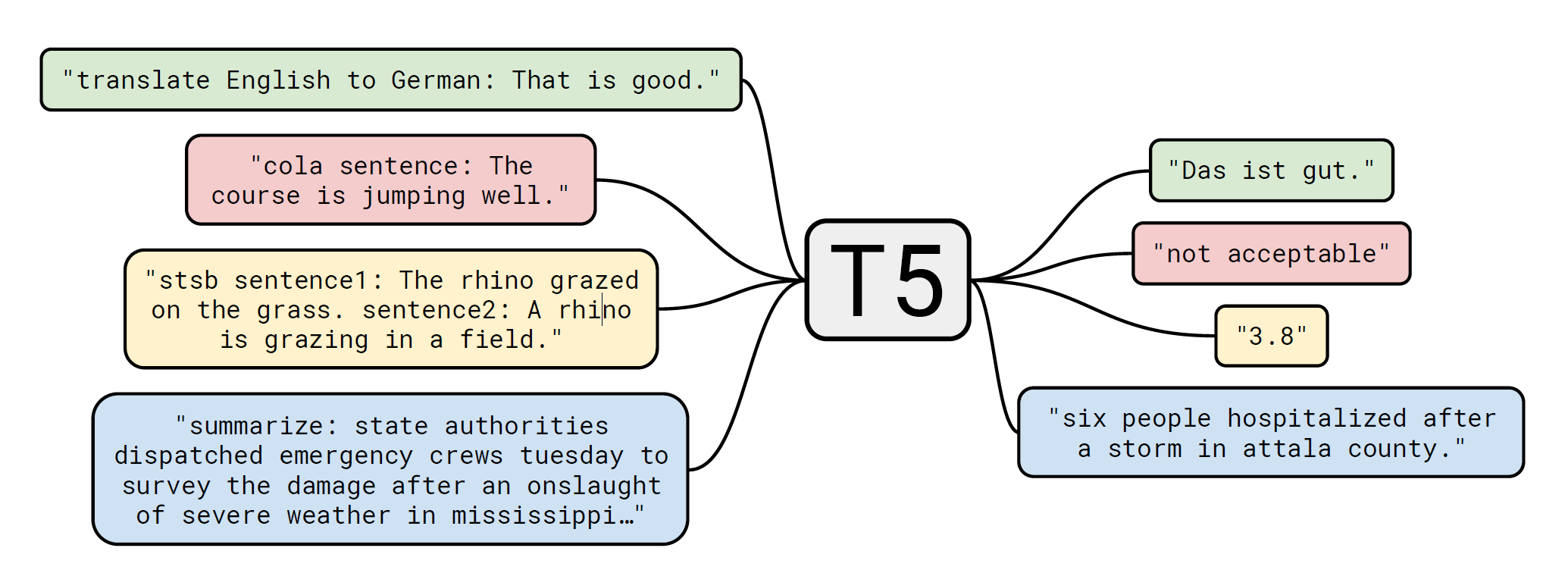
즉 스케일업을 하는 것 만으로 여러 작업에 transfer learning을 하여 사용할 수 있는 효과적인 모델 구조를 만드는 것이 T5의 목표이자 의의라고 할 수 있다.
모델 구조
T5에 쓰인 모델 구조는 기존의 Transformer 구조와 거의 비슷하지만, Layer Norm bias를 없애고, layer norm을 residual path 밖에 두고(Pre norm을 말하는 듯함), position embedding을 relative position embedding을 이용한 것이 다르다고 한다.
데이터셋
기존의 nlp 모델 학습을 위해 Common Crawl이라는 데이터셋이 많이 쓰였는데, 이 데이터셋은 html 크롤링 정보에서 text만 추출해서 만들어진 것이기 때문에 쓸모 없거나 자연어가 아닌 문장이 너무 많이 존재했다고 한다. 그래서 이를 개선하기 위해
- 마침표로 끝나는 문장들만 유지한다.
- 3문장 보다 짧은 페이지를 제외하고, 최소 5단어로 이루어진 문장만 유지한다.
- 나쁘거나 모호한 단어의 list에 포함되는 단어를 가진 페이지는 제외한다.
- "lorem ipsum"이란 문장이 포함된 페이지를 제거한다.
- 코드는 자연어가 아니므로 "{"가 포함된 문장을 제거한다.
- 위키피디아 등에서 추출된 문장은 quotation mark([1],[citation needed])가 존재하므로 이를 제거한다.
- 많은 페이지가 policy가 존재한다. 따라서 "terms of use", "privacy policy", "use cookies" 등이 포함된 라인을 제거한다.
- deduplication을 위해 3 sentence 길이로 중복되는 부분을 전부 제거한다.
또한 downstream task가 대부분 english 중점이므로 english로 쓰이지 않은 page는 제거한다.
이런 작업을 거친 데이터셋을 "Colossal Clean Crawled Corpus"으로 설명하고 있다.
Downstream tasks
이 논문은 모델의 general language learning을 강조하기 위한 논문이므로 수많은 downstream task에서의 성능을 측정한다.
하나의 모델에서 이런 여러가지 downstream task를 이루기 위해서 모든 task를 text-to-text로 간주한다.
그리고 어떤 task를 해야하는 지 모델에게 알려주기 위해 모델의 input sequence에 task-specific text prefix를 추가한다.
그 외 구현들은 다 세부적 사항이므로 논문에서 읽어보기를 추천한다.
