이전에 읽었던 논문들이 Pre-training에 치중하고, T5같은 경우엔 Pre-training 된 데이터를 downstream task에 바로 이용하거나, fine-tuning 하여 이용하는 느낌으로 접근했다면 이 논문은 그야말로 Fine-tuning에 치중하여 작성된 논문이다.
논문에서 집중한 부분은 task의 개수를 늘리고, model size를 늘리며, chain-of-thoughts를 고려한 finetuning을 하는 것이다. 이를 통해 기존의 pretrain 모델(T5, PaLM) 등에서 zero-shot, few-shot, CoT 성능 향상을 이루었다고 하고 있다.
데이터셋
Flan에서는 최대한 많은 task의 데이터셋에 학습을 하면 unseen task에 generalizing이 더 잘 된다는 것을 발견했다고 한다. 그래서 기존의 work(Muffin, T0-SF, NIV2, CoT)에서 나타난 task를 잘 섞어서 1836개의 finetuning task까지 scale up했다고 한다.

또한 Chain-of-Thought 데이터셋을 이용했는데, 위의 그림과 같이, Instruction finetuning 과정에서 예시(exempler)와 함께 학습하고, 또 chain-of-thought와 함께 학습했다고 한다.
또한 Muffin, T0-SF, NIV2에서는 instruction template을 그대로 사용하였고, CoT에선 10가지의 instruction template을 작성해 9개의 CoT 데이터셋에 직접 적용했다고 한다. Few-shot template을 위해 여러가지 예시 delimiter("Q:", "A:")를 이용하여 랜덤하게 적용했다고 한다.
학습
기존의 PaLM, T5 모델을 여러가지 사이즈별로 T5-small(80M)부터 PaLM(540B)까지 학습하는데, 각 모델 별로 몇가지 하이퍼 파라미터를 제외하고는 같은 설정으로 했다고 한다. 이 하이퍼 파라미터에는 learning rate, batch size, dropout, finetuning step이 있다.
Constant learning schedule에 Adafactor optimizer를 이용해 학습했고, 여러 training example을 packing하여 single sequence로 학습했다고 한다.
Finetuning에는 pretraining보다 훨씬 적은 시간을 소모했는데, 예를 들어 Flan-PaLM 학습을 위해 pre-training compute의 0.2%를 소모했다고 한다. 또한 JAX-Based T5X 를 이용했다고 한다.

평가
평가에는 finetuning data에 포함되지 않은 task의 성능에 집중했다.
이를 위한 벤치마크로는
(1) MMLU(수학, 역사, 법, 의학)
(2) BBH(어려운 task들)
(3) TyDiQA(8가지 언어의 QA)
(4) MGSM(다언어 수학 문제)
Scaling to 540B parameters
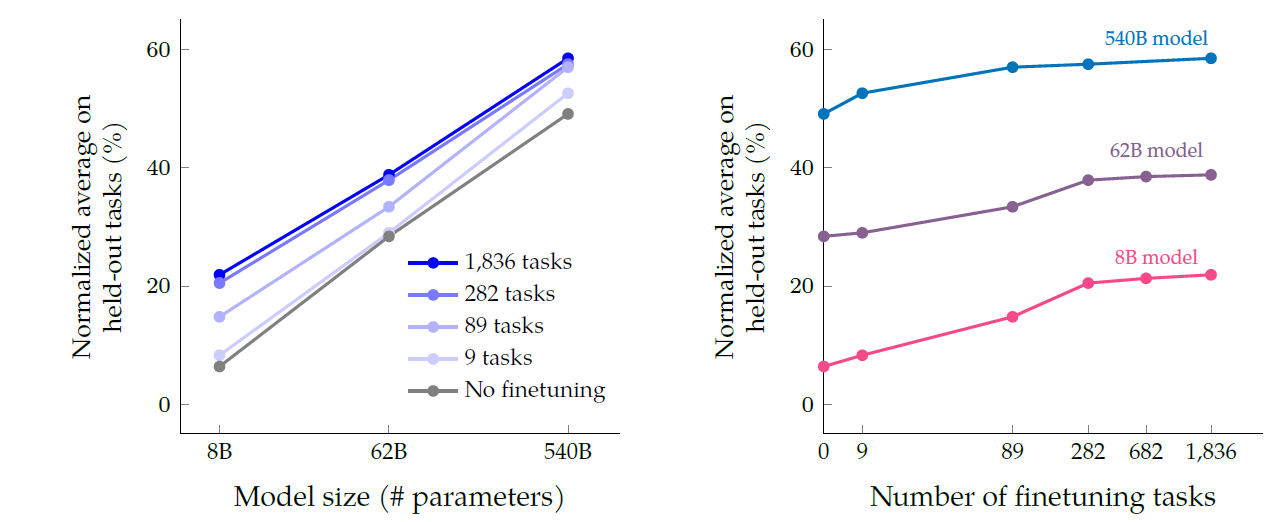
- 모델 스케일링은 항상 옳다.
- 282개의 task 이후에는 성능 향상이 적었는데, 이는 이후 task는 겹치는 부분이 많기 때문이고, 또 finetuning에서의 향상은 pretraining에서 배운 지식을 잘 표현하면서 나타나는데, task를 계속 늘리는 것이 이를 더 향상시키진 않기 때문이다.
- 모델 스케일이 증가하면 finetuned, non-finetuned 모델 둘 다 성능향상이 돋보인다. 따라서 finetuning이 작은 모델과 큰 모델 둘 중 어디에 더 영향을 주는지는 판단하기 쉽지 않다.
CoT Annotation finetuning
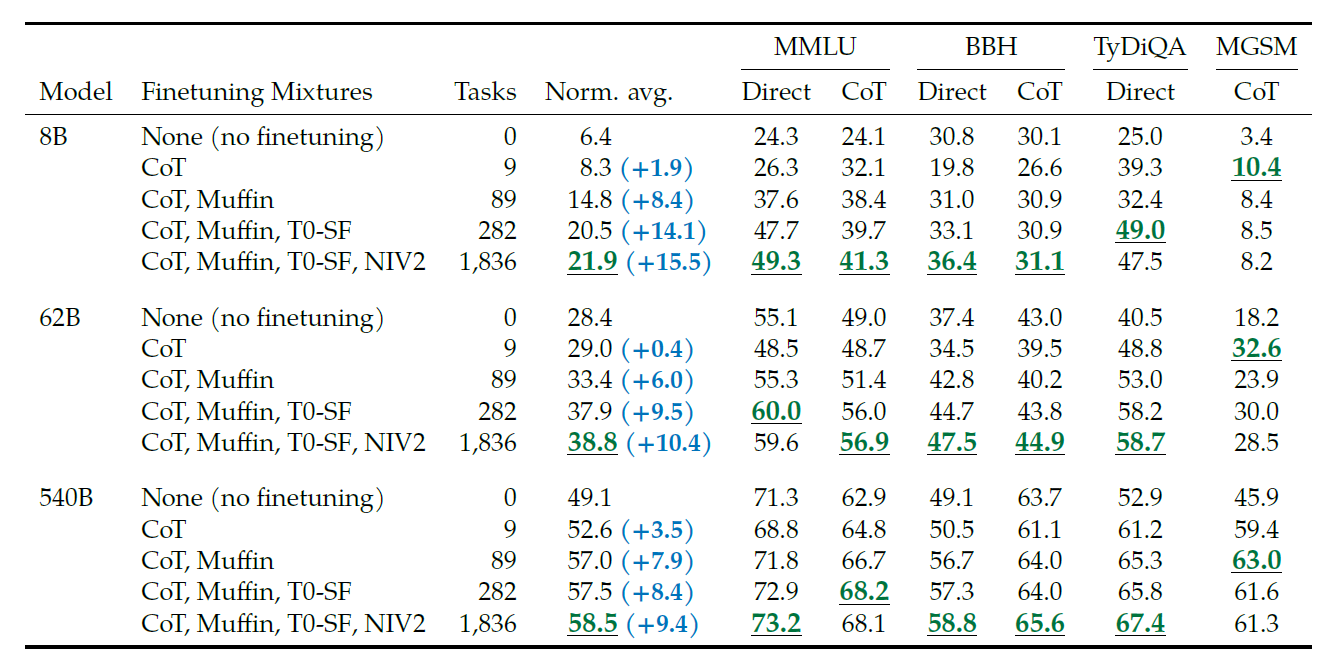
내 생각보단 CoT가 성능을 올려주는 task도 있었으나, 오히려 낮추는 task도 있었고, 모든 task에 학습을 했을 때 CoT의 비중이 너무 낮아 오히려 Direct가 성능이 좋은 상황도 벌어지는 것 같았다.
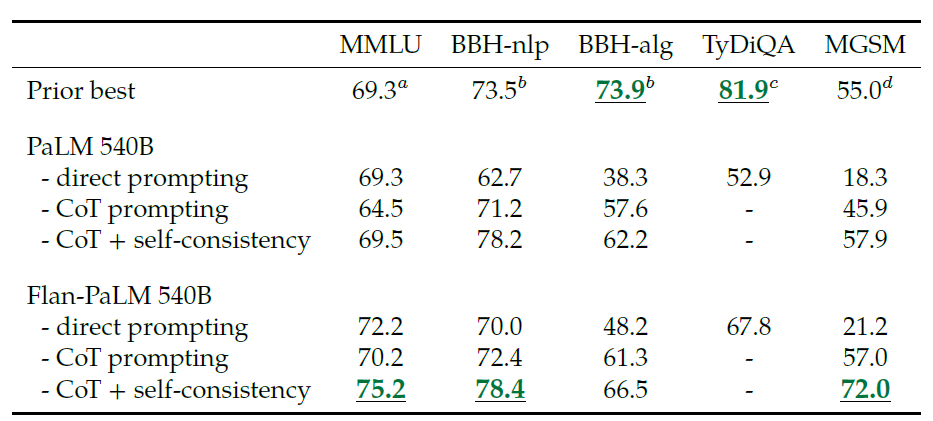
또한, 기존의 specific task에 대한 모델에 비해 성능이 낮은 경우도 좀 있기 때문에 만능이라고 할 수는 없을 것 같다. 여기서 나오는 self-consistency
CoT의 연장선으로 ensemble처럼 여러 답변을 생성하고 이를 다수결로 결과를 내는 것이라고 한다. 근데 이건 좀 공정한 비교는 아니지 않은가 싶다...
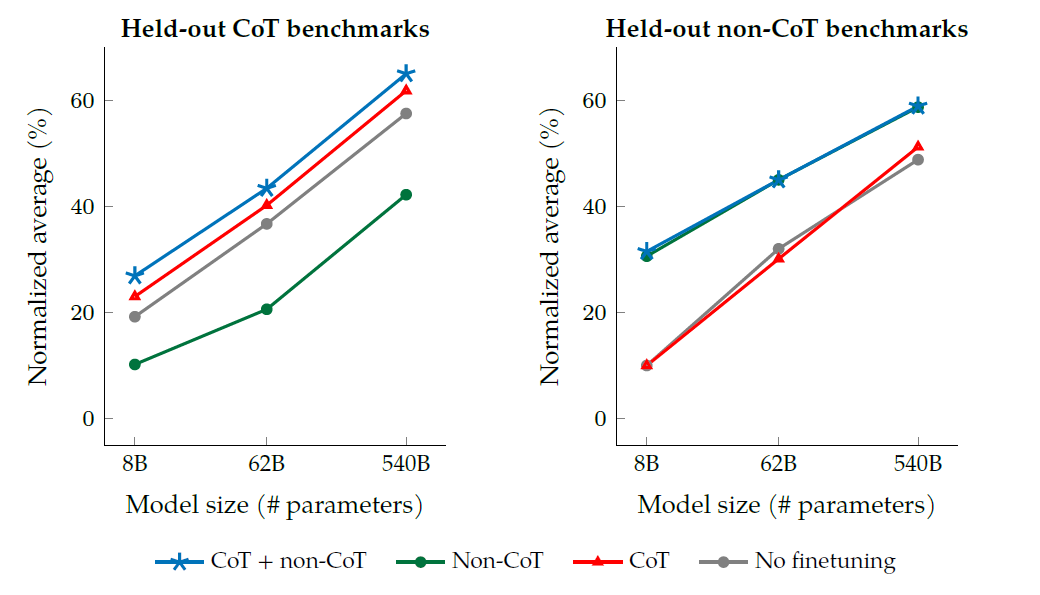
또한 CoT Benchmark에서도 CoT만 사용한 것보다 CoT를 사용하지 않은 걸로도 학습한 것이 성능이 좋았다. 또한, CoT 없이 하는 benchmark에서도 CoT를 포함해 학습하는 것이 성능 저하를 일으키지는 않는 모습이다.
이 그래프에서 중요한 점은 Non-CoT 데이터셋에서만 학습을 했을 때, 오히려 No finetuning에 비해 성능이 안나온다는 점인데 이는 instruction finetuning이 unseen task에 성능 향상을 주는 이전의 여러 논문을 생각해봤을 때 좀 맞지 않는 내용인 것 같다.
저자는 이에 대해 기존의 논문은 예를 들어 sentimental analysis를 제외한 모든 task에 finetuning 후에 nlp task에 평가하는 식으로 이 부분에 문제가 있었고, 또한 CoT reasoning을 하기엔 이전 모델은 너무 작았다고 평가한다.
이는 instruction fine tuning이 unseen task가 같은 prompting paradigm을 가질 떄만(CoT, non-CoT) 성능이 증가한다는 것을 시사한다. 따라서 CoT를 쓰고싶으면 CoT와 non-CoT 데이터가 둘 다 필요하다.
결론적으로 이 논문에서 말하고자 하는 바는 실제로 CoT data를 단지 9가지 섞는 것 만으로도 reasoning ability가 증가하는가에 대한 것이고, 실제로 이를 통해 zero-shot, 즉 Let's think step-by-step의 성능도 증가하는지를 확인했다는 것이다.
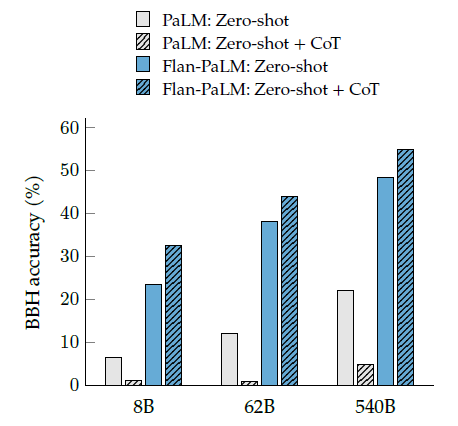
실제로 CoT로 finetuning한 모델에서 Zero-shot의 성능이 유의미하게 증가함을 확인할 수 있다. 즉 모델이 실제로 reasoning하는 능력을 갖추게 되었다는 의미이다.
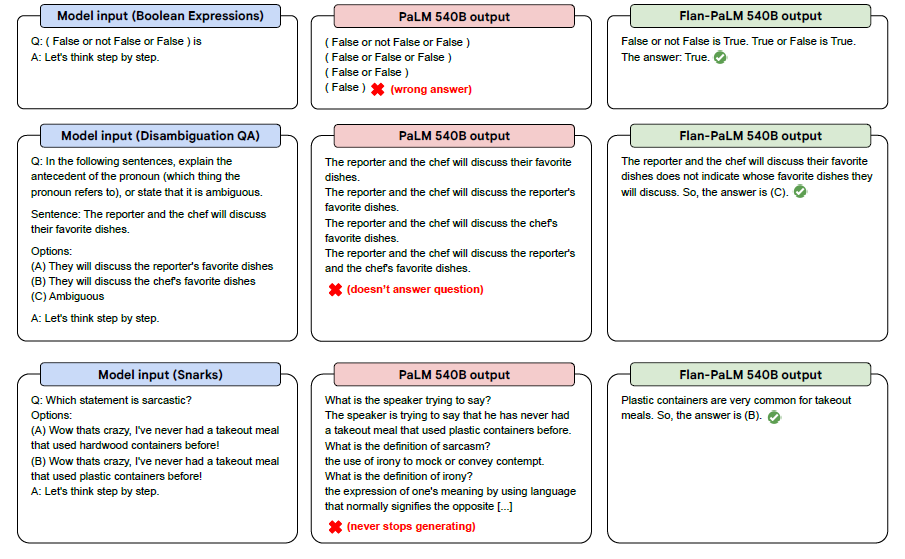
실제 모델의 결과인데, cherry picking을 좀 하긴 했겠지만 실제로 zero-shot 능력을 어느정도 갖춘 모습을 확인 가능하다.
결론
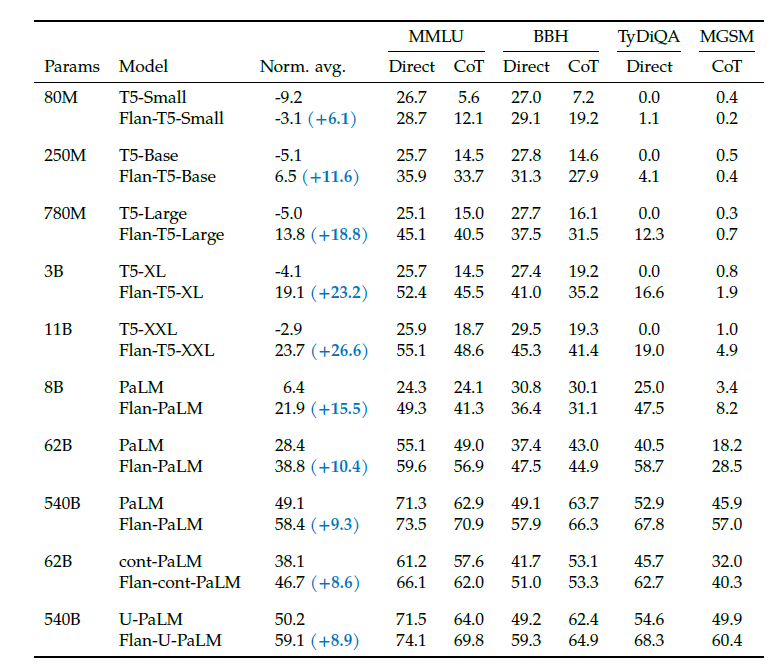
이 논문에서는 CoT 데이터셋을 기존 pretrained 모델에 finetune하는 것을 중점적으로 보고 있다. 이에는 encoder-decoder 구조의 T5는 물론 decoder-only 구조의 PaLM도 포함하고 있다.실제로 evaluation에 의하면 이러한 finetuning이 다른 모델들에 비해 average performance를 유의미하게 증가시킴을 확인할 수 있었다.
또한 T5가 finetuning으로 인해 가장 큰 성능 향상을 보였다고 한다. 그 이유로는 T5는 multilingual이 아니고, evaluation benchmark가 복잡하기 때문으로 생각된다. 또한 가장 강력한 모델은 UL2의 continued pre-training과 instruction finetuning을 결합한 U-PaLM 모델이라고 한다. 이건 특별한 건 아닌게 모델 크기도 크고 학습도 많이 한거기 때문에...
이로써 UL2의 continued pre-training과 instruction finetuning은 상호 보완적으로 사용되어 compute-efficient 학습을 할 수 있게 한다고 볼 수 있다.
!https://velog.velcdn.com/images/k106419/post/5ce99037-5d8f-4fe9-8a68-0dee0097bd04/image.png
또한 benchmark를 떠나 답이 정해지지 않은 open-form response를 생성하는데에 human rater들이 평가하기를 더 바람직한 대답을 했다고 한다.
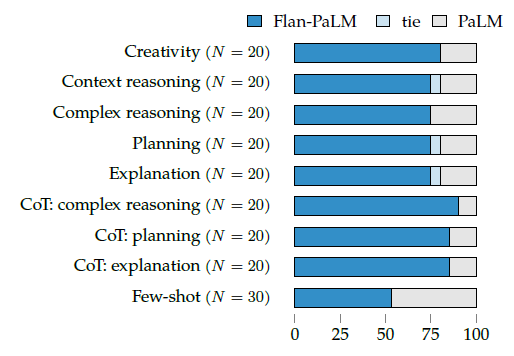
요즘은 언어 모델이 이런식으로 평가되는 경우가 많던데, 이에 대한 논문도 많이 읽어봐야 할 것 같다.
개인적인 생각
NLP 논문들은 어느순간부터 이런 식으로 prompt tuning이라던가, training의 디테일이라던가에 대한 논문이 많아지고, 이런 논문 위주로 흘러가는 것 같다. 언제 LLaMA2와 같은 오픈소스 llm 모델을 파인튜닝 해보면 이에 대한 깊은 이해가 생길 수 있을 것 같다. Appendix도 읽어야하는데 시간이 없어서 나중에 읽어볼 예정

{kind=link}