Graph Neural Networks Enhanced Smart Contract Vulnerability Detection of Educational Blockchain 논문 요약
GNN

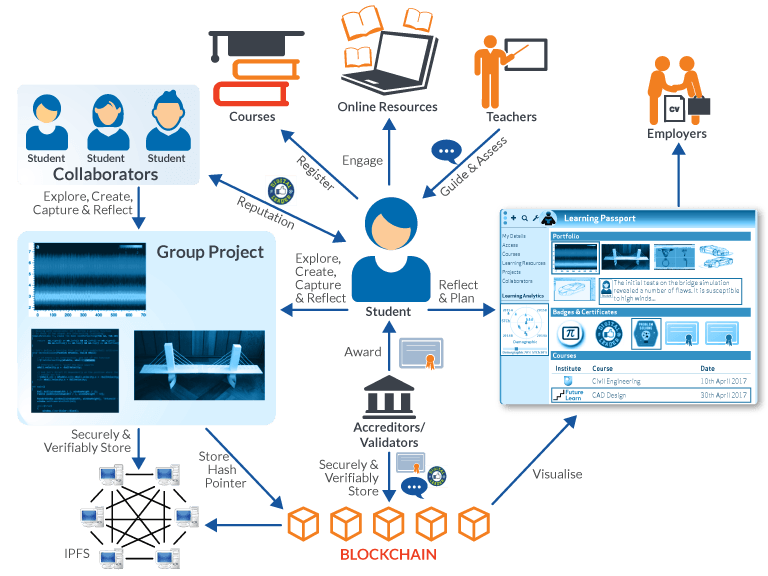
이 논문은 Educational Blockchain 1 2, 즉 블록체인을 교육에서 활용할 때의 문제점을 GNN을 이용해 해결하는 논문이다. 교육분야에서의 블록체인이 익숙하진 않은 패러다임이므로 위의 주소의 내용을 읽어본 후에 논문을 읽으면 도움이 될 것 같다.
개요
이더리움의 스마트 컨트랙트는 코드 실행이 가능해 여러 교육 플랫폼 등에 쓰이기 시작했다. 그러나 이더리움은 발행된 contract의 수정이 불가능하다는 점 때문에 문제가 되는 contract 또한 수정이 불가능했고, 취약점이 있는 contract가 수 많은 재산적 손해를 일으킨다는 문제가 있다. 따라서 이런 취약점을 찾는 것이 매우 중요해졌고, 이 논문은 contract의 bytecode의 흐름으로 the control flow graphs (CFG)를 만들어 이를 GNN으로 해결하는 방식을 채용한다. Smart contract는 time stamp에 따라 branch에 분기가 나뉘는 부분이 있고, 공격자는 이 부분을 조작해 취약점을 공략할 수 있다. 이 논문에선 timestamp dependency vulnerabilities를 찾는데 주력한다.
기존 방법
- Non deep-learning based method
1. Oyente - bytecode로 CFG를 만든 후에 Z3 solver를 이용해 conditional jumps를 분석한다. 이를 이용해 integer overflow errors를 포함해 7 종류의 취약점을 찾을 수 있다.- ContractFuzzer - fuzzy test를 이용해 취약점을 찾는 방법.
- deep-learning based method
1. RNN, LSTM network - RNN혹은 LSTM을 이용해 smart contract operation sequences에서 취약점을 찾는다. binary vector encoding representing the opcode을 이용한다.
GCN을 이용한 방법
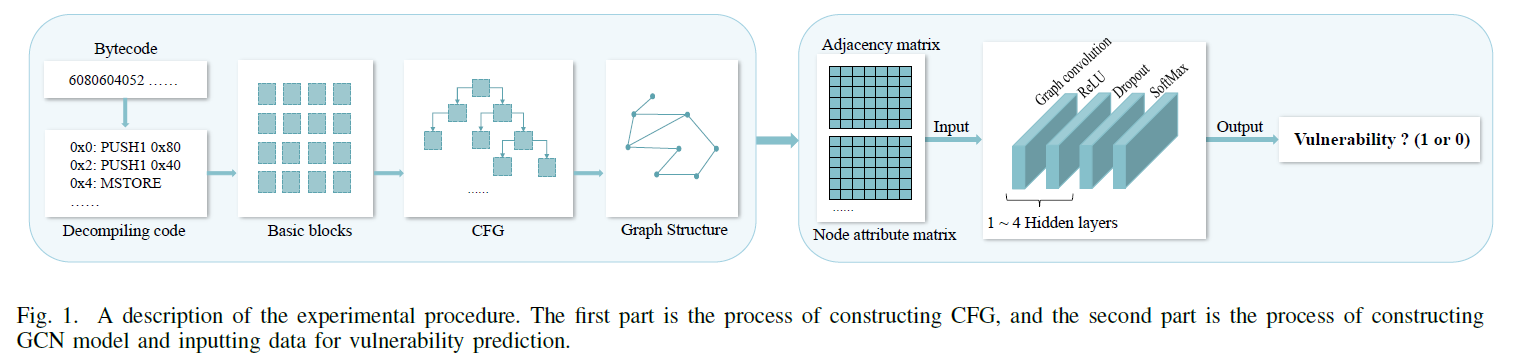
이 논문에선 GCN을 이용해 취약점을 찾는 방법을 제시한다.
1. contract bytecode를 decompile하여 OPCODE를 생성한다.
2. 이를 Basic block으로 나누어 edge를 추가해 CFG를 생성한다.
3. 이를 GCN layer에 통과시켜 취약점을 추론한다.
Bytecode 분석

- Contract의 bytecode는 세가지 부분으로 나뉜다.
- deployment code
- runtime code
- auxdata
EVM이 contract를 빌드할 때, contract user를 만든 후에 deployment code를 실행해 runtime code와 auxdata를 블록체인에 등록한다. 실제로 contract는 runtime code를 통해 실행된다. auxdata는 실행 도중에 저장되는 값이다.
-
bytecode를 디컴파일하면 2가지, instruction address와 instruction opcode를 얻을 수 있다.
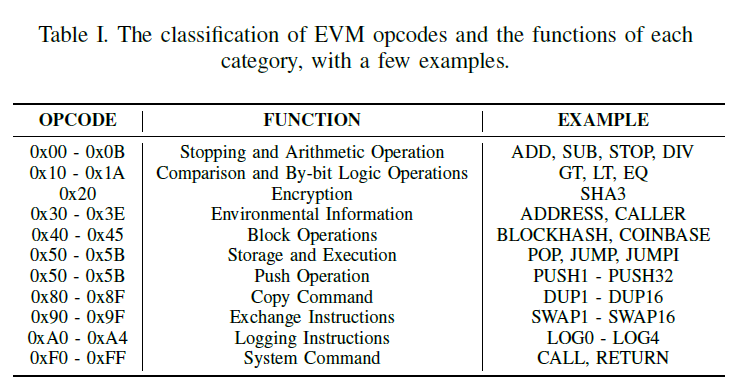
opcode는 위와 같은 명령어들로 이루어져 있다. 어셈블리 언어와 비슷함. -
Basic Block은 다음과 같은 원리에 의해 나눠진다.

1. 현재 instruction이 프로그램 혹은 서브루틴의 첫 instruction이라면 현재 basic block을 끝내고 새로운 basic block을 생성해 이 instruction을 넣는다.
2. 현재 instruction이 jump, branch statement라면 이 instruction을 현재 basic block의 last instruction으로 넣고, basic block을 끝낸다.
3. 두 경우가 아니라면 현재 basic block에 instruction을 넣는다. -
CFG 생성은 아래와 같은 단계로 이루어진다.
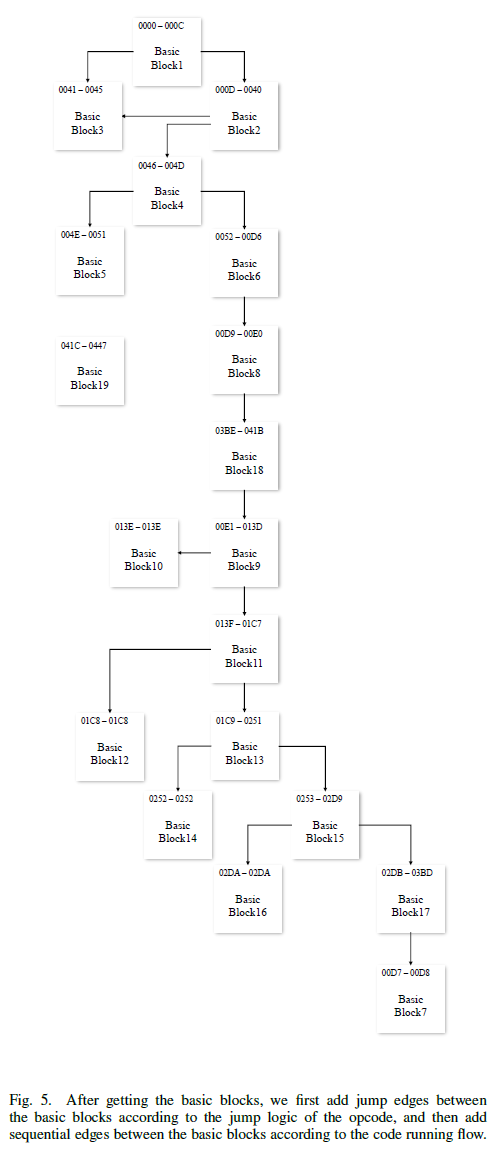
1. OPCODE를 basic block으로 나눈다.
2. transfer instruction(jump)에 따라 block 사이에 edge를 추가한다.
3. sequential dependent edge를 순차적으로 실행되는 block 사이에 추가한다.
데이터셋
Contract의 Source code를 컴파일러 버전을 맞춰 컴파일 하여 bytecode를 얻어낸 후에 취약점이 있는 코드라면 1로 레이블링하고 그렇지 않다면 0으로 한다. 이 논문에선 472개의 timestamp-dependent vulnerabilities를 가진 데이터를 이용했다고 한다.
결론
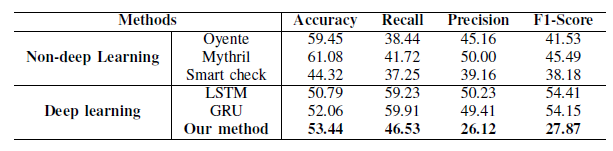
생각보다 성능이 낮아보이는데, 저자는 semantic processing part가 있지 않기 때문에 natural language processing을 통해 더 최적화된 feature data를 얻어낼 수 있다고 하고 있다. 근데 논문에는 feature를 어떻게 뽑아냈는지는 나와있지 않은 것 같은데..
또한 edge의 종류를 나눠 conditional jump, sequential jump edge 등으로 나눌 수도 있다고 언급되어있다.
내 생각엔 논문 자체가 좀 부실한 것 같다.. Education과 관련도 없는데 억지로 넣은 느낌이고 그냥 기존에 있던 CFG 그래프에 GCN을 적용한 것 뿐이라는 느낌이 든다. 그렇다고 opcode를 더 잘 분석해서 좋은 feature로 뽑아내는 과정도 없는 것 같고..
무엇보다 블록체인 자체와도 큰 관련이 없는 것 같다. 그냥 블록체인과 관련된 소스코드에도 사용할 수 있는 방법아닌가? 아마 이전에도 이런 방법을 이용해 취약점을 찾는 논문이 수두룩할 것 같은 기분..
사진 출처: https://mylove4learning.com/blockchain-in-education-possible-applications-of-this-technology/,
