LLaVA(Large Language and Vision Assistance)
LLaVA 모델은 기존의 LLM에서의 Instruction Tuning과 같은 작업을 Image-Vision 모델에 대해 수행한 모델이다. 위 논문에서는 기존의 Vicuna 모델을 LLM모델로 두고 CLIP의 vision encoder(Vit-L/14)를 이용했다.
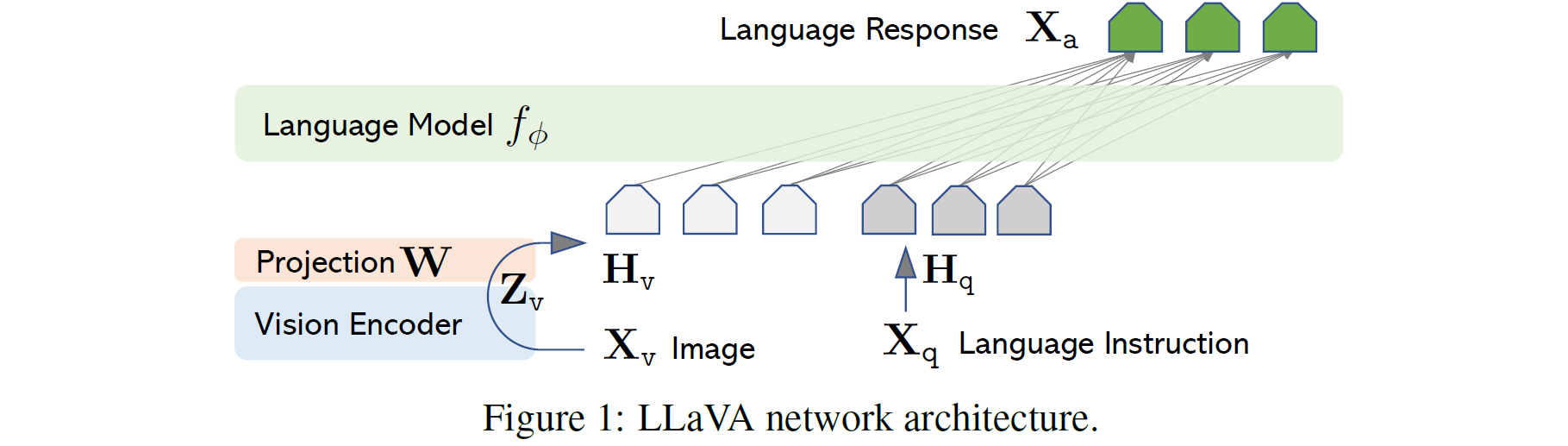
BLIP-2 모델과 비슷하게 LLM 모델과 Vision embedding을 align하는 느낌인데, Q-former와 같이 Projection W를 하나 두고 이를 학습하는 느낌이다.
학습
일단 각 이미지 에 대해 multi-turn conversation data를 이용해 학습을 하는데, 첫 번째 turn에선 instruct 데이터를 이미지와 question을 합쳐서 제공한다.
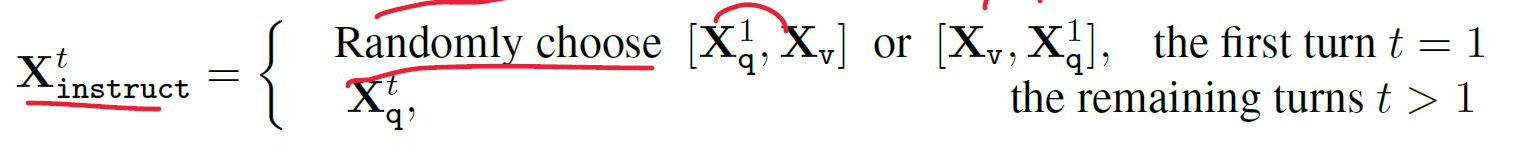

Vicuna 모델은 잘 모르지만 <STOP>을 EOS 처럼 이용하는 것 같다. 그래서 모델은 answer과 더불어 <STOP>을 예측해야한다.
모델을 학습하기위해 BLIP-2와 같이 2-stage로 instruction-tuning을 한다.
1. Pre-training for Feature Alignment
BLIP-2에서 image와 text간의 Q-Former에서의 Alignment를 학습하는 것과 같이 LLaVA의 첫번째 stage에서는 projection W를 학습한다.
이 Pre-training에서는 CC3M 데이터셋을 이용하는데, 이는 image-text pair로 이루어진 데이터셋이다. 이 때 CC3M에서 명사구를 추출하여 각 명사구의 frequency를 이용해 3 미만인 명사구는 빼고, 가장 작은 frequency를 가진 noun phrase부터 이 noun을 포함하는 caption을 candidate pool에 넣는다고 한다. Frequency가 100이상이면 100 길이의 subset만을 이용한다. 즉 모든 image caption pair을 이용하는 게 아니라 너무 같은 명사구를 포함하지 않도록 하고 너무 희귀한 명사구를 포함한 caption도 이용하지 않겠다는 것.
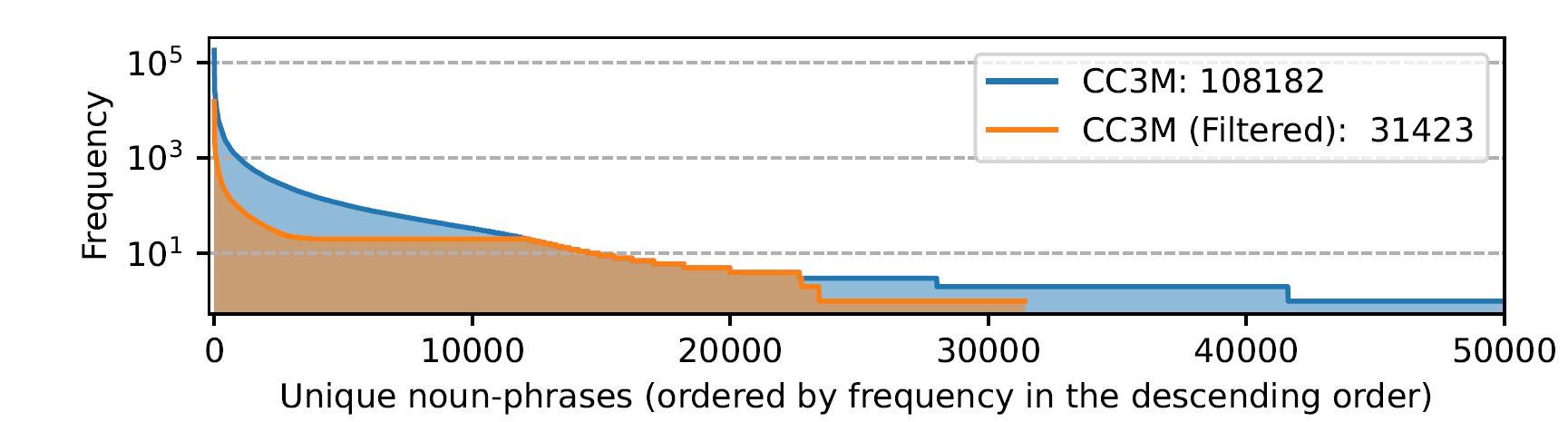
이를 이용해 데이터셋의 수를 줄인다.

는 위에서 랜덤하게 샘플하여 이용한다.
- Fine-tuning End-to-End
위에서 Image Embedding과 Text간의 Align을 했다면 여기선 LLM과 align을 하는데 이번엔 W와 LLM의 파라미터를 업데이트한다.
여기서 2가지 시나리오가 있는데,
- Multimodal Chatbot : 158K language-image instruction-following data를 이용해 파인튜닝하는데, 여기엔 conversation, detailed description, complex reasoning이 있다. conversation만 multi-turn이고 나머지는 single turn이다.

이 데이터를 생성하기 위해 사람이 다 직접할 수 없으니 GPT-4를 이용하는데, image를 visual feature로 변환한 후에 이를 GPT에 넣어 위와 같은 question과 Response를 생성하는 형식이다. 이를 위해 Caption과 Bounding Box를 이용했다고 한다.

위와 같이 in-context learning을 이용하여 생성을 한다. 이를 통해 query["context"]로부터 query["response"]를 생성해낼 수 있다.

예를 들어 위와 같은 예시를 넣을 수 있다.

위는 conversation에 대한 예시이다.
- Science QA : ScienceQA Benchmark를 잘 해낼수 있도록 tuning한다.
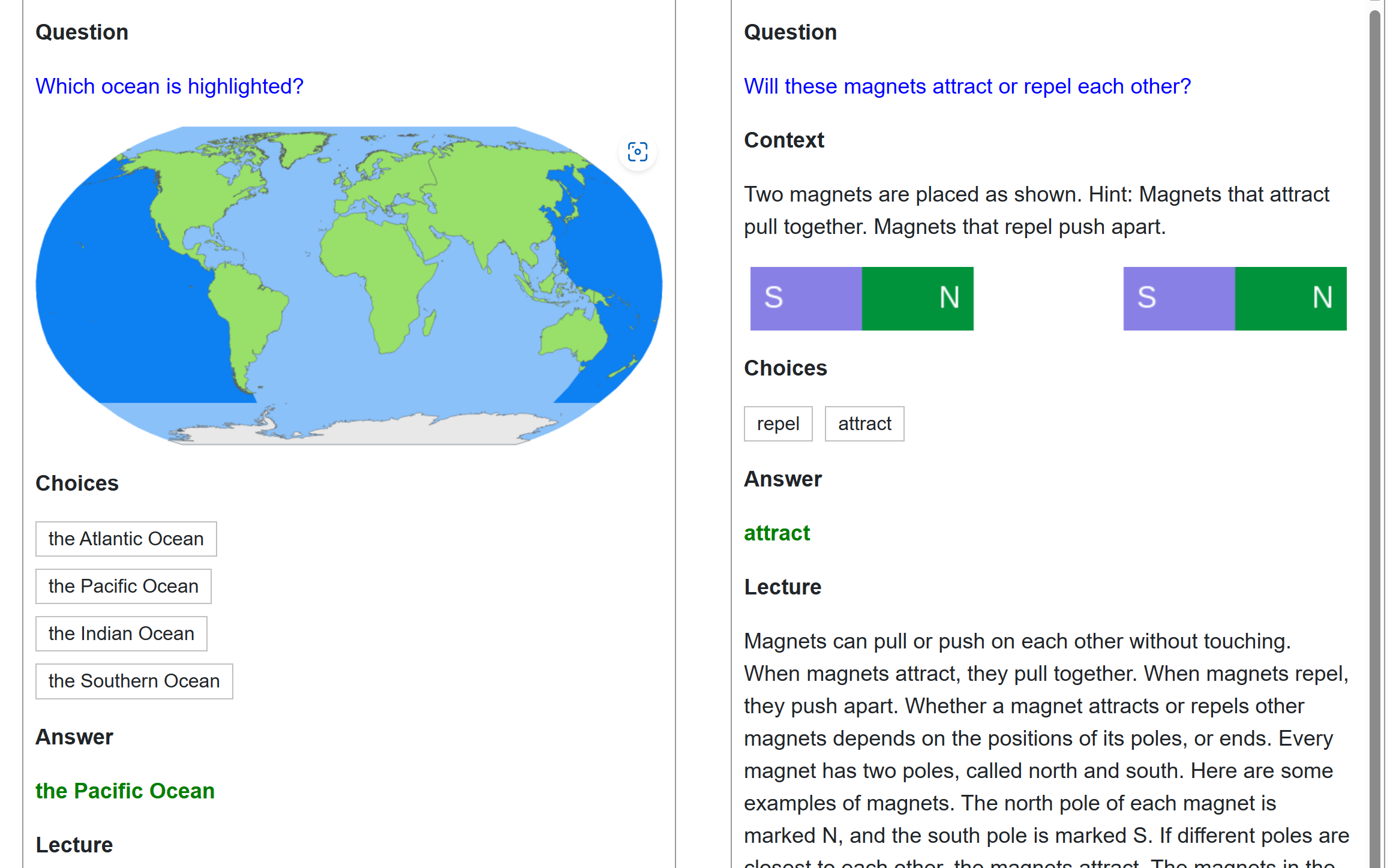
ScienceQA는 위와 같이 과학질문에 대해 Multimodal QA를 하여 대답을 하도록 하는 벤치마크이다. 여기서 question과 context를 로 두고 reasoning과 Answer를 로 두었다고 한다.
실험
위에서 나온 CC-595K 데이터셋으로 1 epoch을 2e-3의 learning rate, 128의 batch size로 학습 했다고 한다.
이후 LLaVA-instruct-158K 데이터셋으로 2e-5의 learning rate, 32의 batch size로 3 epochs 파인튜닝 했다고 한다.
결과

대충 잘 나왔다는 그림.
양적인 evaluation을 위해 GPT-4를 이용했다고 하는데, LLaVa 등 모델에 image, ground truth textual description(caption, bounding box인 듯?), question을 넣어 answer를 얻고, GPT-4에 question과 textual description를 넣어 theoretical upper bound를 만든다. 두 response를 question, textual description과 함께 judge(GPT-4)에 넣어 1부터 10까지 점수를 매기도록 한다. 이를 이용해 GPT-4의 response와 상대적인 점수를 매긴다.
COCO
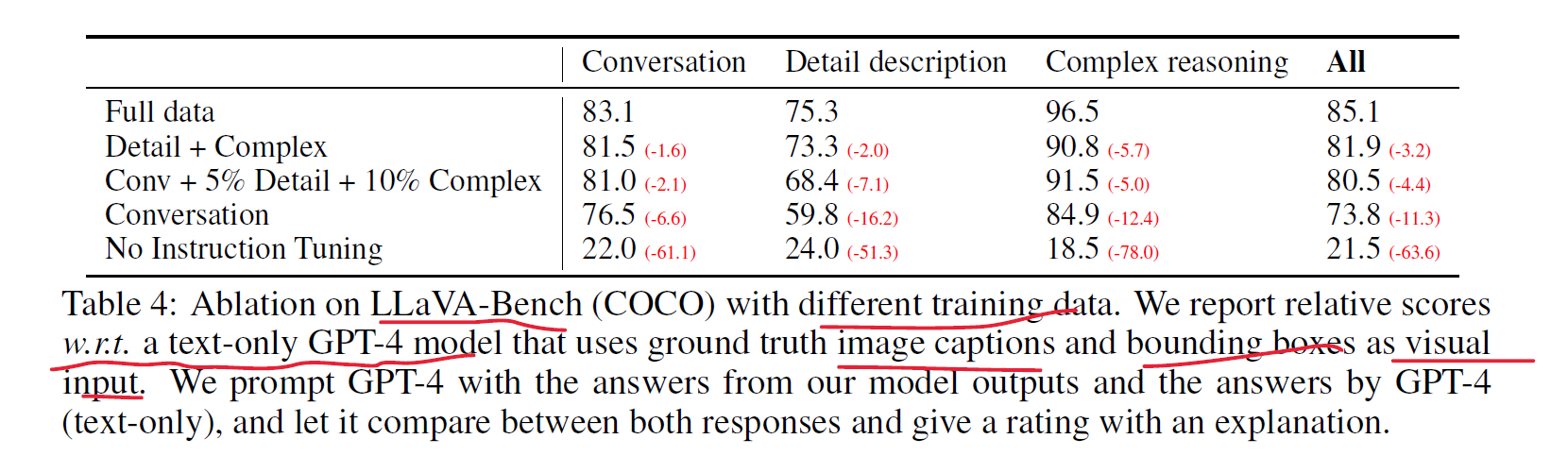
COCO-Val-2014에서 30개의 이미지를 가져와 각 이미지당 3개의 질문(conversation, detailed description, complex reasoning)을 하도록 했다고 한다(총 90 질문). 또한 이를 이용해 ablation study도 했다. 당연하게도 모든 데이터에 대해 finetuning 한 모델이 전반적으로 결과가 잘나왔다.
LLaVA-Bench
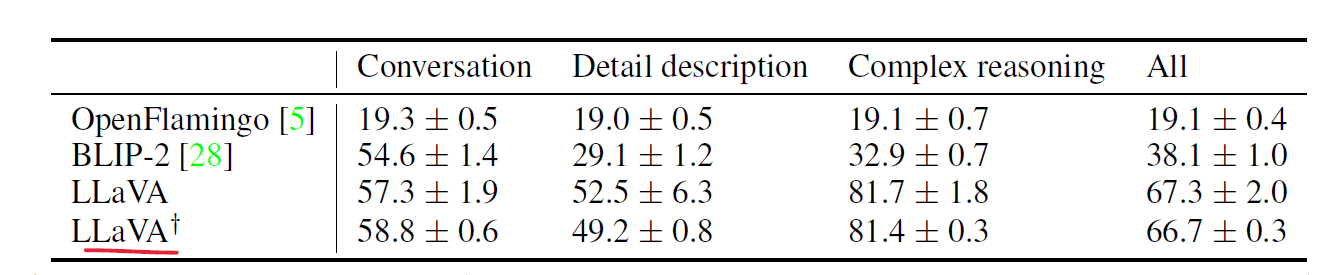
여러가지 주제에 대해 24 image with 60 question을 만들었다고 한다. 각 이미지는 자세하고 직접 만들어진 description, question으로 이루어져 있으며, 다른 모델들에 비해 좋은 결과를 냈다고 한다.
한계
LLaVA-Bench를 하며 한계를 직면했다고 하는데,

위와 같은 라면 사진과 함께 식당 이름을 알려달라고 하는 질문에 대해 대답을 잘 못했다고 한다. 이는 multilingual 이해 능력과 아마 RAG 같은 기술이 필요하다고 하는데 사실 이건 나도 대답을 못할 문제긴 하다.. 어캐함

또한 위와 같은 문제에서 Is there strawberry-flavored yogurt in the fridge? 라고 질문했을 때 yes라고 대답했다고 한다. 실제로는 블루베리 요거트와 딸기가 각각 따로 있는데, 이미지를 bag of patches로 이해하기 때문에 이미지의 복잡한 의미 해석은 힘든거 같다고 한다.
ScienceQA
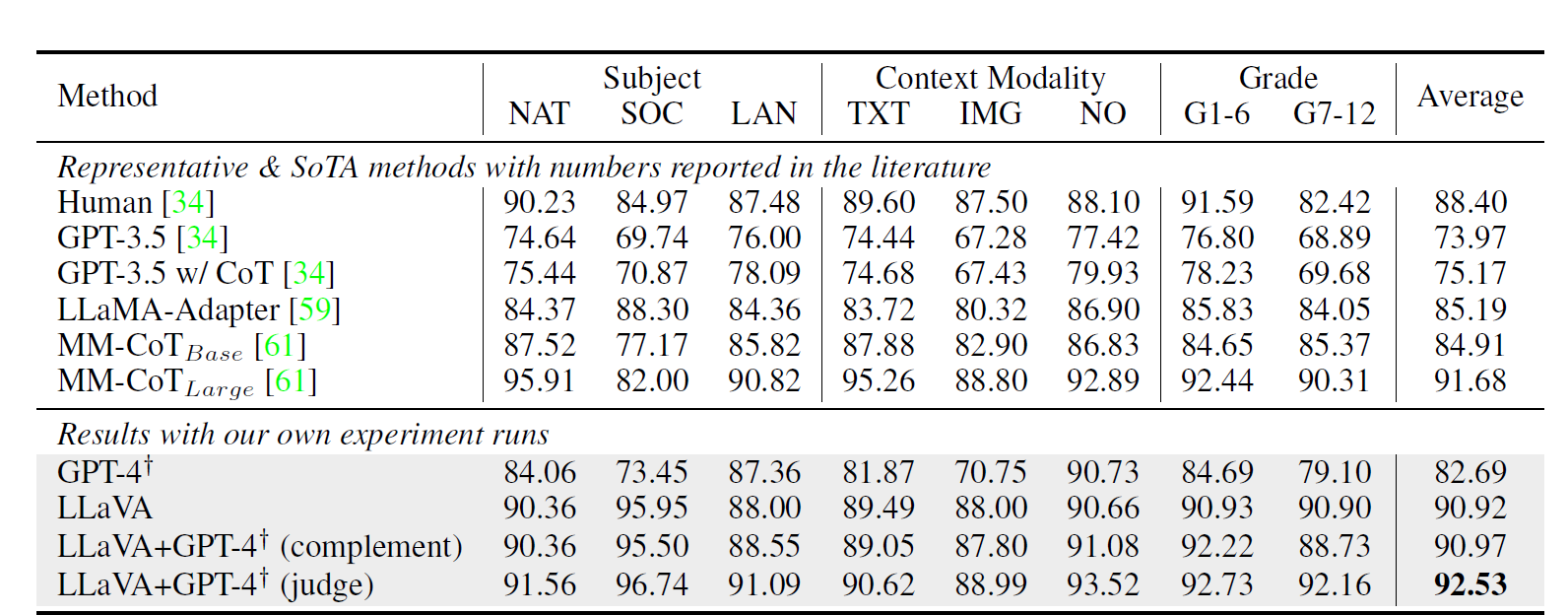
sota 모델이 평균 91.68의 성능을 내는데, 기존 LLaVA는 90.92로 sota보다 성능이 덜 하다는 걸 확인 가능하다. 그런데 GPT-4와 LLaVA모델을 같이 활용하면 성능이 크게 증가한다고 한다.
1. GPT-4 Complement : GPT-4가 성능을 제대로 못낼 때, LLaVA 모델을 이용하면 90.97의 성능을 낸다고 한다.
2. GPT-4 as the judge : 위의 judge와 같이, GPT-4와 LLaVA가 다른 답변을 내면, judge GPT-4에 두 결과를 넣어 최종 결과를 낸다고 한다. 이를 통해 92.53의 성능을 냈다고 한다.
Ablation
ScienceQA를 하며 모델의 여러 디자인에 대해 Ablation studies를 했다고 한다.
1. CLIP vision encoder의 last feature를 이용했을 때, 89.96의 성능으로 마지막 layer 전의 feature를 이용했을 때보다 0.96 낮았다고 한다. Vision encoder임에도 불구하고 Stable diffusion과 같은 모델에서 text encoder의 마지막 layer를 이용하지 않는 것과 비슷하게 더 좋은 성능을 보이는 게 좀 신기했다.
2. Chain-of-Thoughts
CoT도 이용했다고 한다. 일단 Answer-first 즉 non-CoT에 대해서 12 epochs 동안 89.77의 성능을 기록했다고 하고, reasoning-first 즉 CoT에 대해선 6 epochs만에 89.77의 성능을 기록했다고 하지만 이후에 성능 향상이 없었다고 한다. 이 부분에서 정확히 CoT가 어떤 식으로 이루어졌는지 모르겠는데 아예 성능 향상이 없었다는건 데이터셋에 문제가 있었거나 학습에 문제가 있었다고 느껴진다. 아마 CoT 데이터셋도 GPT-4로 생성을 했을거 같은데 뭔가 제대로 안이루어진듯? 꽤 중요한 부분인거같은데 저자가 그냥 빠르게 넘겨버렸다..
3. pre-training
BLIP-2와 같이 pre-training에 대한 ablation도 했는데 예상대로 당연히 크게 성능이 떨어졌다. 비록 W projection 하나라고 하지만 1 epoch라도 alignment를 하는 것이 크게 도움이 되긴 하는듯. 그렇다면 W projection 하나가 아니라 더 제대로 된 alignment를 했다면 더 좋지 않았을까 예상해본다.
4. Model size
13B에 비해 7B가 1.08 더 낮은 성능을 냈다고 한다. 당연히 Model size가 크면 성능이 달라지지만 생각보다는 적게 떨어진듯함.
Llava와 BLIP-2 모델의 차이가 어떤 식으로 날까 궁금하여 두 모델에 대해 질문을 해 보았다.
BLIP-2 모델을 직접 사용해보니
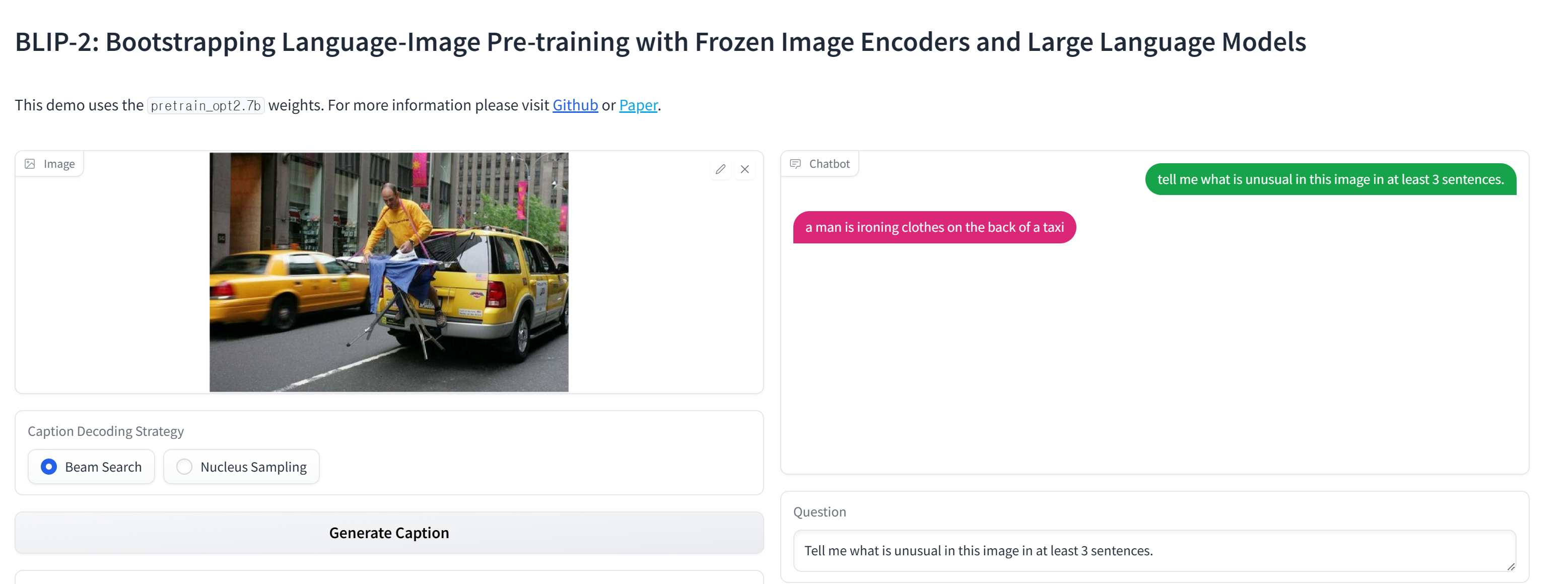
아무리 더 길게 써달라고 해도 Llava와 같이 긴 문장으로 써주질 않는다는 것을 확인했다. 아마 이런 task에 finetune을 제대로 하지 않았기 때문인 것 같다. 또한 모델이 내부적으로 어떻게 처리하는지는 모르겠으나 하나의 이미지에 여러 질문을 하는 것도 제대로 처리되지 않았다. 결국 llm을 이용하기 때문에 이 부분은 잘 처리하면 충분히 가능할 것으로 보이긴함.
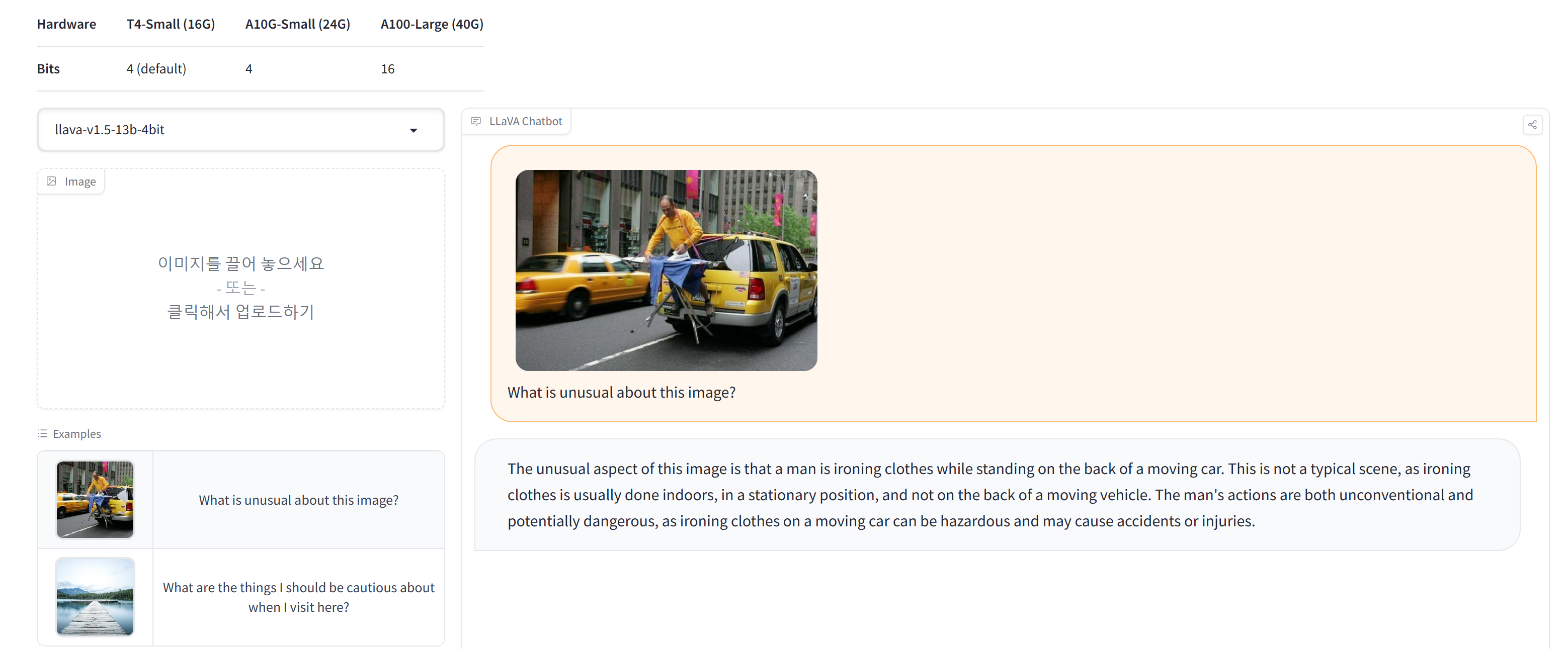
반면 Llava는 길게 해달라고 말하지도 않아도 자기가 혼자 길게 말한다. 심지어 4bit quant된 모델인데도 대답을 잘한다. 물론 llava에 쓰인 모델은 13b이고 blip-2에선 opt2.7b를 이용했기 때문도 있지만, 결국 이런 대답을 하도록 instruction-tuning을 하는게 중요한 것 같다.
하지만 BLIP-2와 Llava는 양립하는 것이 아니고, Llava는 CLIP을 이용한 visual encoder를 이용하기 때문에 이를 Q-Former로 대체한다면 prompt도 이용해 더 좋은 visual encoding이 가능할 것으로 생각된다. 생각되는 문제로는 그렇게 되면 prompt마다 visual encoding을 따로해야하나? 처음부터 새로 생성을 해야하나 싶긴함
결론
image와 llm의 instruction tuning에 대해 여러모로 연구를 하여 굉장히 의미있다고는 생각되지만 뭔가 아쉬운 점이 많이 보여서 후속 논문이 좀 있을 것 같은 느낌이다. 다음 논문으로는 LLaVAR을 읽어봐야겠다.
