멀티모달
1.BLIP-2 논문 리뷰
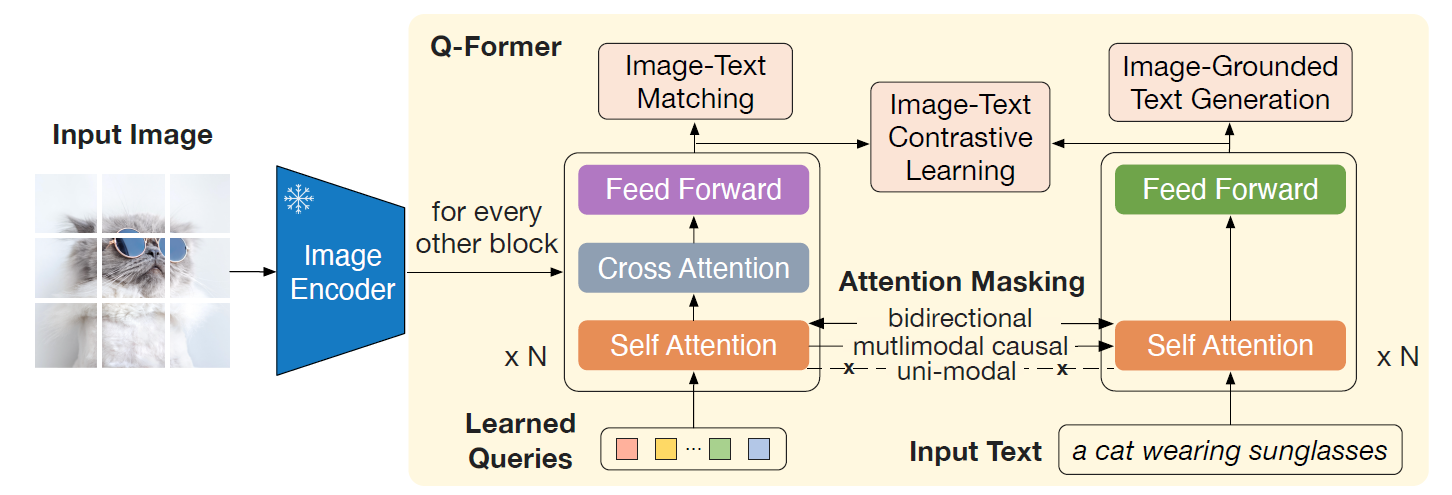
BLIP-2는 Vision-language pre-training(VLP)에서 기존의 방법과 같이 on-the-shelf 방식이 아닌 이미 pretrain 되어 있는 image encoder 모델과 LLM 모델, 즉 unimodal 모델을 compute-efficien
2024년 4월 3일
2.LLaVA 논문 리뷰
LLaVA 모델은 기존의 LLM에서의 Instruction Tuning과 같은 작업을 Image-Vision 모델에 대해 수행한 모델이다. 위 논문에서는 기존의 Vicuna 모델을 LLM모델로 두고 CLIP의 vision encoder(Vit-L/14)를 이용했다.BL
2024년 4월 9일