
대부분 수학적인 내용이라 이를 생략하면 요약할 점이 거의 없다.
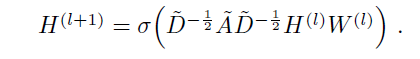
위의 layer-wise propagation rule을 이용해서 hidden features를 계산하면 된다는 것만 알면 된다. 이 때 이고 D는 degree matrix. activation function으로는 RELU를 쓴다.
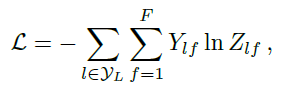
loss function은 label이 존재하는 값에 대해 cross entropy를 사용한다.
코드를 보면 cora dataset을 이용하고있다.

논문에서도 이용된 데이터셋이다.
Cora 데이터셋을 보면 cora.sites와 cora.content가 있다.
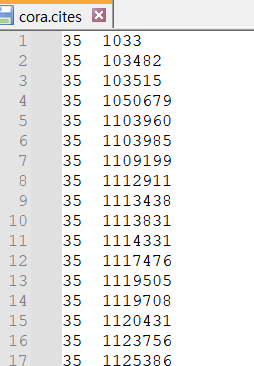
cora.cites는 edge를 나타낸다.
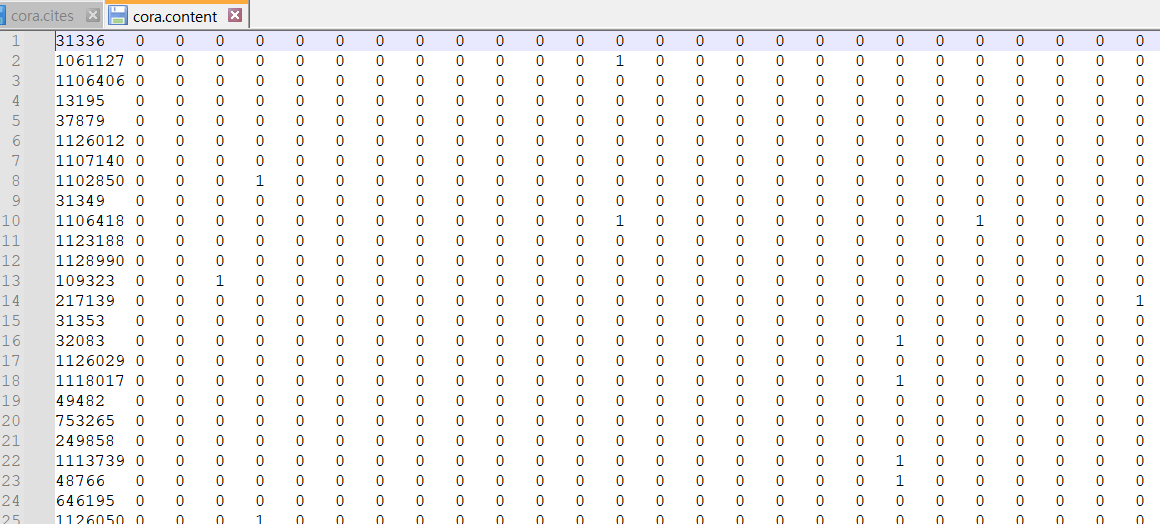
cora.content는 각 논문이 어떤 내용을 포함하고 있는지 알려주고 있으며 labeling이 되어있다.
class GraphConvolution(Module):
"""
Simple GCN layer, similar to https://arxiv.org/abs/1609.02907
"""
def __init__(self, in_features, out_features, bias=True):
super(GraphConvolution, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input, adj):
support = torch.mm(input, self.weight)
output = torch.spmm(adj, support)
if self.bias is not None:
return output + self.bias
else:
return output
def __repr__(self):
return self.__class__.__name__ + ' (' \
+ str(self.in_features) + ' -> ' \
+ str(self.out_features) + ')'
class GCN(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout):
super(GCN, self).__init__()
self.gc1 = GraphConvolution(nfeat, nhid)
self.gc2 = GraphConvolution(nhid, nclass)
self.dropout = dropout
def forward(self, x, adj):
x = F.relu(self.gc1(x, adj))
x = F.dropout(x, self.dropout, training=self.training)
x = self.gc2(x, adj)
return F.log_softmax(x, dim=1)모델의 구조는 매우 단순하다. 논문과 같이 adj matrix와 input을 계산하기만 하면 끝이다.
def load_data(path="../data/cora/", dataset="cora"):
"""Load citation network dataset (cora only for now)"""
print('Loading {} dataset...'.format(dataset))
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset),
dtype=np.dtype(str))
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
labels = encode_onehot(idx_features_labels[:, -1])
# build graph
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
idx_map = {j: i for i, j in enumerate(idx)}
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape)
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)
# build symmetric adjacency matrix
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
features = normalize(features)
adj = normalize(adj + sp.eye(adj.shape[0]))
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1])
adj = sparse_mx_to_torch_sparse_tensor(adj)
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
def train(epoch):
t = time.time()
model.train()
optimizer.zero_grad()
output = model(features, adj)
loss_train = F.nll_loss(output[idx_train], labels[idx_train])
acc_train = accuracy(output[idx_train], labels[idx_train])
loss_train.backward()
optimizer.step()주목할 점은 features는 dense matrix로 바꾼 후 tensor로 만들고, adj는 sparse tensor로 만들어서 처음엔 feature과 weight를 mm하고, 결과를 adj와 spmm한다는 점이다. 아마 features가 adj보다는 훨씬 dense해서 그런건가 생각되는데 그럴거면 애초에 dense matrix로 불러오면 될텐데 왜 처음에 csr로 불러오는지는 의문.
