
LightGCN은 기존의 graph recommendation에서 sota를 달성한 NGCF(Neural Graph Collaborative Filtering)에서 개선을 해 속도와 정확도 면에서 큰 발전을 이룬 모델이다.
NGCF는 graph classifier 모델인 GCN(Graph Convolutional Network)에서 영감을 받아 그 구조를 그대로 recommendation 모델에 적용을 시킨 모델이다. 높은 성능을 기록하였으나 GCN 모델의 한계점이 해결된 것도 아니고, recommendation work에 맞게 수정한 부분도 없어 이를 개선한 것이 LightGCN이라고 볼 수 있다.
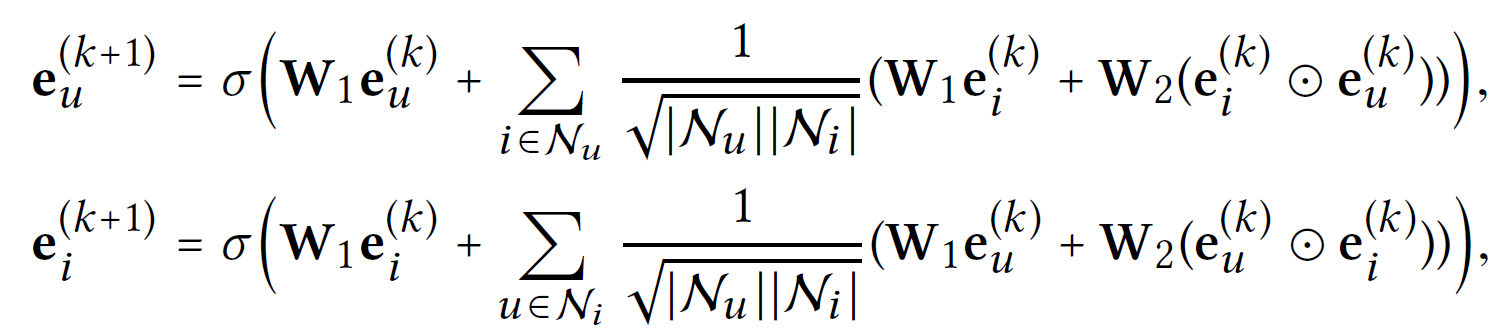
위는 NGCF의 구조이다.
GCN의 구조를 따르기 때문에 nonlinear activation function 과 feature transformation matrices 가 보인다. (는 neightbor을 의미)
node classification에선 각 node가 많은 feature를 가지기 떄문에 이러한 과정이 큰 의미가 있으나 recommendation task에선 각 node가 ID만을 가지고 있어 큰 의미가 없다는 것이 문제이다.
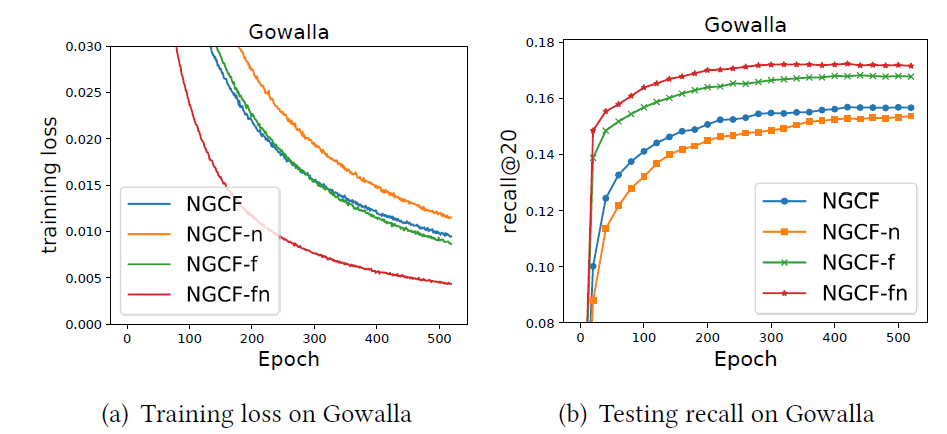
결론적으로 feature transformation과 nonlinear activation을 제거한 모델이 기존의 모델보다 더 빨리 converge하고 적은 loss와 높은 recall을 보이는 모습을 확인할 수 있었다.
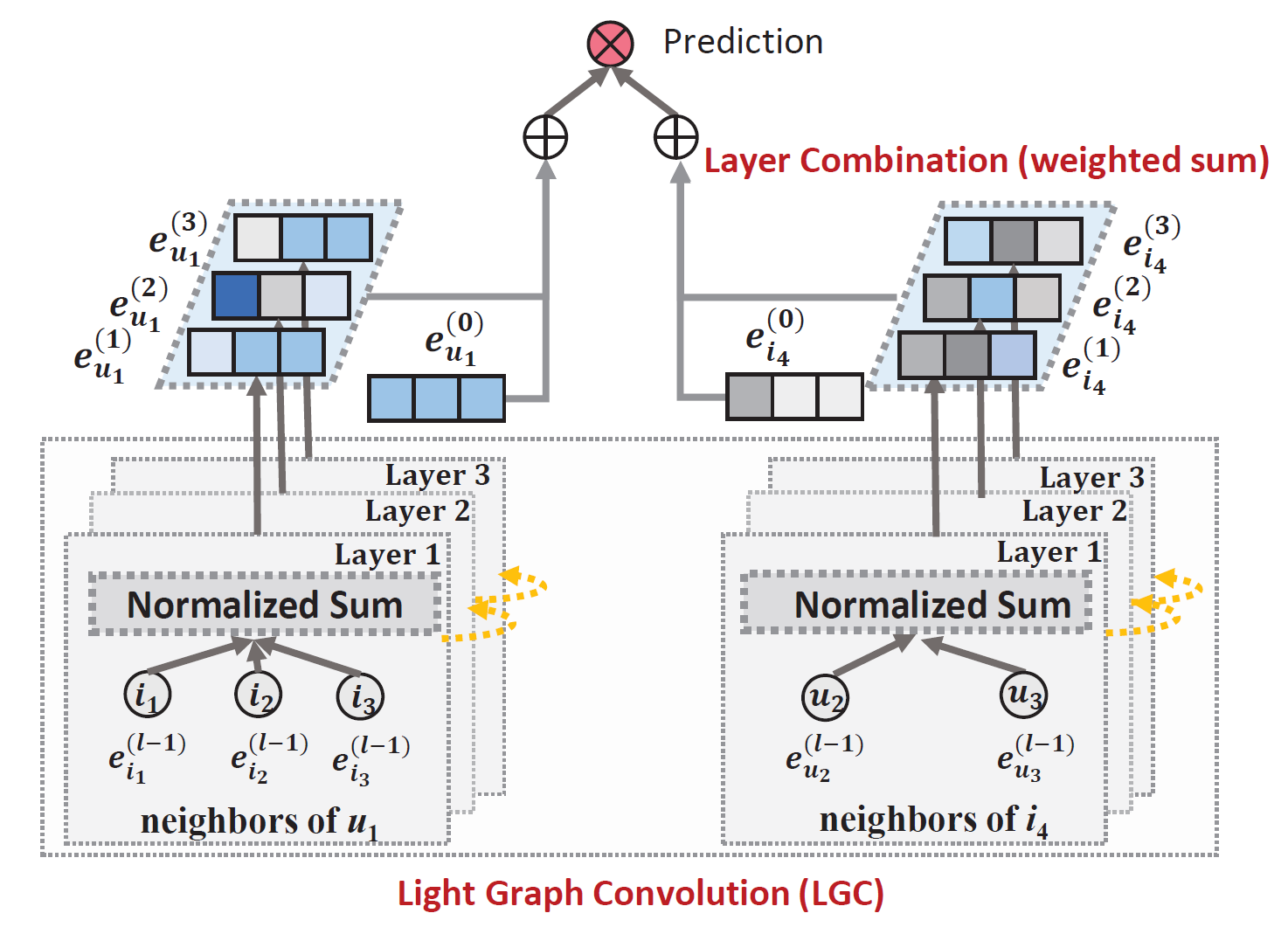
LightGCN은 기존 GCN 모델과 같이 graph convolution을 연속적으로 하며 feature smoothing을 한다.
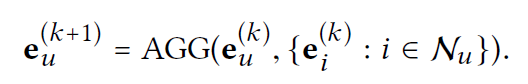
이 과정에서 Aggregator를 이용한다.
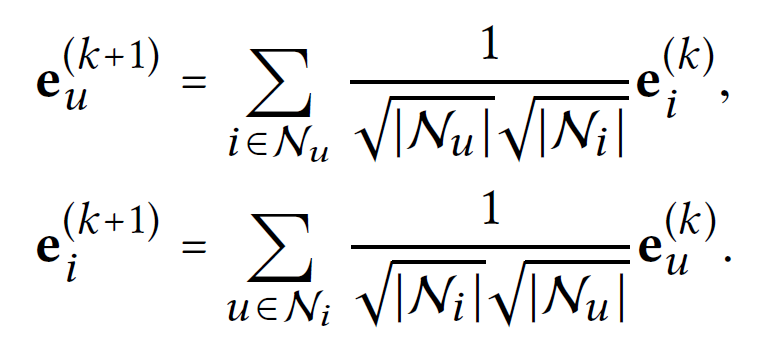
Aggregator로는 weighted sum, LSTM, bilinear interaction 등을 이용할 수 있지만 이러한 agg는 nonlinear activation과 feature transformation과 함께 쓰이고, CF모델엔 부담이 될 수 있다. 따라서 본 논문에선 weighted sum(normalized sum)을 이용한다.
모델을 보면 다른 GCN 모델들과는 달리 neighbor만을 이용하고 자기 자신은 이용하지 않음을 알 수 있다. 즉 self-connection이 존재하지 않는다.
이는 layer combination operation이 self-connection과 같은 효과를 가지기 때문이다.
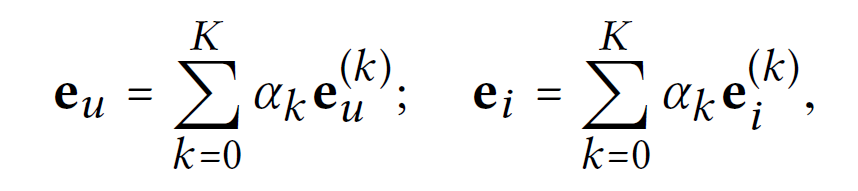
Layer를 모두 거친 후 마지막 단계에서 각 layer의 output embedding들을 합쳐서 최종 representation을 완성한다.
여기서 이고 이는 각 k-th layer embedding의 중요도를 나타낸다.(hyper parameter)
본 연구에선 모두 1/(K+1)로 설정한다.
layer combination을 하는 이유는 세가지이다.
1. layer를 거칠수록 feature smoothing이 너무 일어나기 때문에 마지막 embedding만 사용하면 문제가 생길 수 있다.
2. 각 layer의 embedding은 다른 의미를 가질 수 있다.
3. 이는 GCN의 self-connection과 같은 효과를 지닌다.
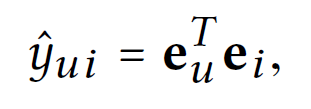
final prediction은 위와 같이 계산된다.
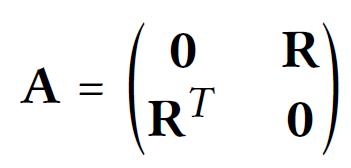
위의 내용을 matrix form으로 계산해보자.
user-item interaction matrix 일 때, A는 adjacency matrix of user-item graph이다.
0-th layer embedding matrix (T는 embedding size)이다.
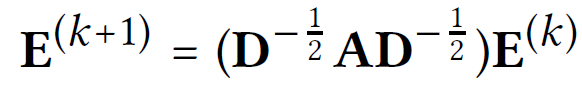
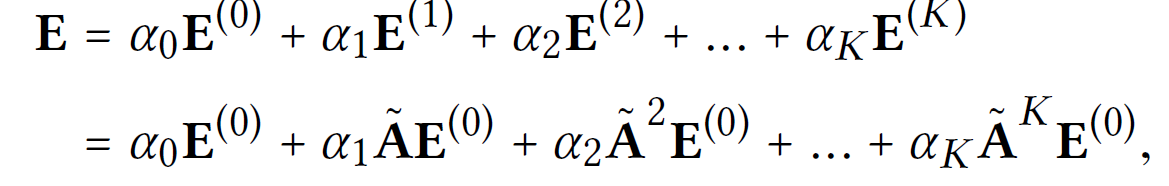
위와 같이 계산 가능하다.
다음 내용은 다른 모델과의 비교, 분석, 실험 결과 등이므로 생략하고 코드를 보자.
공식 github
모델에서 사용하는 Gowalla dataset에 대해서 알아보면

Gowalla edges는 다음과 같이 edge에 대한 정보를 가지고 있고,ㅠ
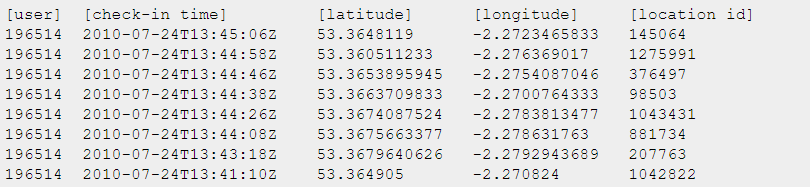
Gowalla_totalCheckins는 다음과 같이 user와 location에 대한 정보를 담고 있다.(이건 안쓰는듯)

코드 내에서의 train.txt 파일은 위와 같이 되어있으며
for l in f.readlines():
if len(l) > 0:
l = l.strip('\n').split(' ')
items = [int(i) for i in l[1:]]
uid = int(l[0])
trainUniqueUsers.append(uid)
trainUser.extend([uid] * len(items))
trainItem.extend(items)
self.m_item = max(self.m_item, max(items))
self.n_user = max(self.n_user, uid)
self.traindataSize += len(items)
self.trainUniqueUsers = np.array(trainUniqueUsers)
self.trainUser = np.array(trainUser)
self.trainItem = np.array(trainItem)위와 같은 코드를 통해 load를 한다.
즉 trainUser과 trainItem엔 edge의 개수만큼 element가 들어갈 것이고 trainUniqueUser엔 user의 수 만큼 들어갈 것이다.
# (users,items), bipartite graph
self.UserItemNet = csr_matrix((np.ones(len(self.trainUser)), (self.trainUser, self.trainItem)),
shape=(self.n_user, self.m_item))
self.users_D = np.array(self.UserItemNet.sum(axis=1)).squeeze()
self.users_D[self.users_D == 0.] = 1
self.items_D = np.array(self.UserItemNet.sum(axis=0)).squeeze()
self.items_D[self.items_D == 0.] = 1.
# pre-calculate
self._allPos = self.getUserPosItems(list(range(self.n_user)))
self.__testDict = self.__build_test()
print(f"{world.dataset} is ready to go")
def getUserPosItems(self, users):
posItems = []
for user in users:
posItems.append(self.UserItemNet[user].nonzero()[1])
return posItems
csr_matrix((data, (row_ind, col_ind)), [shape=(M, N)])
where data, row_ind and col_ind satisfy the relationship a[row_ind[k], col_ind[k]] = data[k].이를 통해 csr matrix를 구성한다.
def getSparseGraph(self)는 npz파일을 불러오거나 없다면 를 계산해 0norm_adj matrix를 만들고 이를 npz파일로 저장한다. (data/gowalla/pre_s_adj_mat.npz)
loss는 BPR loss(읽어보기를 추천)를 이용한다.
BPR loss를 이용할 때 user 별로 positive sample과 negative sample을 각각 sampling 하여 사용한다. (sampling.cpp 내에서 neg_ratio가 1이라면 positive, negative를 1개씩, 2라면 positive 1개, negative 2개 이런 식으로 샘플링해서 edge의 개수만큼(data의 크기) 모든 유저의 sampling을 통일해서(만약 유저가 10명이고 데이터가 100개라면 각 유저는 10씩의 sample pair를 가지게 된다. 근데 뒤의 코드를 보면 neg ratio를 늘려도 negative sample을 하나씩 쓰는걸로 보아 neg_ratio는 1로 고정하는게 맞는것 같다.)
def computer:
all_emb = torch.cat([users_emb, items_emb])
embs = [all_emb]
g_droped = self.Graph
for layer in range(self.n_layers):
all_emb = torch.sparse.mm(g_droped, all_emb)
embs.append(all_emb)
embs = torch.stack(embs, dim=1) #[n_layers+1, m+n, embed_size] -> [m+n, n_layers+1, embed_size]
light_out = torch.mean(embs, dim=1) # [m+n, embed_size)
users, items = torch.split(light_out, [self.num_users, self.num_items]) #[m+n, embed_size] -> [m, embed_size], [n, embed_size]computer 과정에선 embedding을 concat하여 의 matrix를 만든 후 n_layer만큼 반복해 adj와 matmul한다. 그 와중에 중간 embedding 값들을 전부 all_emb에 기록하고 각 layer에서 나온 embedding을 sum하여 users, items으로 나누어 return한다.
def forward(self, users, items):
# compute embedding
all_users, all_items = self.computer()
# print('forward')
#all_users, all_items = self.computer()
users_emb = all_users[users]
items_emb = all_items[items]
inner_pro = torch.mul(users_emb, items_emb) #[batch_size, embed_dim]
gamma = torch.sum(inner_pro, dim=1) #[batch_size]
return gamma
def getEmbedding(self, users, pos_items, neg_items):
all_users, all_items = self.computer()
users_emb = all_users[users]
pos_emb = all_items[pos_items]
neg_emb = all_items[neg_items]
users_emb_ego = self.embedding_user(users)
pos_emb_ego = self.embedding_item(pos_items)
neg_emb_ego = self.embedding_item(neg_items)
return users_emb, pos_emb, neg_emb, users_emb_ego, pos_emb_ego, neg_emb_ego
def bpr_loss(self, users, pos, neg):
(users_emb, pos_emb, neg_emb,
userEmb0, posEmb0, negEmb0) = self.getEmbedding(users.long(), pos.long(), neg.long())
reg_loss = (1/2)*(userEmb0.norm(2).pow(2) +
posEmb0.norm(2).pow(2) +
negEmb0.norm(2).pow(2))/float(len(users))
pos_scores = torch.mul(users_emb, pos_emb) #[batch_size, embed_dim] * [batch_size, embed_dim] => [batch_size, embed_dim]
pos_scores = torch.sum(pos_scores, dim=1) #[batch_size]
neg_scores = torch.mul(users_emb, neg_emb)
neg_scores = torch.sum(neg_scores, dim=1)
# users_emb와 pos_emb를 곱함으로써 유저의 embedding과 pos_emb의 유사도를 보는 듯 하다.
loss = torch.mean(torch.nn.functional.softplus(neg_scores - pos_scores))
return loss, reg_lossbpr loss에 대해서는 위의 글을 참고하면 된다. loss이기떄문에 neg_scores - pos_scores로 하여 pos_scores를 최대화하고 neg_scores를 최소화함.
def stageOne(self, users, pos, neg):
loss, reg_loss = self.model.bpr_loss(users, pos, neg)
reg_loss = reg_loss*self.weight_decay
loss = loss + reg_loss
self.opt.zero_grad()
loss.backward()
self.opt.step()
return loss.cpu().item()결론적으로 bpr loss를 이용해 optimize하게 됨.
def Test(dataset, Recmodel, epoch, w=None, multicore=0):
u_batch_size = world.config['test_u_batch_size']
dataset: utils.BasicDataset
testDict: dict = dataset.testDict
Recmodel: model.LightGCN
# eval mode with no dropout
Recmodel = Recmodel.eval()
max_K = max(world.topks)
if multicore == 1:
pool = multiprocessing.Pool(CORES)
results = {'precision': np.zeros(len(world.topks)),
'recall': np.zeros(len(world.topks)),
'ndcg': np.zeros(len(world.topks))}
with torch.no_grad():
users = list(testDict.keys())
try:
assert u_batch_size <= len(users) / 10
except AssertionError:
print(f"test_u_batch_size is too big for this dataset, try a small one {len(users) // 10}")
users_list = []
rating_list = []
groundTrue_list = []
# auc_record = []
# ratings = []
total_batch = len(users) // u_batch_size + 1
for batch_users in utils.minibatch(users, batch_size=u_batch_size):
allPos = dataset.getUserPosItems(batch_users)
groundTrue = [testDict[u] for u in batch_users]
batch_users_gpu = torch.Tensor(batch_users).long()
batch_users_gpu = batch_users_gpu.to(world.device)
rating = Recmodel.getUsersRating(batch_users_gpu)
#rating = rating.cpu()
exclude_index = []
exclude_items = []
for range_i, items in enumerate(allPos):
exclude_index.extend([range_i] * len(items))
exclude_items.extend(items)
rating[exclude_index, exclude_items] = -(1<<10)
_, rating_K = torch.topk(rating, k=max_K)
def getUsersRating(self, users):
all_users, all_items = self.computer()
users_emb = all_users[users.long()]
items_emb = all_items
rating = self.f(torch.matmul(users_emb, items_emb.t())) # self.f는 sigmoid
return ratingtest 데이터를 미니배치로 쪼갠 후에 모델에 넣어 가능성이 높은 item들을 찾는다. 이 때, test에 들어간 item의 rating은 -(1<<10)으로 설정해 선택되지 않도록 하고 torch.topk로 상위 k개의 item을 찾으면 추천 시스템을 만들 수 있다.
