
0. Data Structure
a) Array
배열 은 같은 형의 데이터 타입을 메모리에 저장하는 선형적 자료구조입니다.
논리적 구조와 물리적 구조가 동일합니다.
인덱스 번호가 0 부터 n-1까지 순서대로 있는 것처럼 메모리 주소 또한 순서대로 붙어있습니다.
1) Fixed Length, 길이가 정해져있습니다.
→ 만약 길이를 늘리려면 또 다른 메모리에 배열을 할당해야합니다.
2) Index 연산이 가능합니다.
3) input/output, insert/delete 가 n 개에 종속돼있습니다.
→ 배열의 요소를 중간에 넣거나 빼려면 최대 n-1 개의 배열의 요소가 이동을 하게됩니다.
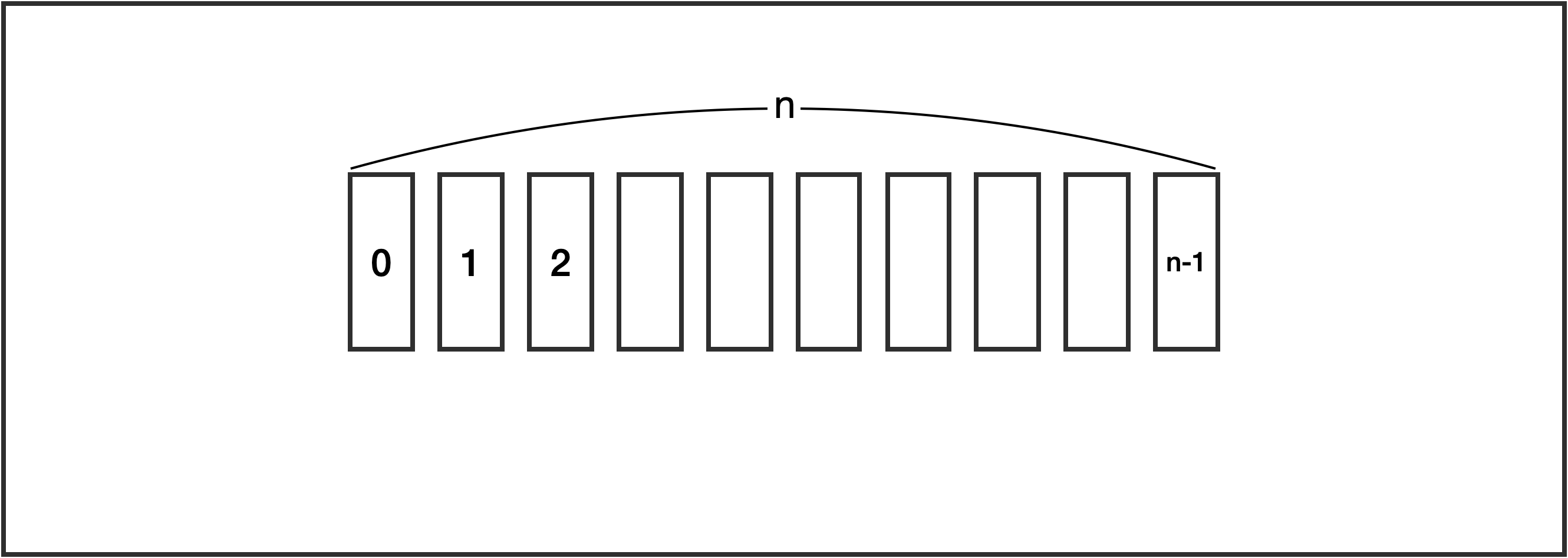
JDK 에 'ArrayList', 'Vector' 클래스가 구현되어 있습니다.
b) Linked List
배열의 단점을 보완한 자료구조로, 데이터와 링크로 구성되어있습니다.
데이터를 가진 노드(데이터)와 다음 노드의 주소를 가리킵니다(링크).
배열은 물리/논리적인 구조가 동일한데 이것은 먼저 길이를 선언하지 않고
필요할 때마다 그 자료에 대한 노드에 대한 메모리를 할당받고 그 전 노드가 새로 생긴 노드를 가리킵니다.
요소에 대한 변경은 링크의 변경을 통해 이루어져 배열에 비해 비용이 적습니다.
반면 인덱스 연산이 되지 않아 어떠한 요소에 접근하려면 먼저 가장 첫번째 요소부터 찾아야합니다.
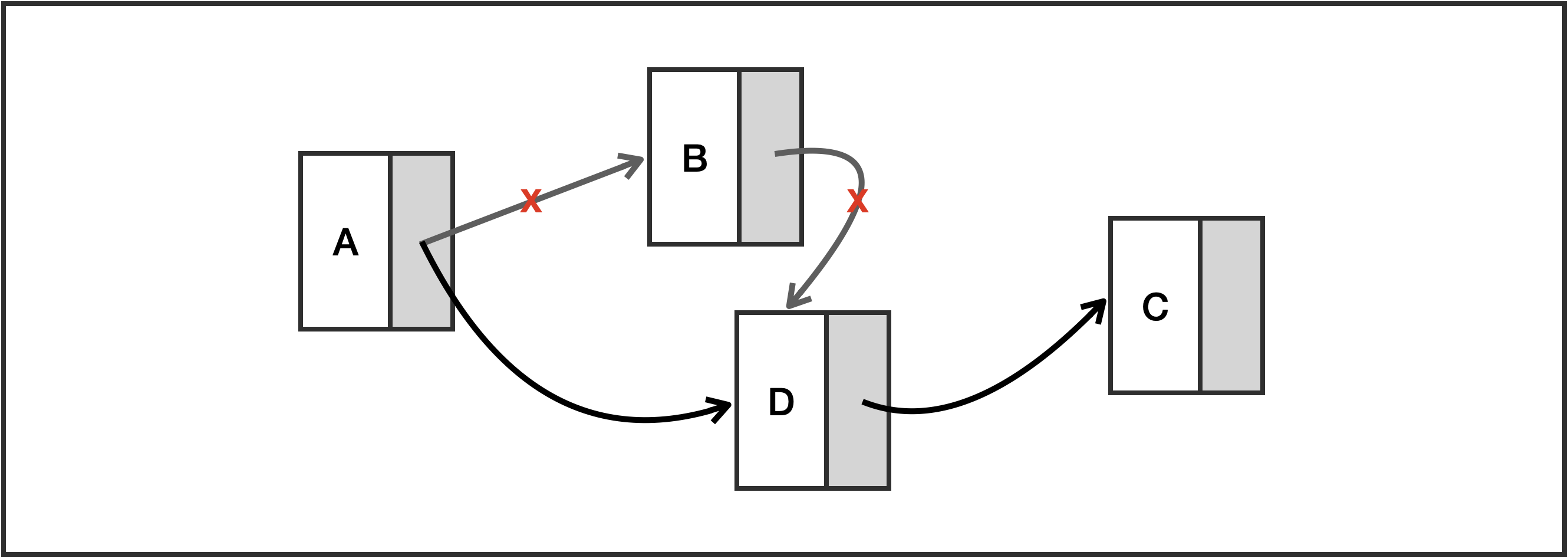
JDK 에 'LinkedList' 클래스가 구현되어 있습니다.
c) Stack, Queue
'Stack'과 'Queue'는 배열이나 링크드리스트 무엇으로든 구현이 가능하며 선형 자료구조 입니다.
배열과 다르게 항상 데이터의 추가와 삭제가 맨 앞 또는 맨 뒤에서 이루어 집니다.
Stack
후입선출 Last In First Out(LIFO), 가장 위의 데이터를 top이라고 합니다.
마지막에 들어온 데이터가 가장 먼저 나갑니다. 들어온 방향의 반대 방향으로 나간다고 생각하면 되고
예를 들면 프링글스 과자를 위에서부터 빼먹는 걸 생각하면 될 것 같습니다.
데이터를 넣고 빼는 것을 push(), pop()이라고 합니다.
스택의 가장 위에 있는 요소를 반환하는 것을 Peek 이라 하는데
pop()과 달리 스택에서 제거하지는 않습니다.
Queue
선입선출 First In First Out(FIFO), 가장 앞 쪽을 front 가장 뒤 쪽을 rear이라고 하고
먼저 들어온 데이터가 가장 먼저 나갑니다. 들어온 방향대로 그대로 나간다고 생각하면 됩니다.
데이터를 넣고 빼는 것을 enqueue(), dequeue()라고 합니다.
배열 클래스인 'ArrayList'를 이용해 'Queue'를 구현할 수 있습니다.
add() 메서드를 사용해 맨 뒤로 데이터를 쌓고
remove(size(0)) 메서드를 사용해 가장 앞의 데이터를 삭제하면서 return을 통해 데이터를 반환 받을 수 있습니다.
JDK 의 'ArrayList', 'Vector', 'LinkedList'를 이용해 구현이 가능합니다.
d) Tree
Binary Search Tree(BST)
자료를 검색하는 방법으로 이진검색 이 있습니다.
BST 는 부모 노드가 가진 자식 노드(left, right)가 최대 2개인 것을 말하며
유일한 키 값을 가져 중복을 허용하지 않습니다.
그리고 루트 노드의 키 값 기준 left 노드는 부모 노드보다 작은 값, right 노드는 큰 값이어야 합니다.
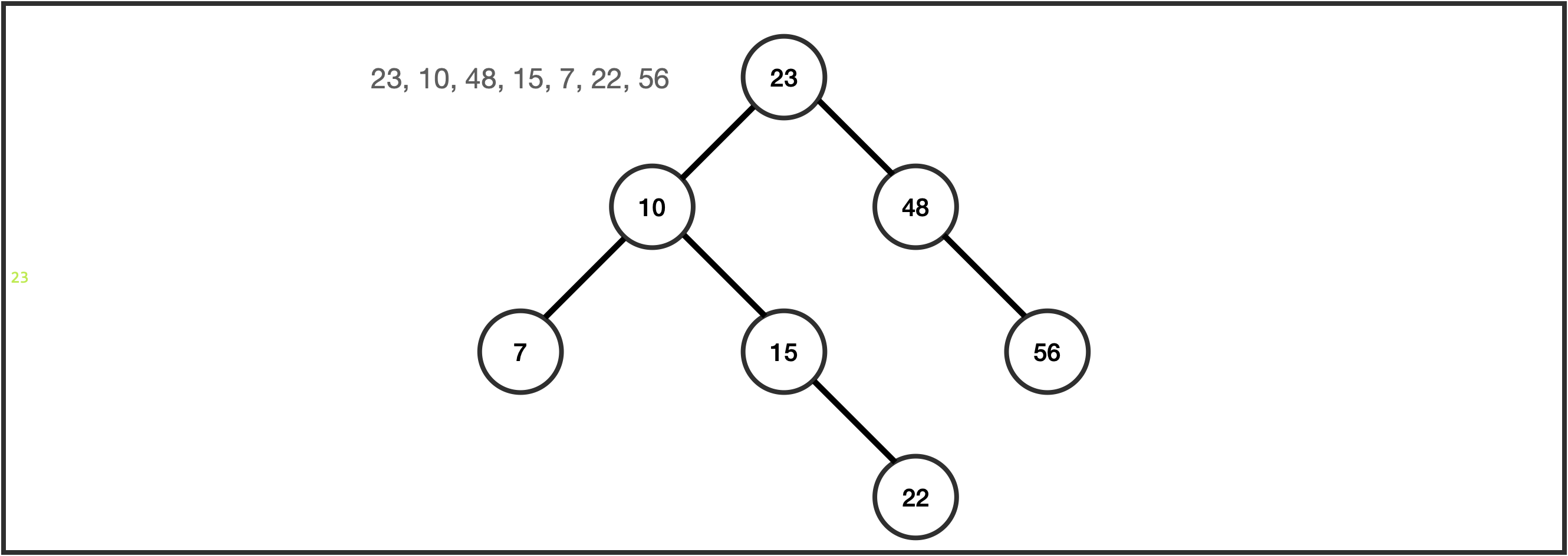
이런 이진검색은 어떠한 값을 찾을 때 좀 더 효율적으로 검색이 가능합니다.
예를 들어 위 그림에서 '22'를 찾는다면 가장 위 노드인 '23'보다 작은 왼쪽 노드들만 보면 됩니다.
그다음 '22'가 '10'보다 크므로 다시 오른쪽 노드들만 보면 됩니다.
JDK 에 'Treeset', 'TreeMap' 이 있습니다.
밸런스를 맞추기 위해 고안된 AVL, Red-Black 트리가 있습니다.
정렬
in-order traverse , left 노드가 있으면 없을 때까지 내려가고 없으면 본 노드를 선택,
그리고 right 노드가 없으면 위의 노드로 올라갔다가 right 노드가 있으면 내려가서
다시 위의 행위를 반복해 정렬합니다.
위 트리 그림을 예로 들면 left에 7이 마지막이므로 먼저 '7'을 둡니다.
7에서 right 노드가 없으므로 10으로 올라가 '10'을 선택하고 right 15는 left 없으므로 '15' 선택,
right '22' 선택 지금까지 순서대로 7, 10, 15, 22로 정렬 되었습니다.
이런 식으로 오름차순 정렬이 이루어 집니다.
만약 트리가 반전됐다면 내림차순 정렬이 될 것입니다.
pre-order traverse
post-order traverse
e) Hashing
해싱 은 '산술 연산'을 이용한 검색 방식입니다.
키 값에 Hashing Function을 통한 연산을 이용해 검색 자료의 주소를 찾습니다.
평균 시간 복잡도는 자료가 N개 일 때, 0(1) 입니다.
JDK 에 'HashMap', 'HashSet'이 있습니다.
1. Collection Framework
컬렉션 프레임워크 는 프로그램 구현에 필요한 자료구조를 구현해놓은 라이브러리이며
개발에 소요되는 시간을 절약하면서 최적화 된 알고리즘을 사용할 수 있습니다.
'컬렉션 프레임워크'는 'java.util' 패키지에 구현되어 있는데,
여러 인터페이스와 구현 클래스 사용 방법을 이해 해야 합니다.
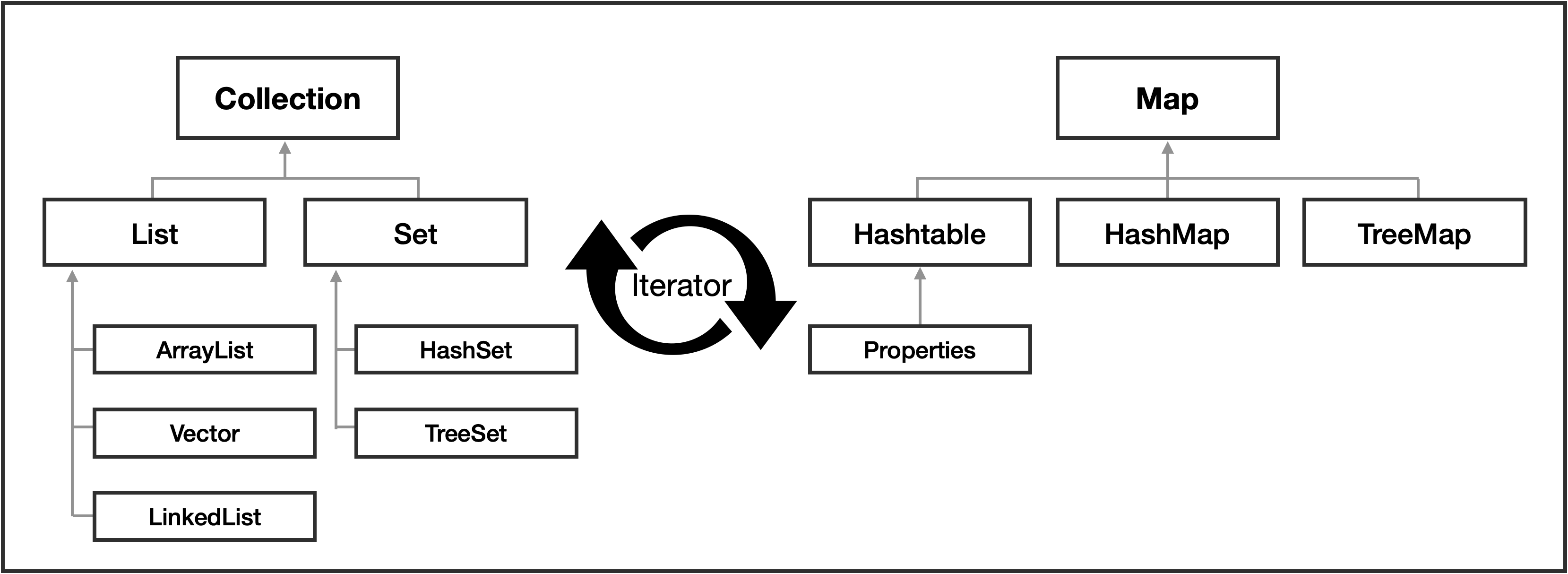
'Collection'은 단일 객체를 관리하고 'Map'은 마치 파이썬의 딕셔너리 자료형처럼
키와 밸류 등 쌍으로 된 객체를 관리합니다. 이때 키 값은 중복될 수 없습니다.
Iterator 는 인터페이스이며 모든 요소를 순회할 수 있습니다.
ㄱ) Collection 인터페이스
하나의 객체를 관리하기 위한 메서드가 선언된(구현 X) 인터페이스입니다.
하위에 'List', 'Set' 인터페이스가 있습니다.
'List' 인터페이스를 구현한 클래스는 순서가 있고 중복이 허용됩니다.
'Set' 인터페이스를 구현한 클래스는 마치 집합처럼 순서가 없고 중복을 허용하지 않습니다.
Collection 인터페이스에 선언된 주요 메서드
| 메서드 | 설명 |
|---|---|
| boolean add(E e) | Collection에 객체를 추가합니다. |
| void clear() | Collection의 모든 객체를 제거합니다. |
| Iterator<E> iterator | Collection을 순환할 반복자(Iterator)를 반환합니다. |
| boolean remove(Object o) | Collection에 매개 변수에 해당하는 인스턴스가 존재하면 제거합니다. |
| int size() | Collection에 있는 요소의 개수를 반환합니다. |
강의에서 'Help' 창을
F1키로 찾는데, 저는 웬일인지 나오지 않습니다.
Window - Show View - Other 에서 'help' 검색 하면 됩니다.
그러면 찾는 클래스나 메서드 등의 자바 공식문서(오라클)를 보여줍니다.
또는 (MacOS 기준) command(⌘) 키를 누른 채로 클래스를 클릭하면
해당 클래스 파일을 보여줍니다.

a) List 인터페이스
'Collection'의 하위 인터페이스입니다.
객체를 순서에 따라 저장하고 관리하는 데에 필요한 메서드가 선언되어 있습니다.
이는 배열의 기능을 구현하기 위한 인터페이스이고 이를 구현한 클래스로는
'ArrayList', 'Vector', 'LinkedList' 등이 있습니다.
ArrayList, Vector 클래스
객체 배열을 구현한 클래스입니다. 둘 중 일반적으로 'ArrayList'를 더 사용합니다.
'Vector'는 자바 2부터 제공된 클래스이며 멀티 쓰레드 상태에서
리소스에 대한 동기화가 필요한 경우 사용합니다.
'ArrayList'에 동기화 기능이 추가되어야 하는 경우
Collections.synchronizedList(new ArrayList<String>());동기화(Synchronization) : 두 개의 쓰레드가 동시에 하나의 리소스에 접근 할 때
순서를 맞춰 데이터에 오류가 발생하지 않도록 합니다.
LinkedList 클래스
논리적으로 순차적인 자료구조가 구현된 클래스입니다.
다음 요소에 대한 참조값을 가지고 있고 요소의 추가, 삭제에 드는 비용이 배열보다 적습니다.
위에 '링크드리스트'에 대한 그림을 참조하면 되겠습니다.
2. ArrayList
지금까지 모든 실습코드를 작성해서 게시했는데, 굳이 그럴 필요 있나 싶어서
제가 무언가 깨달았거나 궁금한 게 있거나 뭔가 개념상 정리가 필요한 부분인 경우에만
소스코드를 올려야겠다고 생각하게 되었습니다. (갑자기?)
//
package collection.arraylist;
import java.util.ArrayList;
import collection.Member;
public class MemberArrayList {
... 생략
public boolean removeMember(int memberID) {
for (int i=0; i<arrayList.size(); i++) {
Member member = arrayList.get(i);
int tempID = member.getMemberID();
if (memberID == tempID) {
arrayList.remove(i);
return true;
}
}
System.out.println(memberID + "가 존재하지 않습니다.");
return false;
}
... 생략배열 클래스에서 요소를 추가하고 삭제하는 메서드를 추가했습니다.
그 중 요소를 삭제하는 메서드 'removeMember()'에서 좀 더 편한 방법이 없을까싶어
머릿속을 정리할 겸 작성합니다.
여기에서는 삭제하고자하는 'memberID'를, 배열의 요소들이 가진 'memberID'들을
하나하나 비교해 일치하면 삭제하는 코드로 작성했습니다.
그런데 remove() 메서드에 애초에 인덱스 번호를 넣으면 찾아주는데,
memberID만으로 인덱스 번호를 찾을만한 메서드는 없는 걸까요 ?
파이썬 함수 index()를 예로 들면
먼저 'MemberArrayList' 배열의 순서와 같이 'memberID'만 가진 리스트를 선언하고,
remove(리스트.index(memberID)) 와 같이.. 너무 번거롭군요
아니면 웹서버에서 DB로 쿼리문을 날리는 것처럼 자바와 파이썬을 연동..
3. Stack, Queue, HashSet
ㄱ) Stack, Queue
위에서 이미 '스택', '큐' 자료구조에 대해 작성했습니다.
Stack 과 Queue 의 기능은 이미 구현된 클래스가 있지만
'ArrayList'나 'LinkedList'를 활용해 사용할 수도 있습니다.
이 강의에서는 'ArrayList'를 활용해 스택과 큐를 구현해보았습니다.
Iterator 사용하여 순회하기
'Collection'의 개체를 순회하는 인터페이스입니다.
사용하는 방법은 아래와 같이 'iterator()' 메서드를 호출하는 것입니다.
// iterator() 메서드 호출
Iterator ir = memberArrayList.iterator();선언된 메서드
| 메서드 | 설명 |
|---|---|
| boolean hashNext() | 이후 요소가 더 있는지 체크하는 메서드입니다. 요소가 있다면 true를 반환합니다. |
| E next() | 다음에 있는 요소를 반환합니다. |
순서가 없는 자료구조 등에 사용할 수 있습니다.
위의 2. ArrayList에서 작성했던 코드 중 'removeMember()' 메서드의 반복문을
for 문이 아닌 iterator를 이용해 다시 작성해보겠습니다.
// 변경 전
public boolean removeMember(int memberID) {
for (int i=0; i<arrayList.size(); i++) {
Member member = arrayList.get(i);
int tempID = member.getMemberID();
if (memberID == tempID) {
arrayList.remove(i);
return true;
}
}
System.out.println(memberID + "가 존재하지 않습니다.");
return false;
}while문으로 arrayList 안에 다음 요소가 있는 경우 계속해서 반복합니다.
변경 전과 다르게 remove() 메서드에 인덱스가 아닌 Object를 직접 받게 됩니다.
for문으로는 배열의 길이(n)만큼, 인덱스 0부터 n-1까지 순차적으로 반복했는데,
iterator를 이용하면 순서와 상관없이 요소들을 순회합니다.
// 변경 후
public boolean removeMember(int memberID) {
Iterator<Member> iterator = arrayList.iterator();
while (iterator.hasNext()) { // 다음 요소가 있으면 반복.
Member member = iterator.next();
int tempID = member.getMemberID();
if (memberID == tempID) {
arrayList.remove(member);
return true;
}
}
System.out.println(memberID + "가 존재하지 않습니다.");
return false;
}ㄴ) HashSet
먼저 아래 코드를 통해 'Member' 자료형의 인스턴스를 만들고
addMember() 메서드를 통해 '이순신', '김유신', '신사임당'을
'memberHashSet'에 넣습니다.
그리고 다시 '이순신'과 memberID가 101로 같은 '이몽룡'을 만들어
'memberHashSet'에 넣습니다.
package collection.hashset;
import collection.Member;
public class MemberHashSetTest {
public static void main(String[] args) {
MemberHashSet memberHashSet = new MemberHashSet();
Member memberLee = new Member(101, "이순신");
Member memberKim = new Member(102, "김유신");
Member memberShin = new Member(103, "신사임당");
memberHashSet.addMember(memberLee);
memberHashSet.addMember(memberKim);
memberHashSet.addMember(memberShin);
memberHashSet.showAll();
Member memberLee2 = new Member(101, "이몽룡");
memberHashSet.addMember(memberLee2);
memberHashSet.showAll();
}
}'Set'에는 중복이 허용되지 않는다고 했지만 현재 상황에서는 그대로 추가가 됩니다.
'Object' 클래스의 hashCode(), equals() 메서드를 'Member' 클래스에 오버라이딩해
hashSet에 데이터를 추가할 때 객체가 같은지 여부를 체크하고 중복을 막습니다.
package collection;
public class Member {
... 생략
@Override
public int hashCode() {
return memberID;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Member) {
Member member = (Member)obj;
if (this.memberID == member.memberID) {
return true;
} else {
return false;
}
}
return false;
}
}4. TreeSet, HashMap, TreeMap
