충남대학교 컴퓨터융합학부의 김동일 교수님의 기계학습을 수강한 후 정리한 글입니다.
Bayesian ClassificationLinear RegressionLogistic Regression- K-NN Classification
오늘은 K-NN Classification 에 대해 알아보려고 한다. 이 알고리즘은 직관적이고 오래된 알고리즘 중에 하나이다. 간단하게 설명하자면 어떠한 데이터가 들어왔을 때 데이터를 둘러싸고 있는 다른 데이터들을 보고 새로운 데이터가 무엇인지를 판별하는 알고리즘이다.
K-Nearest Neighbors Classification
위에서 얘기한 것처럼 근처의 데이터들을 가지고 새로운 데이터가 무엇인지를 판별하는 방법이다. 그렇다면 판별하는 요소는 데이터간의 거리가 될 것이다.
Distance
우선 거리를 구하는 공식을 살펴보자.

우리가 일반적으로 알고 있는 거리를 구하는 공식과는 조금 다른 형태처럼 보인다. 사실 위의 식은 가장 General 한 형태로 가정을 최소화한 것이다. 여기서 가정을 추가하면 우리가 알고 있는 두 점 사이의 거리를 구하는 공식이 된다.
1. Manhattan distance (k = 1)
k=1 이라는 가정이 추가됐다. 이를 맨해튼 거리라고 부른다.
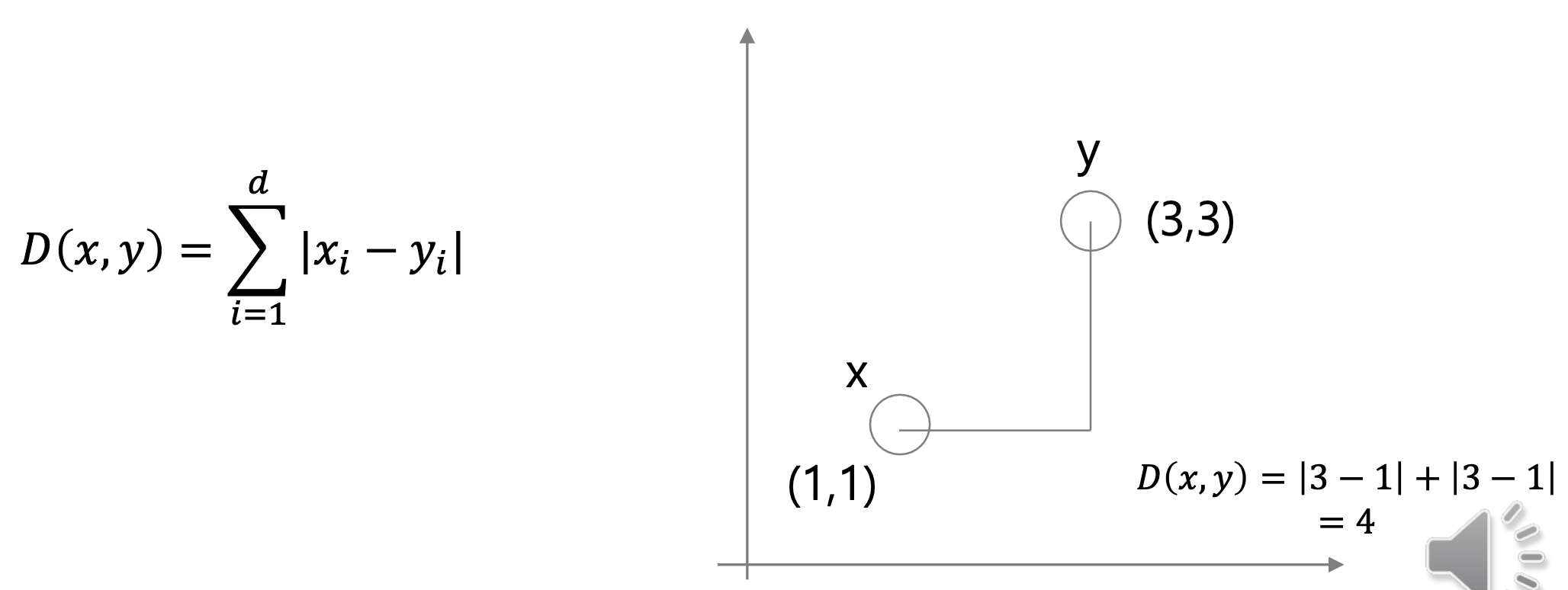
각 좌표의 차를 의미한다.
2. Euclidean distance (k = 2)
k=2 이라는 가정이 추가됐다. 이를 유클리디안 거리라고 부른다.
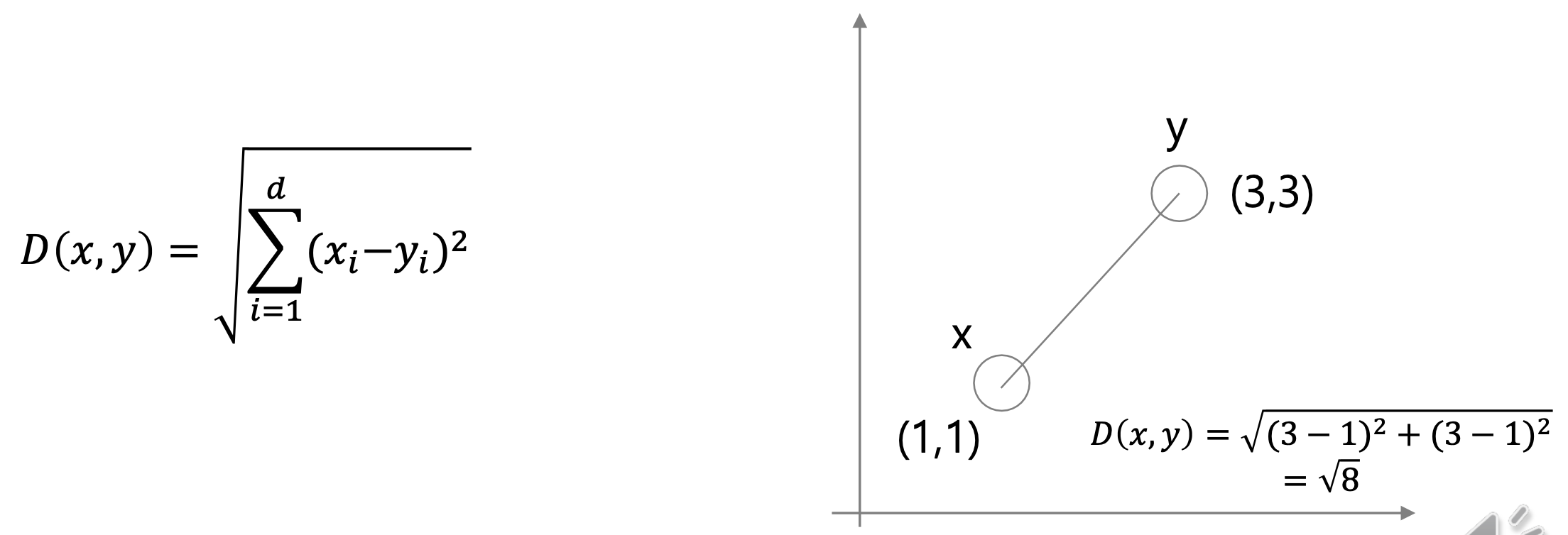
일반적으로 알고 있는 두 점 사이의 직선거리다. 두 점의 x 좌표와 y 좌표를 뺀 후에 제곱하는 형태이다.
3. Mahalanobis distance
이건 좀 특이한 형태의 distance 인데, 유클리디안 거리를 공분산으로 나눠준 것이다.
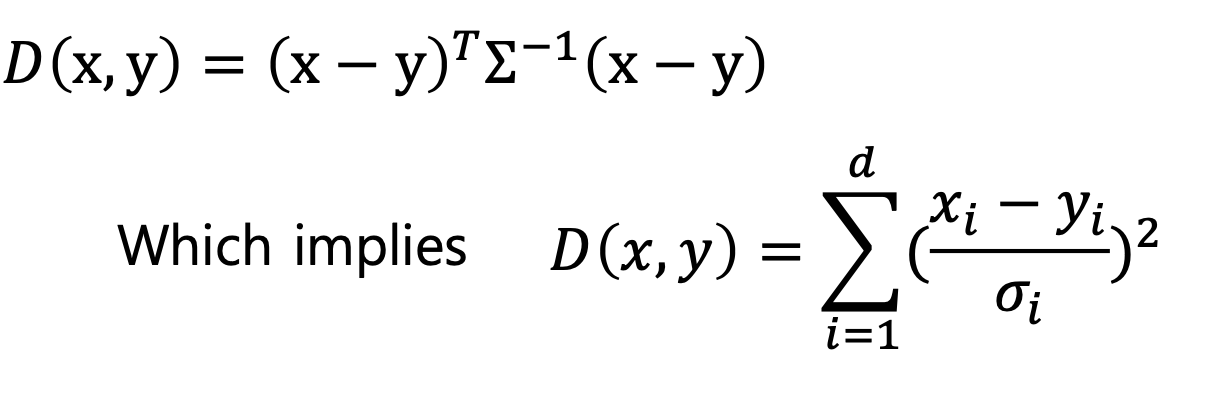
유클리디안 거리, ((x-y)^T(x-y))^1/2 를 공분산으로 나눠준 형태이다. 기존의 유클리디안 거리는 단순히 좌표 간의 거리를 의미한다면 마할라노비스 거리는 각 특징 간의 관계까지 고려해서 거리를 구하겠다는 의미이다.
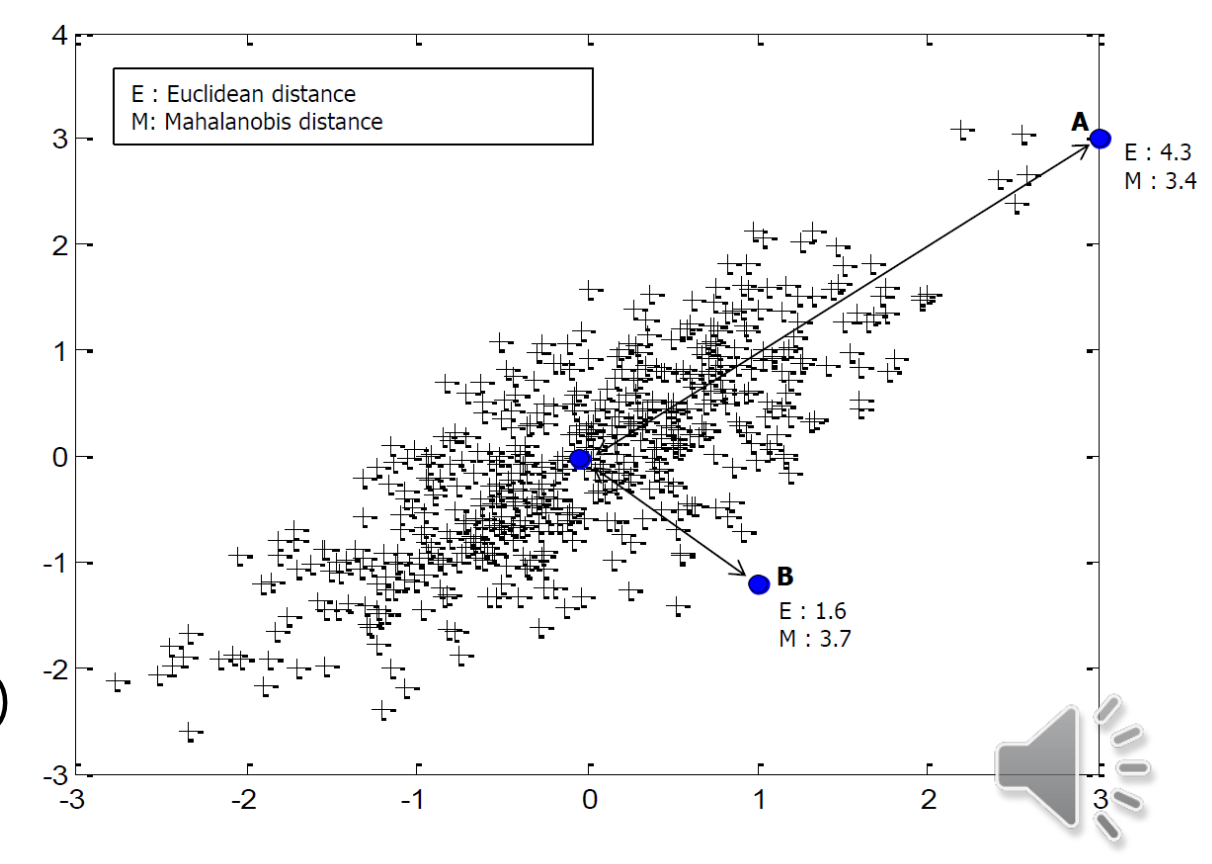
A 좌표 가 B 좌표 보다 중심의 파란색 좌표에서 직선 상의 거리는 더 멀리 떨어져있으므로 유클리디안 거리는 더 멀다. 하지만 마할라노비스 거리를 보면 더 작은 것을 볼 수 있다. 분산이 더 크기 때문이다.
적용
Categorical Feature
거리를 구하는 공식을 살펴봤고 이를 적용해보자. 하지만 문제가 있다. 모든 Input , 즉 Feature 가 Numerical 하지 않을 수도 있기 때문이다. Norminal 과 Categorical 이 여기에 해당하는데 특히 Categorical 이 문제가 된다.
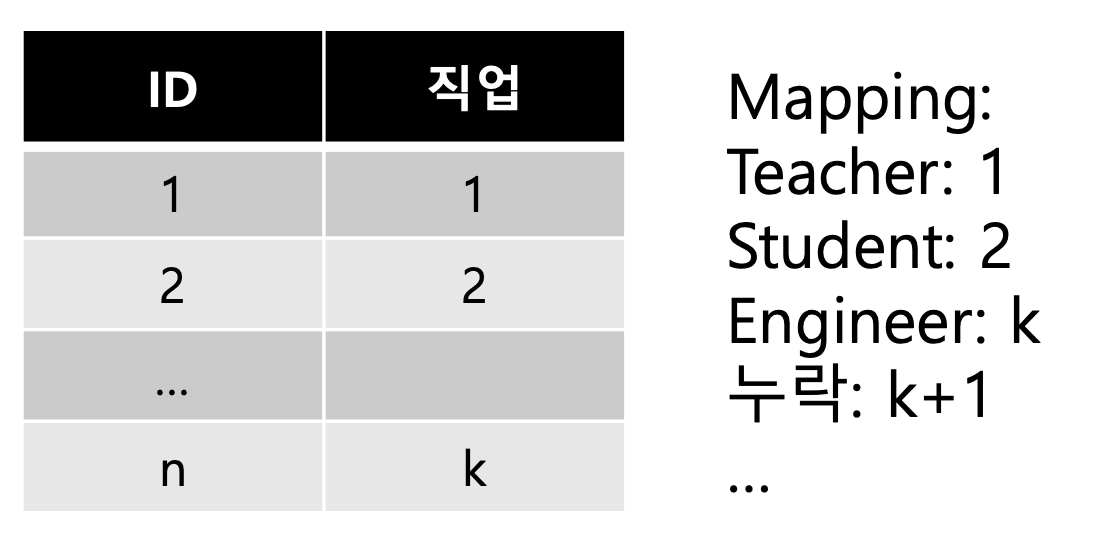
각 카테고리에 따라 숫자를 지정해줘서 이를 계산하는 방법을 생각할 수 있다. 하지만 문제가 있다. 이렇게 Mapping 을 하고 거리를 계산하면 Mapping 순서 에 따라 값이 변하는 결과를 가져온다. 이러한 문제를 방지하기 위해 각 카테고리별로 Feature 를 생성하는 One hot encoding 방식을 이용한다.
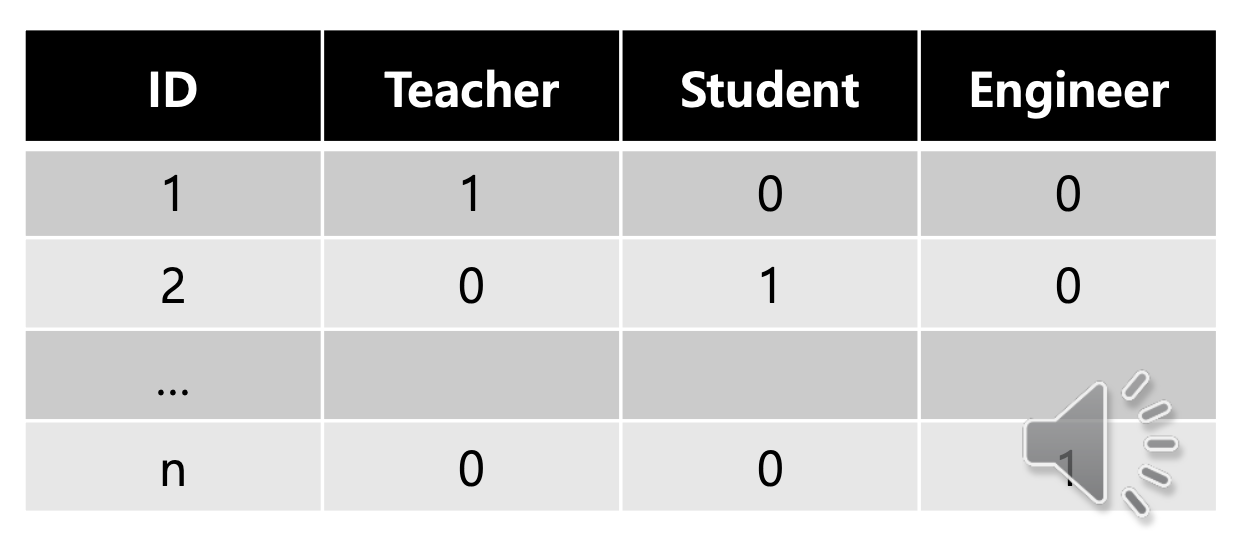
Feature 의 개수가 많아진다는 단점이 있지만 Mapping 에서 발생하는 문제를 해결할 수 있다. One hot encoding 을 사용해서 Categorical Feature 도 거리를 구할 수 있게 됐다. 그렇다면 이제 어떤 클래스에 속할지를 정할 수 있을까? 물론 계산할 수 있지만 부정확한 결과가 나올 수 있다. 이유는 Scaling 을 진행하지 않았기 때문이다.
Scaling

위 그래프의 문제가 무엇인가? 두 점 사이의 거리를 구햇는데 X 축의 단위가 너무 커서 우리가 원하는 그런 그림이 나오지 않는다는 것이다. 이를 해결하기 위해선 정규화 가 필요하다. 정규화를 통해 단위의 차이에 따라 발생하는 효과를 제거하는 것, 이것이 바로 Scaling 이다.
정규화는 Z-Normalization 과 Min-max Nomalization 가 있다.
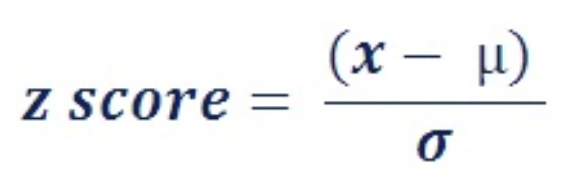
Z-Normalization 은 평균을 0, 분산을 1로 만들어주는 정규화이다.

Min-max Nomalization 는 분모에는 최대값과 최소값의 차이, 즉 값의 범위를 넣어주고 분자에는 최소값과의 차이를 넣어주는 정규화이다.
이렇게 Scaling 을 통해 Feature 간의 단위 차이에서 발생할 수 있는 문제를 제거해준다.
이제 모든 과정은 끝났다. k 를 찾으면 된다.
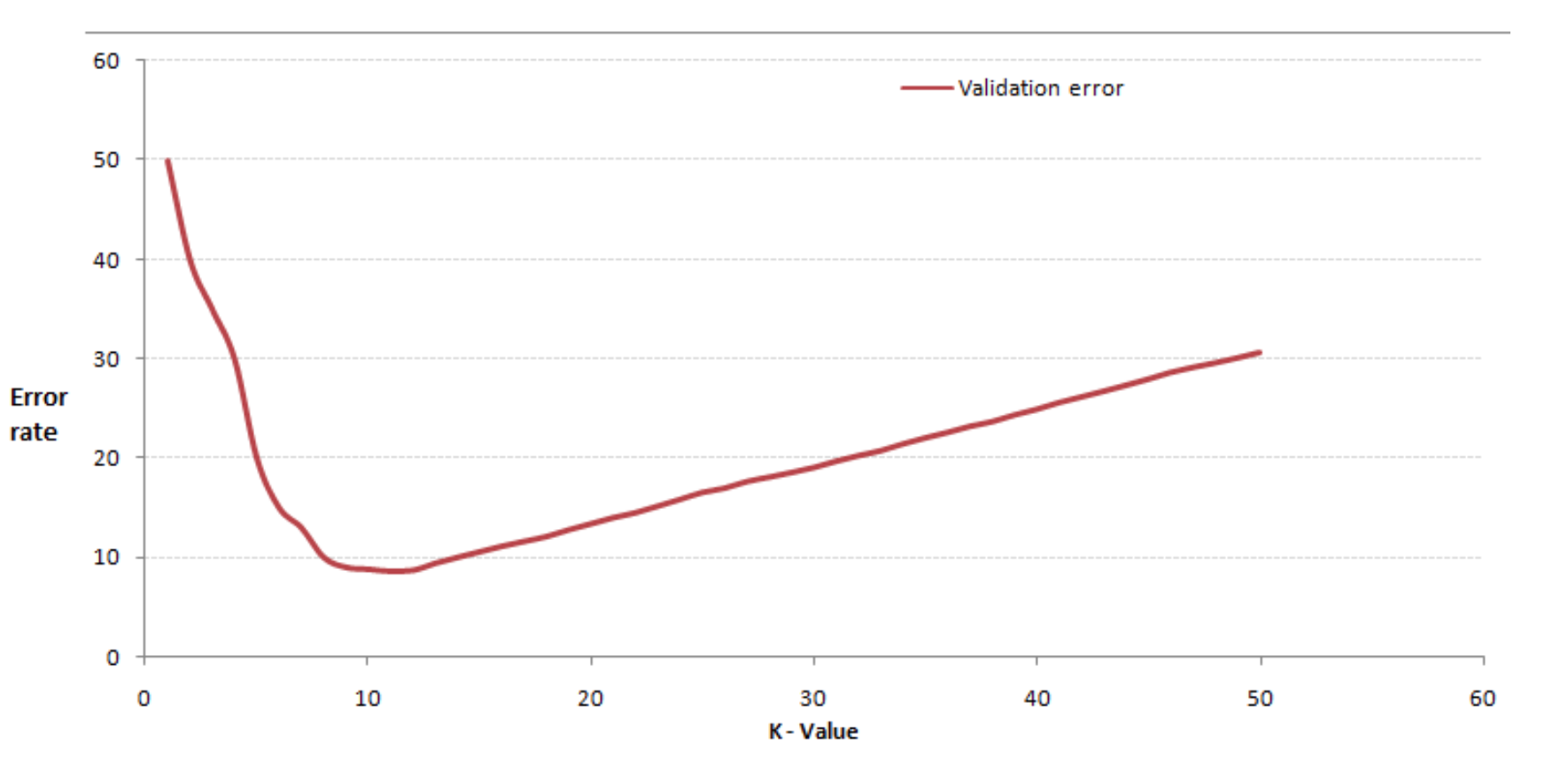
일정한 범위의 k 에 K-NN 을 진행하고 가장 낮은 Error 를 갖는 k 를 택하면 된다.
특징
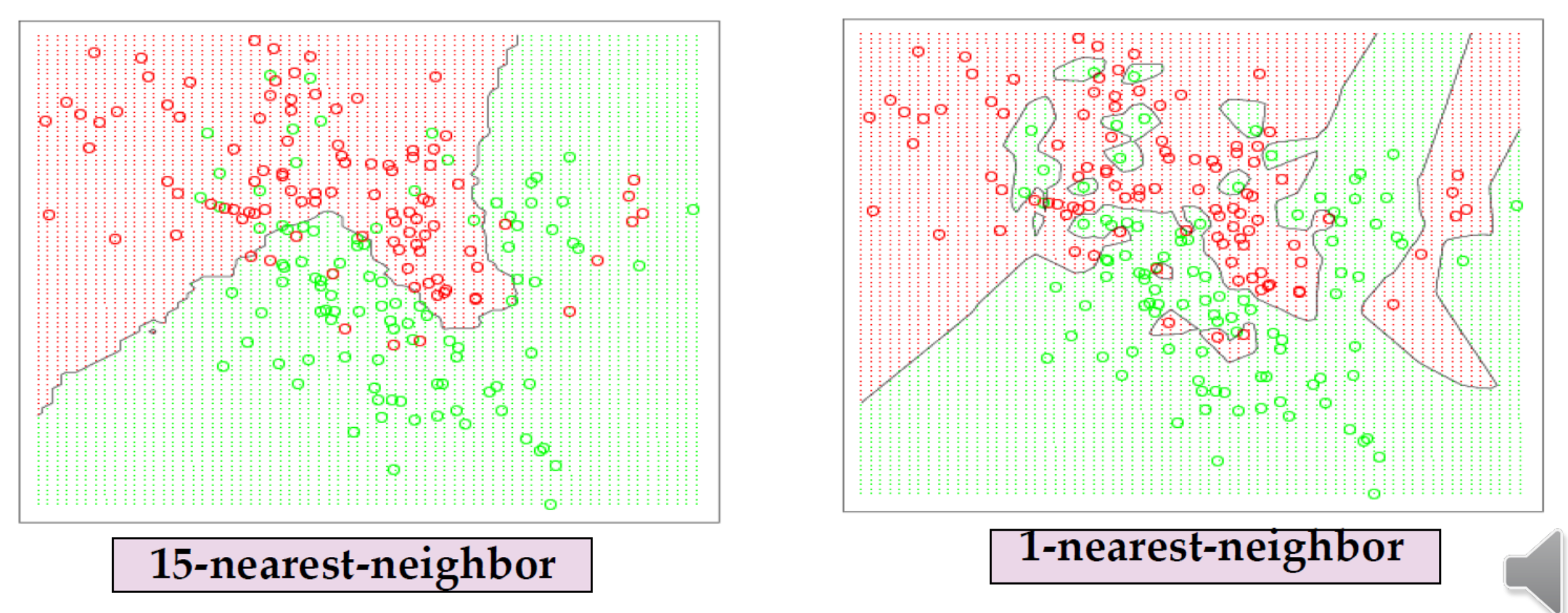
K-NN 의 경우 Hyper-parameter 인 k 에 따라 결과가 달라진다. k=1 로 설정하면 Complex model 이 되고 overfitting 이 발생할 수 있다. 이와 반대로 k 를 높게 설정하면 Smoothing 이 발생한다. Robust 하다고 말할 수 있다.
Lazy Learner
K-NN 을 Lazy Learner 부른다. 학습이 필요 없기 때문이다. 다른 모델들은 학습을 통해서 모델을 구축하는데 이 친구는 그냥 바로 실전이다. Training 과정이 없고 바로 Test 를 진행한다. 따라서 Test 과정에서 많은 시간이 소요된다는 단점이 있고, 실시간성이 필요한 곳에는 사용하지 못한다.
정리
- Classification, Regression 가능
- Lazy Learner
- 다른 모델들을 평가할 수 있는 성능의 Base line
- Maximun error = Optimal * 2 (수학적으로 계산 완료)
- 간단하면서도 Nonlinear
