1. isin
- 시리즈(Series)나 데이터프레임(DataFrame)에서 특정 값이나 값들의 집합이 포함되어 있는지를 검사하는 데 사용
- 해당 열의 각 요소가 values에 포함되어 있는지를 검사하고, 그 결과를 불리언(boolean) 시리즈로 반환
- 해당 값이 포함되어 있으면 True, 포함되어 있지 않으면 False
dataframe['column_name'].isin(values)
* dataframe: 검사할 데이터프레임
* column_name: 검사할 열(컬럼)의 이름
* values: 검사할 값들의 리스트나 시리즈2. np.arange
- 일정한 간격으로 숫자 배열을 생성
np.arange(start, stop, step)
*start: 배열의 시작
*stop: 배열의 마지막
*step: 배열의 간격(숫자 사이의 간격)3. np.log1p
- 데이터의 분포를 변경하거나 데이터의 스케일을 조정하기 위해 사용
- 분포가 한쪽으로 치우쳐져 있을 때 로그 변환을 통해 데이터를 정규분포에 가깝게 만들 수 있음
plt.hist(comp_sr)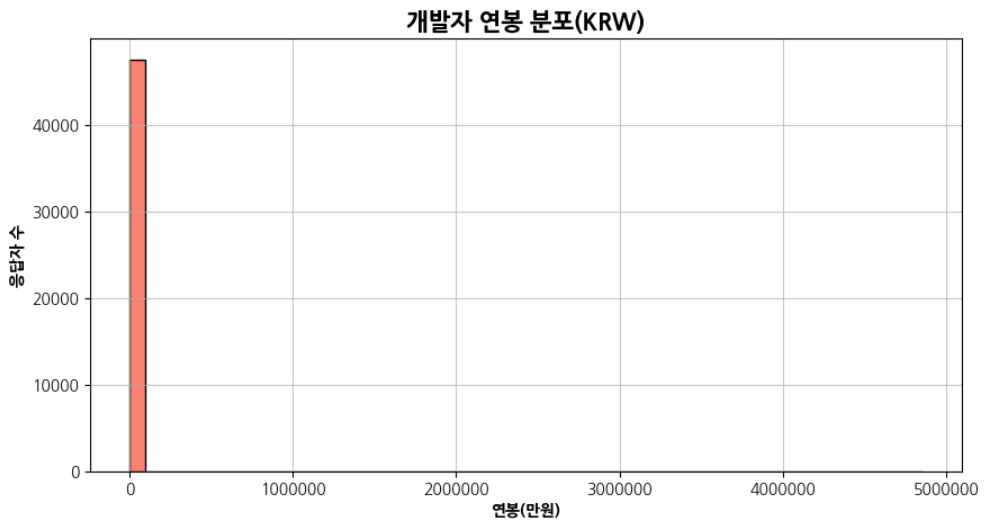
np.log1p(log_comp_sr)
▶ 로그 변환만 했을 뿐인데 정규분포에 가까워진 것을 볼 수 있음!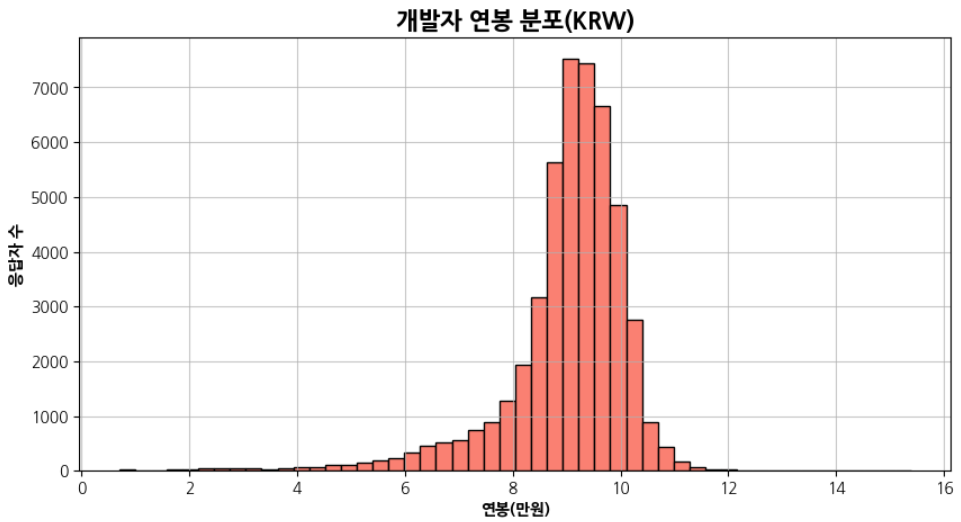
4. pd.cut
- 연속형 데이터를 구간(bin)으로 나누는 작업을 수행
pd.cut(x, bins, labels=None, right=True, include_lowest=False)
* x: 구간화할 연속형 데이터 (Series 혹은 배열).
* bins: 구간(bin)을 지정하는 방법 / 정수, 시퀀스 혹은 범위로 구성된 값을 받을 수 있음
* labels: 선택적인 매개변수로, 구간에 대응하는 라벨을 지정
* right: 구간의 오른쪽 경계를 포함할지 여부를 지정
→ False로 설정하면 왼쪽 경계를 포함 / 기본값은 True
* include_lowest: 첫 번째 구간의 왼쪽 경계를 포함할지 여부를 지정
→ right가 False일 때만 사용 가능하며, 기본값은 False
성장하는 주니어 데이터 분석가입니다!