이론 📝
1. URL 📌
DNS : 도메인 > IP
Protocol : 클라이언트와 서버 사이의 인터넷 통신 규약
Port : IP주소를 알면 서버 컴퓨터까진 도착, 서비스하는 프로그램을 정확히 찾기 위함
Path : 컴퓨터는 기본적으로 파일 시스템이 있음. 어떤 디렉토리로 들어갈지 결정
fragment : 특정 위치의 화면에 이동, 패킷을 보내는데, 네트워크망안에서 보낼 수 있는 사이즈가 제한이 걸린다면 이를 잘라서 보내게 되는데, 잘려진 패킷조각
2. 데이터 요청 방식 📌
- Get: url에 데이터가 포함 (데이터 노출), 길이 제한 있음
- Post: body에 데이터가 포함
01010101 전기적 신호를 케이블을 통해 공유기를 거쳐 사설망(kt)에서 백본망(한전)으로 감 > 해저케이블을 따라 외국으로 .. (무선 인터넷은 케이블 대신 주파수를 매체로 사용)
3. Cookie, Session, Cache 📌
- 쿠기: 하드디스트에 저장되는 데이터
- 세션: 연결 정보
- 캐시: Client나 Server의 메모리에 저장하여 빠르게 데이터를 가져오는 목적의 저장소
클라이언트는 브라우저(프론트엔드) 서버는 WAS+DB(백엔드)
4. 웹 크롤링 📌
1) url 필요 (어떻게 알아내지?)
2) request (데이터 요청)
3) 받아진 데이터를 원하는 모양으로 파싱
실습 💻
-
requests 이용
받아오는 문자열에 따라 두가지 방법으로 구분
- json 문자열로 받아서 파싱하는 방법 : 주로 동적 페이지 크롤링할때 사용
- html 문자열로 받아서 파싱하는 방법 : 주로 정적 페이지 크롤링할때 사용 -
selenium 이용
브라우져를 직접 열어서 데이터를 받는 방법
1. 동적 페이지 : request - json 📌
모바일 페이지로 여는 방법 (pc가 복잡할 경우) - F12 개발자 도구
트래픽 확인
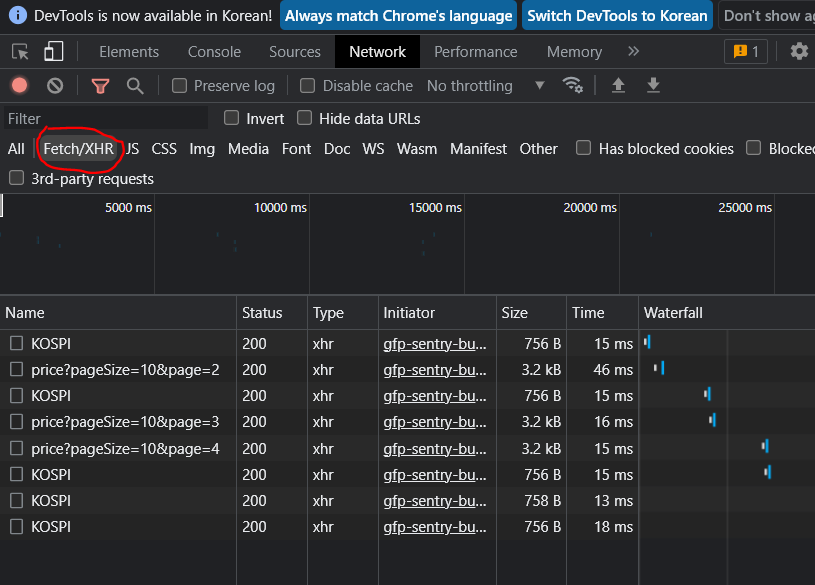
url 확인
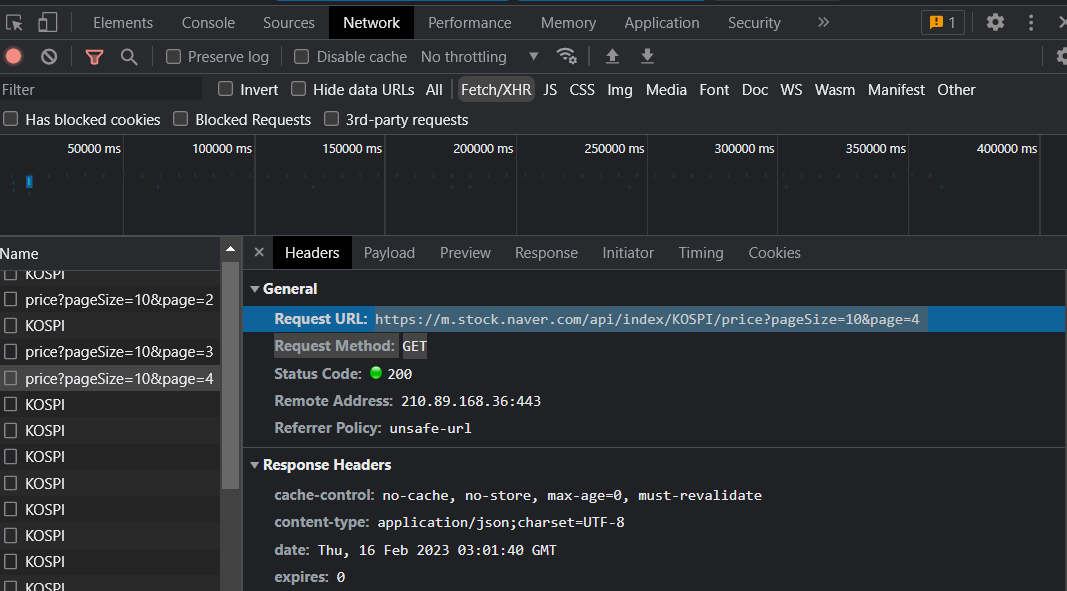
정상 확인
문자열 형태 변경 (list,dict)

데이터 프레임으로 만들기

함수화
def stock_price(code, page, page_size):
''' 이 함수는 주식 가격을 네이버에서 크롤링하는 함수입니다.
params:
code: str : KOSPI, KOSDAQ
page : int
page_size : int
return:
type : DataFrame
'''
# 1. URL
url = f'https://m.stock.naver.com/api/index/{code}/price?pageSize={page_size}&page={page}'
# 2. reuest(URL) > reponse: json(Str)
response = requests.get(url)
# 3. json(str) > list,dict > DataFrame
data = response.json()
return pd.DataFrame(data)[['localTradedAt','closePrice']]📎 얕은 복사, 깊은 복사

파이썬과 판다스의 깊은 복사가 다른가?
파이썬 copy() 메소드는 리스트가 오브젝트를 포함할 경우 그 오브젝트들은 얕은복사가 된다. deepcopy()는 무조건 깊은 복사
판다스 df.copy(deep=True)가 있다.
2. 서버에서 어뷰징을 막은 경우 해결 방법 📌
이런 경우....
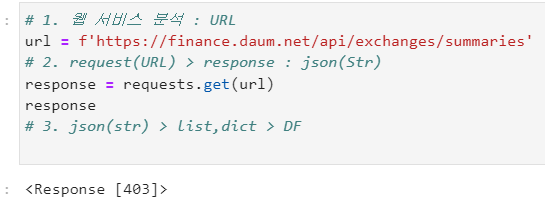
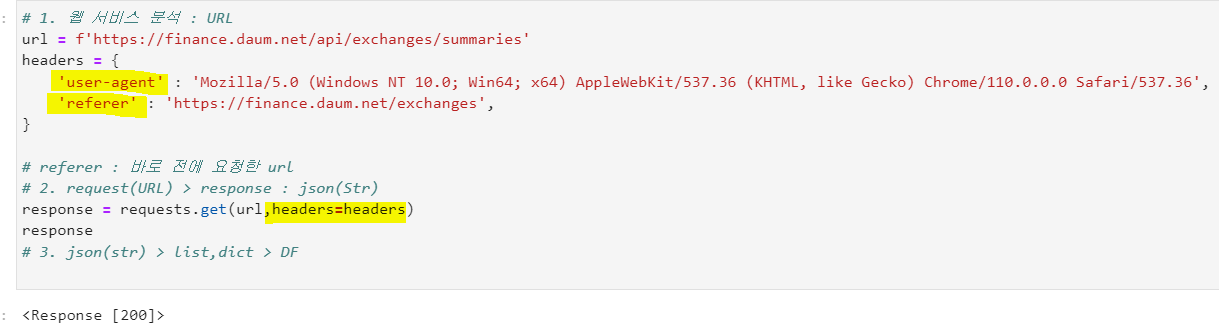
유저 에이전트 (+레퍼러)를 추가해서 요청한다!
💡 크롤링 정책
/robots.txt를 url 뒤에 붙여서 확인해봄
웹 페이지의 크롤링 정책을 설명한 페이지임과도한 크롤링으로 서비스에 영향을 주었을 경우 업무방해 혐의
법적문제: 지적재산권, 서비스 과부화, 데이터 사용 표준
API: 업체에서 데이터를 가져갈 수 있도록 하는 서비스
3. API 📌
클라이언트의 app 등록 > 서버의 key 값 전달 > URL 확인 (서비스의 document에 있음) > req(key 포함) - resp 함

위 가이드에 따라 밑처럼 준비 + get인지 post인지 가이드 잘 보기

POST 형식이라서 .post
json.dumps() < 한글이라 인코딩을 해서 데이터 요청

결과

함수화
def translate(txt, source='ko', target='en'):
Client_ID, Client_Secret = '니 ID', '니 Key'
url = 'https://openapi.naver.com/v1/papago/n2mt'
headers = { 'Content-Type': 'application/json',
'X-Naver-Client-Id': Client_ID,
'X-Naver-Client-Secret': Client_Secret, }
params = {'source': source, 'target': target, 'text': txt}
response = requests.post(url, json.dumps(params), headers=headers)
return response.json()['message']['result']['translatedText']💡 %whos : 현재 선언 변수 목록

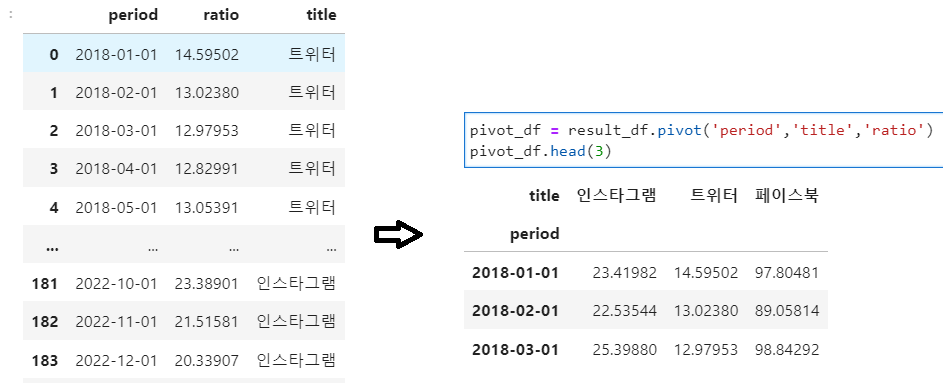
💡 df.pivot()
plot 선명하게 하는 매직 커맨드
%config InlineBackend.figure_formats = {'png', 'retina'}
