이론 📝
-
동적 페이지: URL 변화 없이 페이지의 데이터 수정 : json(str) > reponse.json() > DataFrame
-
정적 페이지: URL 변화 있이 페이지의 데이터 수정: html(str) > BeautifulSoup > css selector > DataFrame
-
셀레니움: 웹 브라우저를 파이썬 코드로 컨트롤해서 데이터 수집
- 웹 크롤링 절차
-1. 웹 서비스 분석 (개발자 도구,API 문서) : URL 찾기
-2. request(URL) > response(data) : data(json(str),html(str))
-3. 파싱 (response.json(), BeautifulSoup(css-selector))
실습 💻
1. 복잡한 웹 페이지 크롤링 (json) 📌
직방 웹페이지 크롤링
- search로 시작하는 URL 따서 위도,경도 구하기
address = '부원동'
url = f'https://apis.zigbang.com/v2/search?leaseYn=N&q={address}&serviceType=원룸'
response = requests.get(url)
data = response.json()['items'][0]
lat,lng = data['lat'],data['lng']- 위도, 경도로 geohash 알아내기
import geohash2
# precision : 숫자 클수록 영역이 작아짐
geohash = geohash2.encode(lat,lng,precision=5)
geohash- geohash로 매물 아이디 가져오기 (item으로 시작하는 URL)
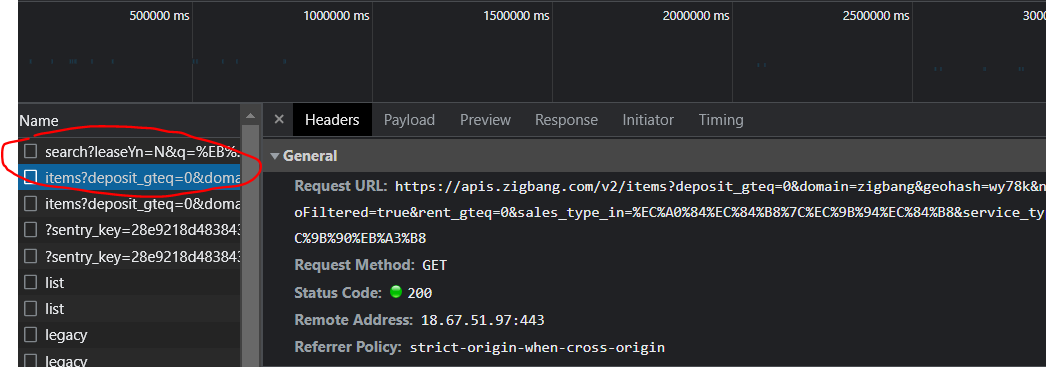
url = f'https://apis.zigbang.com/v2/items?deposit_gteq=0&domain=zigbang&geohash={geohash}&needHasNoFiltered=true&\
rent_gteq=0&sales_type_in=전세|월세&service_type_eq=원룸'
response = requests.get(url)
data = response.json()['items']
ids = [item['item_id'] for item in data]- 매물 아이디로 매물 정보 가져오기
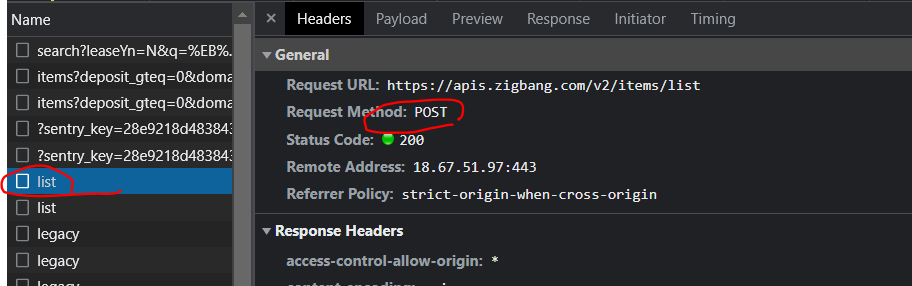
post 방식인거 확인, url 확인
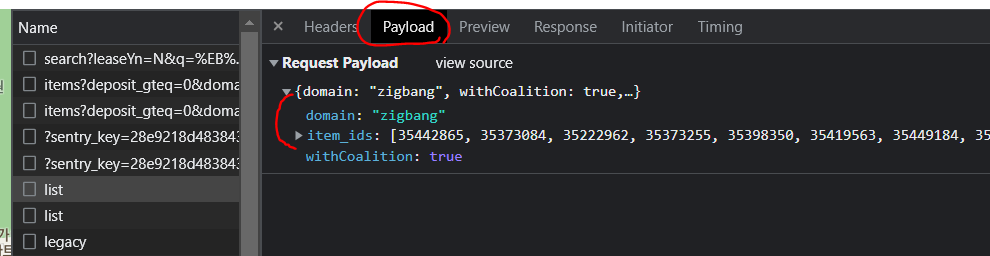
payload에서 params 항목 알아보기
url = 'https://apis.zigbang.com/v2/items/list'
params = {
'domain': 'zigbang',
'withCoalition':'true',
'item_ids': ids, #위에서 만든거!
}
response = requests.post(url,params)
data = response.json()['items']
df = pd.DataFrame(data)2. html 📌
[html 구성 요소]
- Document : 한페이지를 나타내는 단위
- Element : 하나의 레이아웃을 나타내는 단위 : 시작태그, 끝태그, 텍스트로 구성
- Tag : 엘리먼트의 종류를 정의 : 시작태그(속성값), 끝태그
- Attribute : 시작태그에서 태그의 특정 기능을 하는 값
- id : 웹 페이지에서 유일한 값
- class : 동일한 여러개의 값 사용 가능 : element를 그룹핑 할때 사용
- attr : id와 class를 제외한 나머지 속성들s
- Text : 시작태그와 끝태그 사이에 있는 문자열
- 엘리먼트는 서로 계층적 구조를 가질수 있습니다.
- 엘리먼트는 선택하는게 css-selector
[웹 페이지 구성 요소]
레이아웃 및 문자열 구성 : html
이벤트 발생 시 대처 : 자바스크립트
화면 스타일 구성 : css
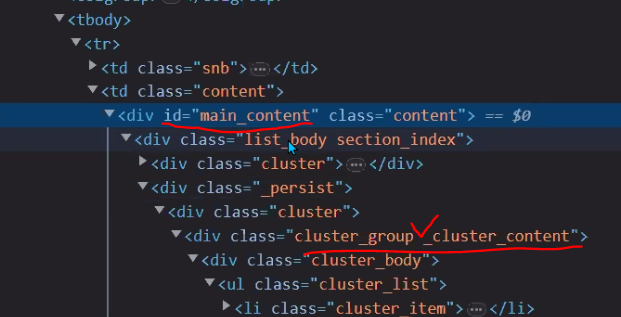
기본적으로 id와 class를 이용해서 요소를 선택

엘리먼트 안에 엘리멘트가 들어가서 총 엘리먼트가 3개인 모습
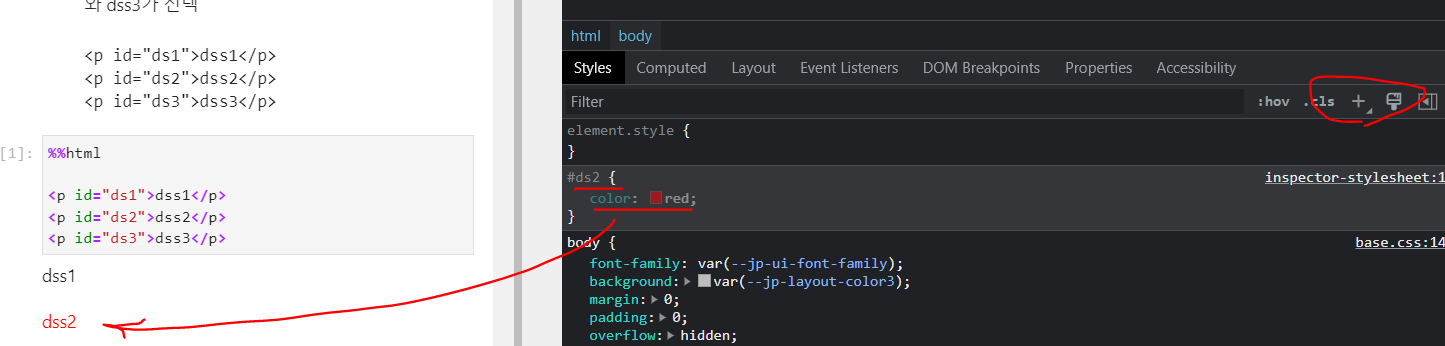
#아이디 값을 이용해서 조정 (css-selector 작성)
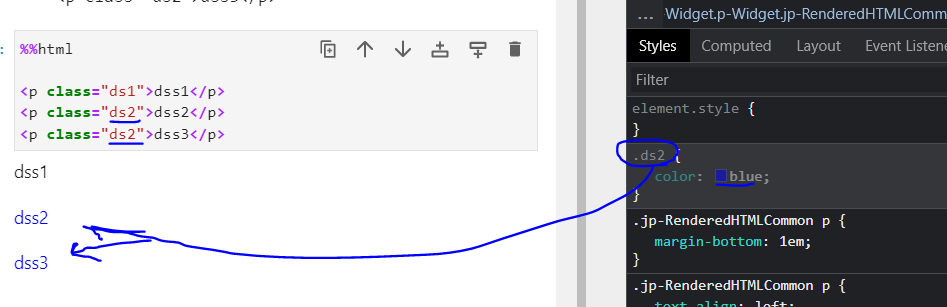
.클래스 값을 이용해서 조정 (css-selector 작성)

특정 엘리먼트 제외

단계 상관없이 밑에 있는 거 다 됨 (바로 밑만 하려면 .contains > h1)
css selctor
tag(div) , id(#div), class(.div), attr([name='div'])
여러개의 엘리먼트 선택: .div1, .div2
특정 엘리먼트 제외: .div:not(.div1)
n번째 엘리먼트 선택: .div nth-child(n)
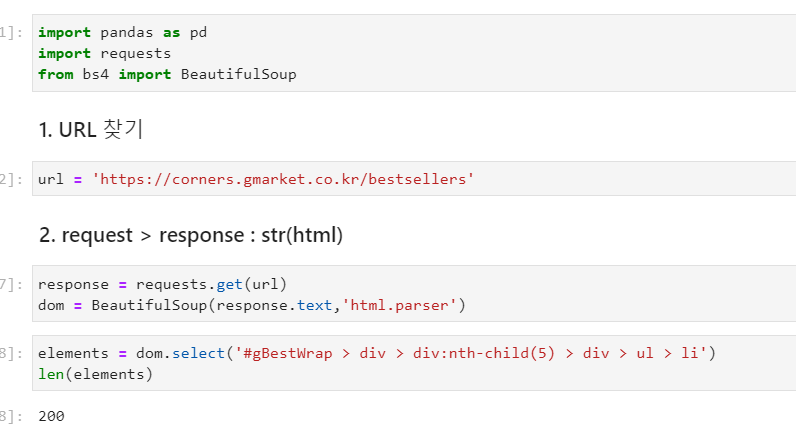
3. 정적 페이지 크롤링 (html) 📌
1) 웹 페이지 분석 : URL
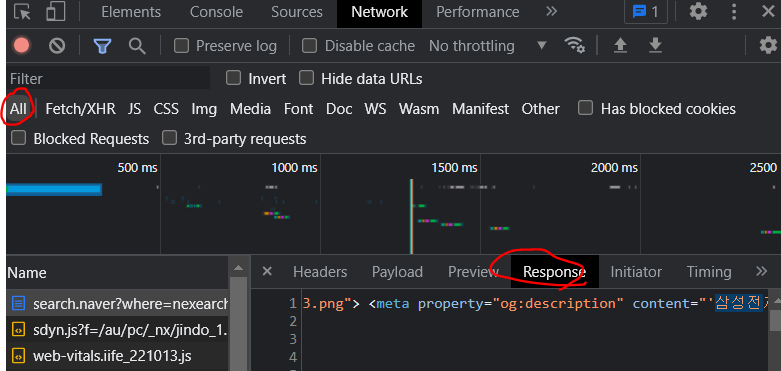
여기에 우리가 찾으려는 정보가 있는지 ctrl+F로 미리 확인
있으면 URL 사용
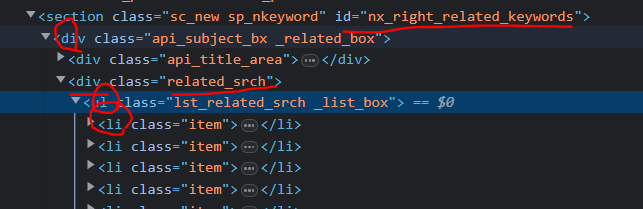
2) 엘리먼트 확인
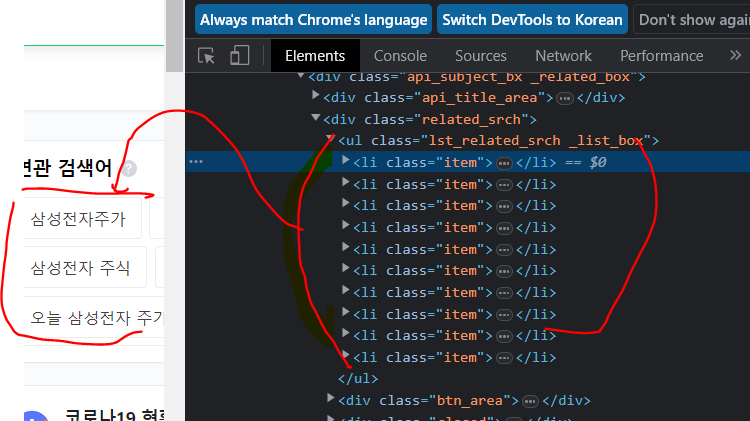
우클릭 > copy > copy selector
100%는 아니고 적당한 틀을 만들어준다.
#nx_right_related_keywords > div > div.related_srch > ul > li
3) 코드
query = '삼성전자'
url = f'https://search.naver.com/search.naver?query={query}'
respone = requests.get(url)
dom = BeautifulSoup(respone.text,'html.parser')
elements = dom.select('#nx_right_related_keywords > div > div.related_srch > ul > li')
keywords = [element.select_one('.tit').text for element in elements]
df = pd.DataFrame({'keyword':keywords})
df['query'] = query4. 어려운 정적 페이지 크롤링 (html) 📌
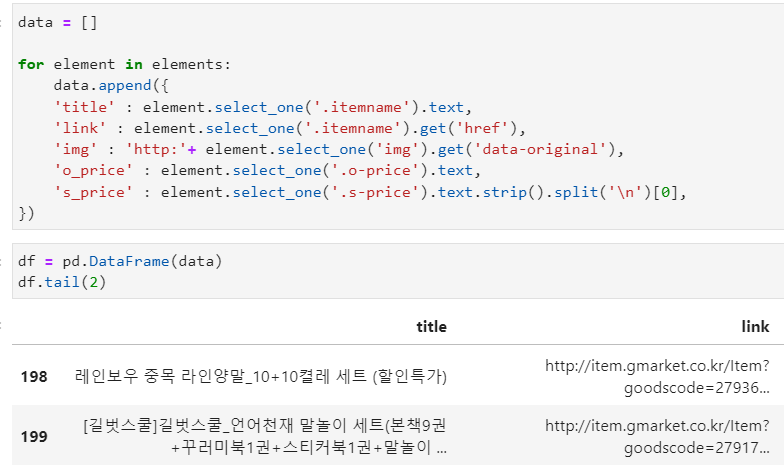
가져올 데이터가 여러 종류라서 dict 형태로 만든다.
elements[0]해서 확인

data = {
'title' : element.select_one('.itemname').text,
'link' : element.select_one('.itemname').get('href'),
'img' : 'http:'+ element.select_one('img').get('data-original'),
'o_price' : element.select_one('.o-price').text,
's_price' : element.select_one('.s-price').text.strip().split('\n')[0],
}
데이터 프레임으로 만들기
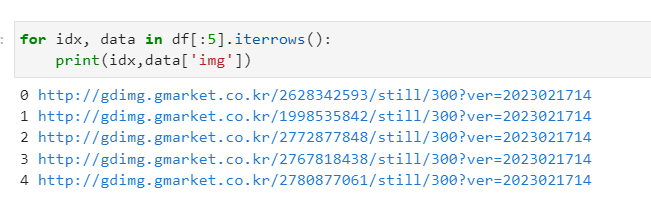
📎 .iterrows()
튜플 형태로 인덱스와 아이템을 반환
for idx, data in df[:5].iterrows(): name = '0'*(2-len(str(idx)))+str(idx) name = f'data/{idx}.png' print(idx,data['img'],name) reponse = requests.get(img_link) with open(name,'wb') as file: file.write(reponse.content) from PIL import Image as pil pil.open('./data/0.png')
5. 셀레니움 📌
-
셀레니움 설치 (conda install 등..)
-
chromedriver를 본인 버전에 맞게 설치
(정석적으로 하면 환경변수 설정이 필요하나 간편하게 그냥 같은 dir에 넣는걸로 해결) -
import하고 객체 만들기
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome() #새로운 크롬창이 뜬다.
driver.get('https://daum.net') #페이지 이동- selector 찾기
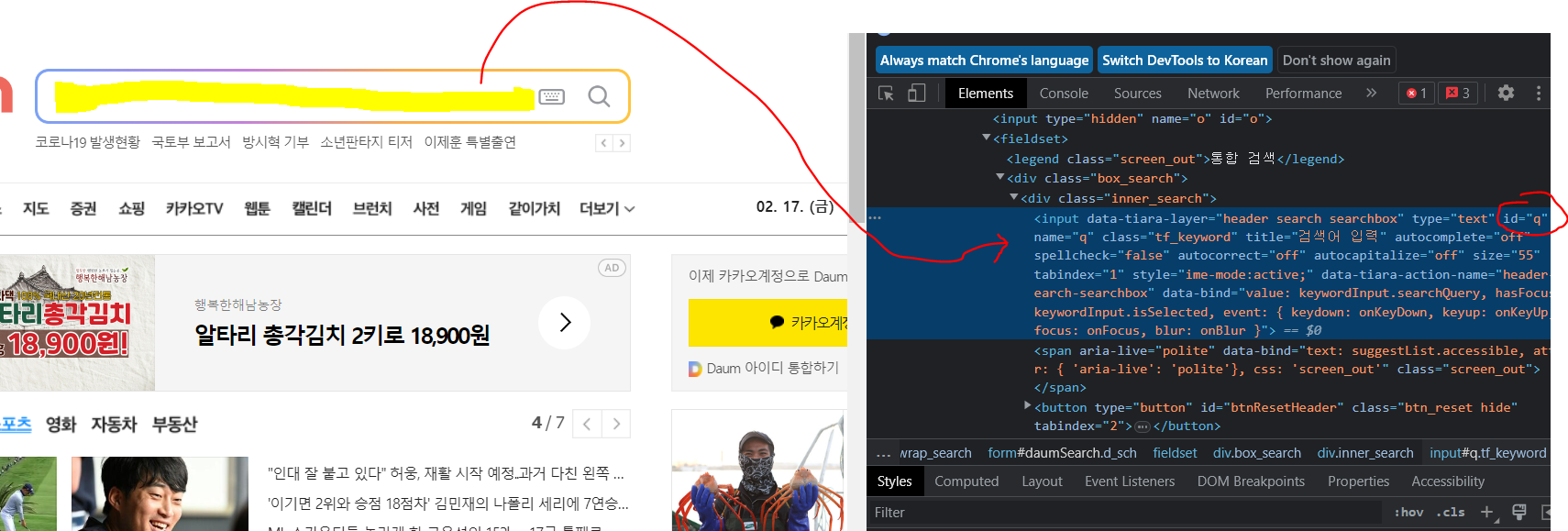
driver.find_element(By.CSS_SELECTOR,'#q').send_keys('파이썬') #검색어 입력
selector = '.inner_search > .ico_pctop.btn_search'
driver.find_element(By.CSS_SELECTOR,selector).click() #클릭 이벤트
selector = '#netizen_lists_top > .wsn'
elements = driver.find_elements(By.CSS_SELECTOR,selector) #연관검색어 클래스 찾아서 수집
keywords = [element.text for element in elements]
# driver.find_element(By.CSS_SELECTOR, selector).text
# 위는 텍스트 데이터 수집+ 자바스크립트 코드 실행, 브라우저 종료
driver.execute_script('window.scrollTo(200, 300);')
driver.quit()6. Xpath 📌
💡 scrapy는 Xpath를 사용하며 현업에서 쓴다.
xpath 이용한 엘리먼트 선택
//[@id="shoji"]/div[2]/div/div[2]/header/div/div[1]
// : 최상위 엘리먼트
(별표) : 모든 하위 엘리먼트[@id="shoji"] : 속성값으로 엘리먼트 선택
/ :한단계 하위 엘리먼트
div[2] : 태그[n번째]
selector = '//*[@id="shoji"]/div[2]/div/div[2]/header/div/div[1]'
driver.find_element(By.XPATH, selector).text7.Headless 📌
- 브라우져를 화면에 띄우지 않고 메모리상에서만 올려서 크롤링하는 방법
- window가 지원되지 않는 환경에서 사용이 가능
- chrome version 60.0.0.0 이상부터 지원 합니다.
op = webdriver.ChromeOptions()
op.add_argument('headless')
driver = webdriver.Chrome(options=op)
driver.get('https://www.ted.com/talks')
selector = '.talks-header__title'
driver.find_element(By.CSS_SELECTOR, selector).text