이론 📝
00. 전처리
01. 불필요한 변수 제거
df.drop(drop_cols, axis=1, inplace=True)
default는 axis=0
02. NaN 조치 (제거 or 채우기)
titanic.isna().sum() / len(titanic)*100
전체 데이터에서 결측치의 비율을 확인 후 시작!
- 모든 행 제거, 일부 행 제거, 변수 제거
- 평균값 채우기, 최빈값 채우기, 앞/뒤값 채우기, 선형보간법
03. 가변수화
범주형 값을 갖는 변수에 대한 One-Hot Encoding (get_dummies)
다중공선성 문제를 없애기 위해 drop_first=True 옵션 지정
01. 용어
- 모델: 데이터로부터 패턴을 찾아 수학식으로 정리해 놓은 것
- 모델링(Modeling): 오차가 적은 모델을 만드는 과정
- 평균보다는 좋은 모델을 만들어야함 (=평균보다 오차가 적다.)
- 모델 목적: 샘플을 가지고 전체를 추정
02. scikit-learn 모델링 구조
- 라이브러리 iimport
- 사용한 알고리즘을 모델로 선언
- 학습 (model.fit(x_train,y_train))
- 데이터 분리 시
- x = data.drop(target,axis=1)
y = data.loc[:,target]
- 예측 (model.predict(x_test))
- 평가 (예측 값과 실제 값 비교)
03. 회귀 모델 평가 지표
- 오차 합: 모든 오차의 합을 더함, but 합이 0이 되는 경우가 생겨서 못씀
- 오차 제곱의 합:
- 오차 절대값의 합:
- 실제값은 y, 예측값은 hat-y
- SSE(그냥 합), MSE(Mean Sum Squared Error, 합의 평균), RMSE (MSE에 Root)를 사용
- 고객에게 얘기할만한건 RMSE뿐
- MAE(Mean Absolute Error), MAPE(퍼센트,n으로 나누기 전에 y로 먼저 나눔)
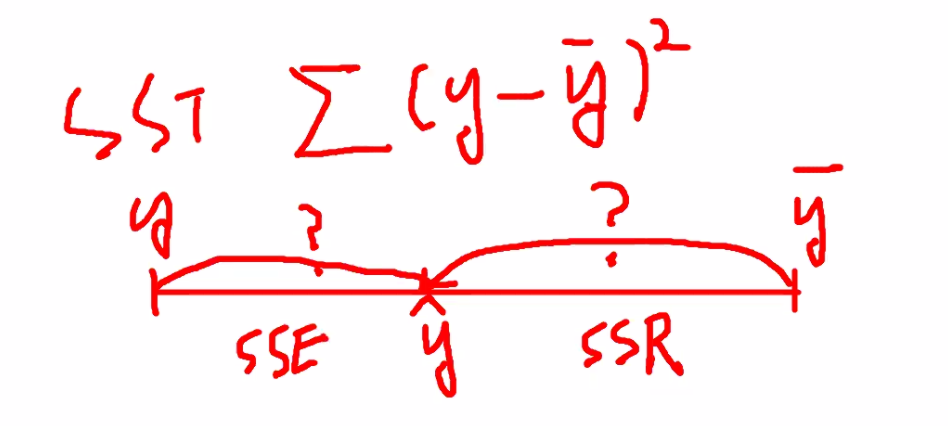
- STT: 전체 오차 (=허용된 전체 오차 범위,STT=SSE+SSR)
- SSR: 전체 오차 중 회귀식이 잡아낸 오차 (예측값-평균값)
- SSE: 전체 오차 중 회귀식이 잡아내지 못한 오타 (실제값-예측값)
SSE가 0이면 제일 좋고 SSR == SST면 제일 좋음
- 결정 계수 R-Squared
여기서 R은 Regression
가장 큰 값은 1 (클 수록 좋음)
우리 모델이 얼마나 설명을 잘 했는지 알려줌
04. 분류 모델 평가 지표
혼동 행렬 (Confusion Matrix)
- 정확도(Accuracy): 0,1을 정확히 예측한 비율 (맞춘 갯수/전체 갯수)
- 정밀도(Precision): 예측한 것 중 진짜 0,1의 갯수/예측한 0,1의 전체 갯수
- 재현율(Recall,민감도): 그중 예측한 0,1의 갯수/진짜 0,1의 갯수
- 특이도(Specificity): 실제 N비율(TN+FP) 중 N으로 예측한 비율(TN)
- F1-Score: 정밀도와 재현율의 조화평균, 분자가 같지만 분모가 다를 경우 사용 (정밀도와 재현율 적절히 요구 될 때 사용)
cassification_report 사용하면 다 보임
05. learning_curve
데이터의 양이 어느정도 필요하고 성능이 어느정도 나오는지 확인하는 그래프
# 모듈 둘러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import learning_curve
# 모셀선언
model = DecisionTreeClassifier(max_depth=3)
# Learning Curve 수행
tr_size, tr_scores, val_scores = learning_curve(model,
x,
y,
train_sizes=range(10, 7900, 20),
shuffle=True,
cv=5)# CV 결과 --> 평균
val_scores_3_mean = val_scores.mean(axis=1)
# 시각화
plt.figure(figsize=(8, 5))
plt.plot(tr_size, val_scores_3_mean)
plt.title('Learning Curve', size=20, pad=15)
plt.ylabel('Score')
plt.xlabel('Training Size')
plt.show()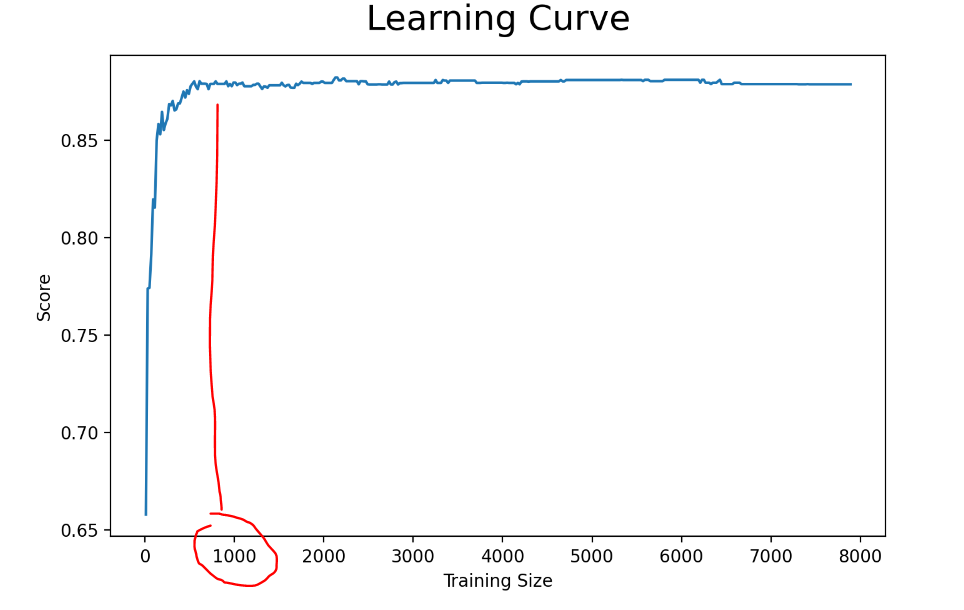
06. 다중공선성 확인
다른 변수가 또 다른 변수를 얼마나 설명하는지 확인
- 원본 데이터 대상으로 VIF 확인 :
# 모듈 불러오기
from statsmodels.stats.outliers_influence import variance_inflation_factor
# 빈 데이터프레임 만들기
vif = pd.DataFrame()
# VIF 확인 및 기록
vif['feature'] = x.columns
vif['vif_factor'] = [variance_inflation_factor(x.values, i) for i in range(x.shape[1])]
# VIF 기준으로 정렬렬
vif.sort_values(by='vif_factor', ascending=False, inplace=True)
vif.reset_index(drop=True, inplace=True)
# 확인
vif- 데이터를 표준화하고 확인
07. Regularization (규제)
선형회귀는 x값이 많을수록 과한 복잡성이 생김 > 성능 down
ridge, rasso 등으로 해결할 가능성이 있다.
1.Ridge
- Ridge 알고리즘을 사용하면 변수들의 가중치 크기를 제어
- 전체적으로 가중치의 크기를 줄여줌
- but 특정 변수의 가중치를 0으로 바꾸지는 않음
# 모델링(Ridge CV)
from sklearn.linear_model import RidgeCV
alpha = np.linspace(0.1, 30, 20)
model = RidgeCV(alphas=alpha, cv=5)
model.fit(x_train, y_train)
# 성능 확인
print('학습성능:', model.score(x_train, y_train))
print('평가성능:', model.score(x_test, y_test))
print('-' * 28)
print('alpha:', model.alpha_)- Lasso
- 필요없는 변수의 가중치는 0
- 불필요한 변수 제거 가능
# 모델링(LassoCV)
from sklearn.linear_model import LassoCV
alpha = np.linspace(0.1, 10, 50)
model = LassoCV(alphas=alpha, cv=5, random_state=1)
model.fit(x_train, y_train)
# 성능 확인
print('학습성능:', model.score(x_train, y_train))
print('평가성능:', model.score(x_test, y_test))
print('-' * 28)
print('alpha:', model.alpha_)- ElasticNet
- 릿지랑 라쏘를 다 씀
# 모델링(ElasticNetCV)
from sklearn.linear_model import ElasticNetCV
l1 = np.linspace(0.1, 1, 10)
alpha = np.linspace(0.1, 10, 50)
model = ElasticNetCV(l1_ratio=l1, alphas=alpha, cv=5, random_state=1)
model.fit(x_train, y_train)
# 성능 확인
print('학습성능:', model.score(x_train, y_train))
print('평가성능:', model.score(x_test, y_test))
print('-' * 28)
print('l1_ratio:', model.l1_ratio_)
print('alpha:', model.alpha_)08. 거리 구하기
별에서 원까지 거리 구할 때의 두 가지 방식
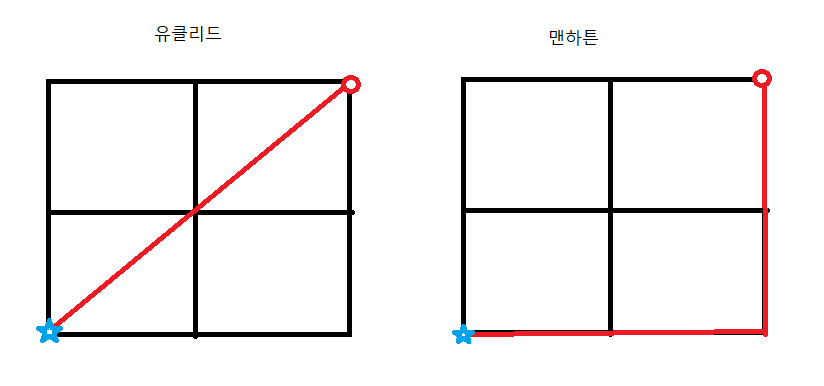
- 맨하튼 거리는 유클리드 거리보다 항상 크거나 같다.
09. 정규화
10. 불순도
- 결정트리
(부모 불순도 - 자녀 불순도)가 클 수록 좋다.
부모 노드 --> 자식 노드로의 분기가 되는데 정보이득이 큰 분기를 찾음
정보 이득이 크다 == 속성으로 분할 시 불순도가 작아짐
== 정보 이득이 가장 큰 속성부터 분할
밑은 변수 중요도 시각화 코드
plt.figure(figsize=(5, 5))
plt.barh(list(x), model.feature_importances_)
plt.show()밑은 중요도를 정렬해서 시각화
# 데이터프레임 만들기
perf_dic = {'feature':list(x), 'importance': model.feature_importances_}
df = pd.DataFrame(perf_dic)
df.sort_values(by='importance', ascending=True, inplace=True)
# 시각화
plt.figure(figsize=(5, 5))
plt.barh(df['feature'], df['importance'])
plt.show()11. 앙상블
- 보팅 (Voting)
같은 데이터셋 서로 다른 알고리즘의 예측값을 가지고 투표
- 하드 보팅
서로 다른 알고리즘을 돌려 예측값을 투표, 단순히 많이 나온 것을 결과로 - 소프트 보팅
서로 다른 알고리즘을 돌려 예측값을 확률로 투표
-
배깅 (Bagging)
다르게 샘플링(복원추출)된 데이터셋과 같은 알고리즘을 사용
범주형은 voting, 연속형은 평균으로 결과 집계 (aggregating)
ex) 랜덤 포레스트 -
부스팅 (Boosting)
오류를 예측하는 모델을 만들어서 반영 (gradient boost)
어디에서 멈출지 파라미터 튜닝해야함 -
스태킹 (Stacking)
raw데이터를 가지고 모델들이 예측한 값을 input으로 받는 최종 모델을 만들어 결과를 예측
