이론 📝
0. Review
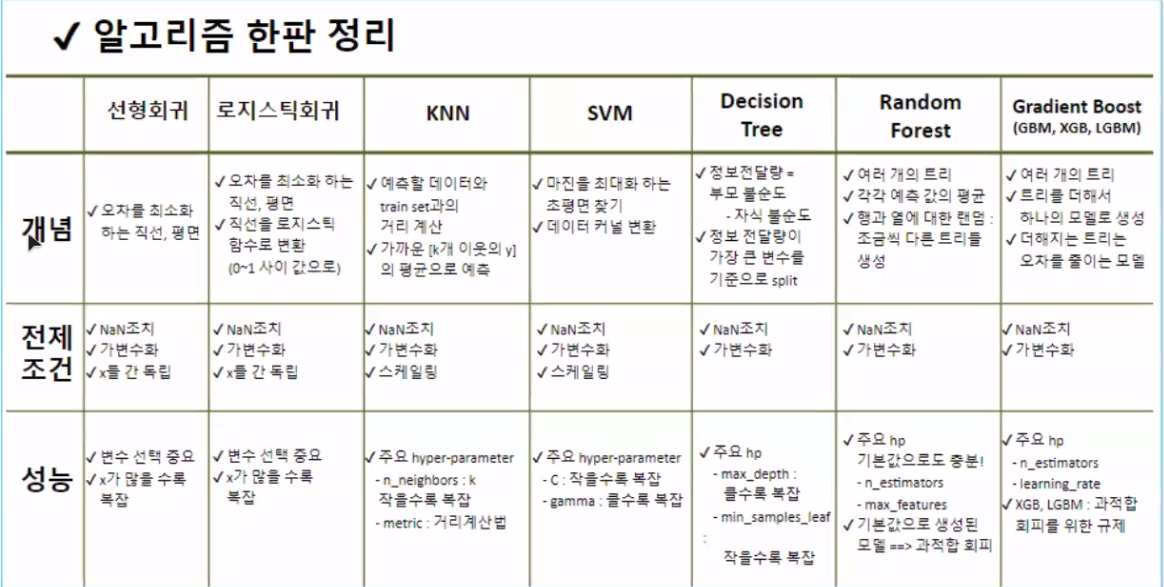
XAI: 설명가능 인공지능
1. 모델 해석하기 📌
💡 요약
Q1. 모델 전체에서 중요한 요인은?
A1. FI(tree 기반), PFI(tree 외 알고리즘)Q2. 중요한 변수의 값이 변할 때 예측 값에 영향은?
A2. PDPQ3. 개별 데이터에서 어떤 feature 값이 예측값 영향을 끼친 정도
A3. SHAP (성능이 좋은 모델 > explainer 선언 > shap 값 추출 > 그래프)
1) 비즈니스를 위한 인공지능 📌
pm을 하게 되면 변화관리에 주의
Q) 모델은 왜 그렇게 예측 했나요?
Q) 모델은 비즈니스 문제를 해결할 수 있을까요?
2) 왜 너를 믿어야하지? 📌
해석
- input에 대해 모델이 왜 그런 output을 예측했는가?
- 어떤 변수가 모델에서 가장 중요한가?
- whitebox model (본질적으로 해석 가능)
설명
- 해석을 포함
- 추가로 투명성에 대한 요구
- Model transparency : 모델이 어떻게 학습되는지 단계별 설명 가능해야 함.
- 최근 추세는 설명과 해석을 혼용해서 사용
설명이 잘 되는 알고리즘은 대체로 성능이 낮다.
3) 모델에 대한 설명 📌
< 전체 데이터 관점 >
1. 모델 전체에서 어떤 feature가 중요할까? (FI, PFI)
2. 특정 feature 값의 변화에 따라 예측 값은 어떻게 달라질까? (PDP)
< 개별 데이터 관점 >
3. 이 데이터(분석단위)는 왜 그러한 결과로 예측되었을까? (SHAP)
변수 중요도 (FI,PFI)
성능 낮은 모델에선 의미 없음
예측값에 중요한 변수
트리기반 모델에서 뽑아낼 수 있음
트리모델 말고는 FI를 어떻게 구함?
Permutation Feature Importance로 구함• Permutation: 순서가 부여된 임의의 집합을 다른 순서로 뒤섞는 연산
• Feature 하나의 데이터를 무작위로 섞을 때, model의 score가 얼마나 감소되는 지로 계산원래 스코어 - (섞었을 때 스코어*여러번)의 평균 = 최종 변수 중요도
feature 순서 섞어서 predict했을 때 변화가 적다 = 어차피 영향이 없던거
변화가 크다 = 성능에 영향이 갈 정도로 중요하다⭐ 단점: 다중공선성이 있다면 score가 별 차이 없음
from sklearn.inspection import permutation_importance
pfi = permutation_importance(model,x_val,y_val,n_repeats=10,random_state=2023)다중공선성: 분산 팽창 지수로 가려내야함
PDP
관심 feature의 값이 변할 때 모델에 미치는 영향을 시각화
x:관심 feature, y:예측값
SHAP (SHapley Additive exPlanations)
Shapley Value: 모든 가능한 조합에서, 하나의 feature에 대한 평균 기여도를 계산한 값
기여도 : 조합에 대한 예측값 - (조합(-특정 피처))의 예측 값
위 기여도에 가중치를 곱하여, 각 조합의 기여도를 합침
= 가중 평균 기여도
- 예측값이 왜 이렇게 나왔습니까?에 대한 근거임
1) Shapley Value 만들기
explainer1 = shap.TreeExplainer(model1)
shap_values1 = explainer1.shap_values(x_train)+는 결과예측의 긍정요인, -는 결과예측의 부정요인

# y_train의 평균
explainer1.expected_value
shap.initjs() # javascript 시각화 라이브러리 --> colab에서는 모든 셀에 포함시켜야 함.
# force_plot(전체평균, shapley_values, input)
shap.force_plot(explainer1.expected_value, shap_values1[0, :], x_train.iloc[0,:])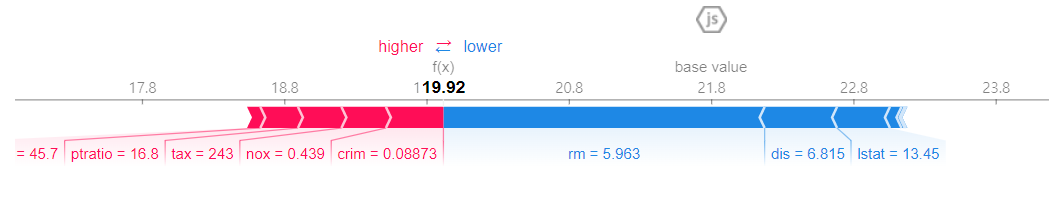
예측값들의 평균은 base value (21.8)
0행의 예측값은 평균보다 작음, 그 값의 하락요인은 rm, dis, lstat 등이 화살표 범위(그래프의 폭)만큼 작용함(기여도), 숫자는 실제 데이터값
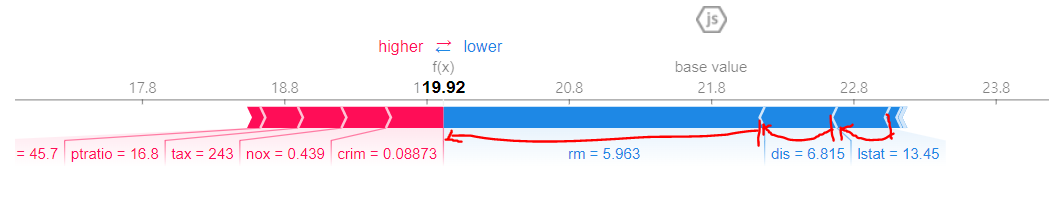

위 사진과 같은 의미!
전체 평균에 개별 데이터의 shap value를 다 더하면 그 행의 예측 값
shap 값이 그 차이에 대해 기여도를 계산한 것
분류문제면 shap value는 확률에 대한 기여도로 해석
전체 흐름에 벗어나는 값 분석
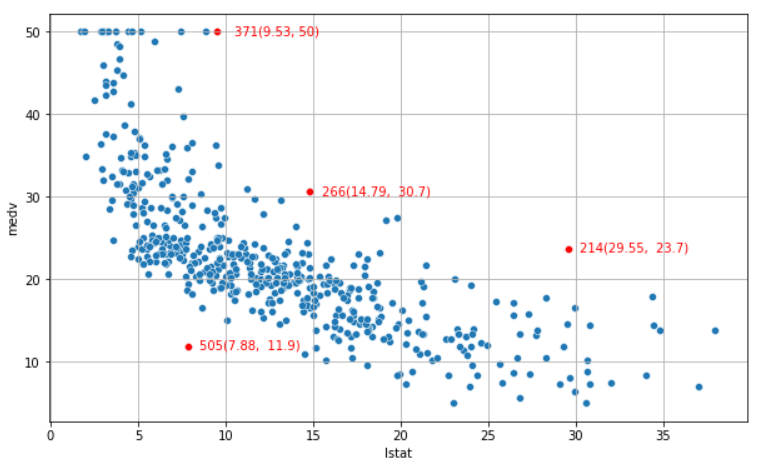
하위 계층의 비율이 높은데 214 인덱스는 집값은 높다, 이유가 뭘까?
같은 case에 대한 의문
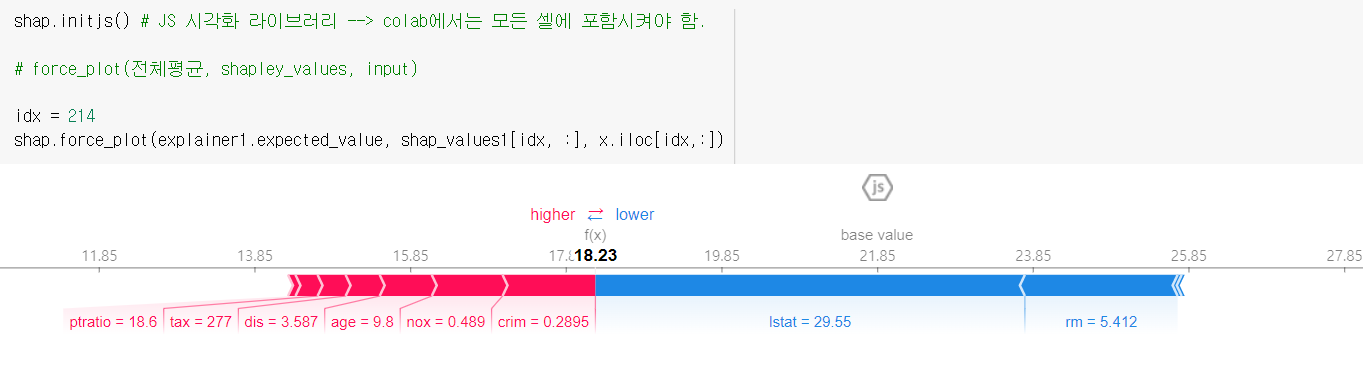
그래서 예측값에 대한 분석 (실제값은 23.7)
확실히 예측값에선 lstat이 하락 요인으로 꼽힘
범죄율, 오염도, 연식 등등이 상승 요인으로 꼽힘
상승요인 덕에 근처랑 lstat이 비슷해도 실제 집 값이 높을 수 있음.
(ex. 하위계층 비율이 높은 다른 지역에 비해 상대적으로 범죄율이나 공기오염도가 상대적으로 낮다~)
각각의 기여도 sum = 베이스 값-예측값
전체적으로 보기
점 하나: 분석단위별 feature 기여도
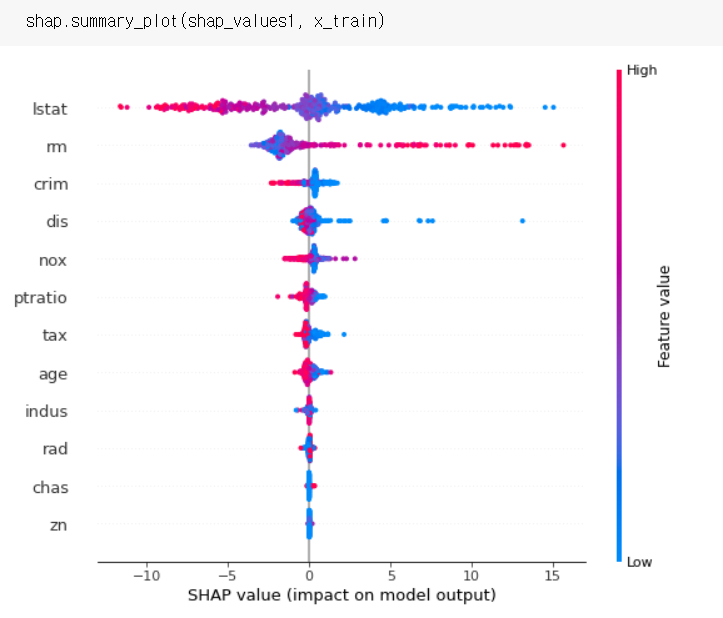
변수 중요도로 치환해서 볼 수 있다.
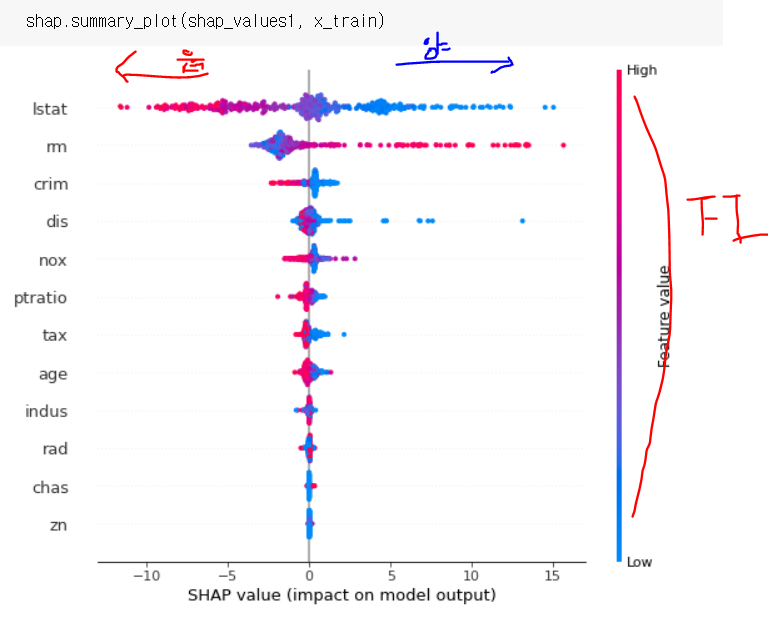
rm은 양의기여도가 분포가 크고 음의기여도가 분포가 작다.
즉, rm값이 작을 때는 집값이 떨어질 때 크게 영향을 안줌
근데!!방의 수(rm)가 많으면!!집값 높이는데!!크게 영향을 줌!!!
2. 모델 평가하기 📌
1) 비즈니스 문제 상황 파악
- ex. 수익 구조 등
2) 평가 전 질문
- 어떤 문제 해결을 위해 모델을 만들었는가?
- 실제 목적에 맞게 모델 결과는 평가하고 있는가?
- 모델 예측 결과에 대한 현장의 비즈니스 프로세스는 어떻게 정의되어 있는가?
3) 문제 정의 및 평가
- 고객사의 비즈니스 문제는 무엇?
- 모델의 예측 결과로 인한 비즈니스 프로세스는 무엇?
- 모델은 비즈니스 관점으로 어떻게 평가?
4) 평가 지표
- RMSE나 f1-score나 이런건 고객사에게 설명한다고 이해가 될까? 안됨.
고객이 이해할 수 있는 지표로 평가해야함 - 타겟 마케팅에서 모델 예측 결과표(confusion matrix)와 비즈니스 가치표(보통 고객사가 제시 또는 합의)를 곱해서 모델 기대가치를 계산
5) 회귀 모델은?
- 예측값에 따른 후속 비즈니스 프로세스 정리
- 시뮬레이션을 돌려야 함
- ex. 수요량 예측 문제라면 시물레이션 이후 재고 회전률 등으로 전체 계산 후 평가
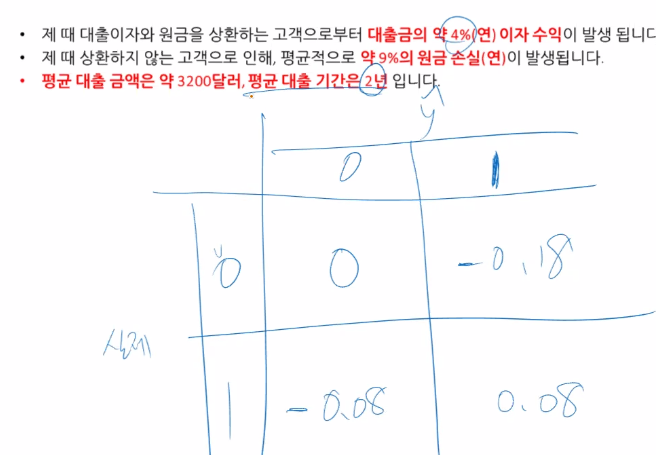
0이라고 예측하면 거절할거임, 1이라고 예측하면 수익을 얻을 수 있음
따라서 -0.08은 1인데 0으로 예측함으로 얻을 수 있었던 수익을 못 얻는다는 가정하에 -임
0을 0으로 예측한건 그냥 모델이 잘 맞춰서 잘 피해간거니 +-0임
# 비즈니스 가치 매트릭스 정의
bv = np.array([[0,-0.18],[-0.08,0.08]])
# 모델 성적표 추출
cm1 = confusion_matrix(y_val,pred1)
cm1_p = cm1/np.sum(cm1)
# 기대가치 계산
np.sum(bv*cm1_p)*3200함수화, scoring에 넣어주기
def biz_score(y, pred, biz_v):
cm = confusion_matrix(y, pred)
cm_p = cm / np.sum(cm)
amt_mean = 3200
return np.sum(biz_v * cm_p) * amt_mean
b_score = make_scorer(biz_score, greater_is_better= True, biz_v = bv )3. 기타
.fit(): 전체 오차가 가장 적어지는 모델이라서 클래스 불균형이 있을 때 소수의 클래스를 잘 못 맞춰 recall이 떨어지는 현상이 발생
SMOTE: 보간법으로 upsamling 해줌
upsamling: 복원추출해서 upsamling 해줌
