특이한 컨볼루션 레이어들이 엄청 많다...
AIVLE 과정에서는 다루지 않고 내가 따로 공부하면서 알게된 것들이 많아서 그것에 대한 정리도 필요할듯....
이론 📝
CNN 📌
Convolutional Layer
이미지 구조를 파괴하지 않으며 위치정보 보존하기 위함
(이미지 구조를 유지한 채로 부분에서 특징을 뽑음)
- filters : 피처맵의 개수를 능동적으로 조절
- strides : 몇 칸 띄우면서 사용할지 조절
- padding : 'same'으로 적용하면 피처맵 결과 사이즈가 인풋과 같음
- kernel_size : 필터(윈도우)의 가로세로 사이즈
- activation : 활성화 함수
Feature map
- conv의 filter를 거치면 나옴
- conv의 목적이 여기서 달성됨
Pooling (Subsampling - downsampling)
- 연산량 자체를 줄이기 위함
- 풀링 사이즈에 맞게 피처맵 사이즈가 줄음
- pool_size
- strides : 원래는 pool_size를 따라감
- Maxpool은 가장 영향력이 큰 정보를 남김
- AvgPool은 정보를 버리지 않고 요약
preprocessing의 목적
- 데이터를 문제 해결 가능한 구조로 변경
- 모델 성능 향상
padding의 목적
- 외곽 정보를 좀 더 추출
- 이미지 사이즈 유지
모델의 구조만 보고 정보들을 파악할 수 있어야함
논문 갖고 연습필요
💡 관련 계산
파라미터개수등...찾아서 적기
object detection 📌
- 딥러닝에서 지도학습이란 error를 줄여나가는 방향으로 가중치를 업데이트 하는 것
- CNN은 위치정보를 보존하면서 이미지의 특징을 추출하는 백본으로 사용됨
- object detection = bounding box regression + multi class-classification
= localization + classification - 대표적인 모델로 yolo가 있음 (one-stage detector)
- two-stage detector는 속도가 너무 느려 실시간 처리가 불가함
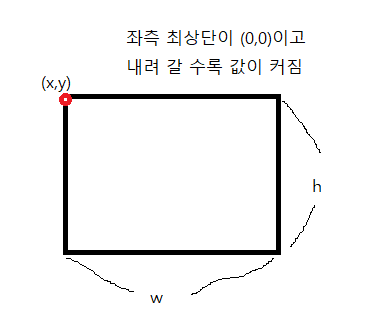
bounding box
- 하나의 오브젝트가 포함되어 있는 최소 크기의 박스
- x,y: 좌표 / w,h: 크기
class classification
- 어떤 클래스인지 알려주는 과정
confidence score
- 어떤 오브젝트가 진짜 바운딩 박스안에 있는게 맞는지의 척도
- 0~1
- ground-truth boundung box는 1
- object가 바운딩 박스에 있는지 여부와 iou값을 곱한것
pretrained model 📌
유사한 문제를 해결하기 위해 다른 사람이 생성하고 대규모 데이터 세트에서 훈련된 모델 또는 저장된 네트워크
transfer learning 📌
데이터셋을 해결하려는 문제에 맞춰 재구성하고 이 데이터셋을 사전학습 모델에 학습 시킴
Pre-trained model을 다음과 같은 형태로 사용될 수 있음
-
Feature extraction
: output layer만 새로운 문제에 맞게 수정하고 그대로 사용 -
pre-trained model 아키텍쳐 사용
: 아키텍쳐만 채용하고 weight는 initialize -
일부 layer만 training하고 나머지 layer는 고정
: 부분적으로 training 하는 방법. 보통 초기 layer (input에 가까운 layer)를 고정하고 상위 layer(output에 가까운 layer)를 training 하는 방법
실습 💻
MNIST 복습 📌
데이터 로딩 및 구조 변경
data = io.loadmat("notMNIST_small.mat")
X = data['images']
y = data['labels']
resolution = 28
classes = 10
X = np.transpose(X, (2, 0, 1))
y = y.astype('int32')
X = X.astype('float32') / 255.
# shape: (sample, x, y, channel)
X = X.reshape((-1, resolution, resolution, 1))
# y one-hot encoding
from tensorflow.keras.utils import to_categorical
num_classes = len(np.unique(y))
y = to_categorical(y,num_classes)
# splitting data
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=2023)
모델 정의
from tensorflow import keras
keras.backend.clear_session()
model = keras.models.Sequential()
model.add(keras.layers.Input(shape=(28,28,1)))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128,activation='relu'))
model.add(keras.layers.Dense(128,activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(64,activation='relu'))
model.add(keras.layers.Dense(64,activation='relu'))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Dropout(0.2))
model.add(keras.layers.Dense(10,activation='softmax')) #output개수가 10개중 확률
model.compile(loss='categorical_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])
model.summary()early stopping 정의
es = keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0,
patience=10,
verbose=1,
restore_best_weights=True) 모델 훈련
model.fit(x_train,y_train, epochs=100, validation_split=0.2, callbacks = [es])