SQLD
1.SQLD

뭔가 다들 sqld가 있는 것 같다... 남이 있으면 나도 있어야 한다. 3월에 시험이니 한번에 붙어 보자.참고로 시험 범위는 다음과 같다.https://www.dataq.or.kr/www/sub/a_04.do일단 기출을 풀자 하고 노랭이 샀는데 이거 sqlp
2.SQLD 1-1-1 데이터 모델링의 이해
모델링 : 복잡한 현실 세계의 데이터를 사용하기 위한 설계 수행 과정데이터 모델 : 현실의 대상을 데이터로 사용하기 위한 설계도1) 추상화 (=모형화) : 형식에 맞춰 간략히 표현2) 단순화 : 정해진 표기법/언어로 표현3) 명확화 (=정확화) : 모호함 제거참고로
3.SQLD 1-1-2 엔터티

엔터티 : 데이터 저장, 관리 집합 (= 인스턴스 집합)유형 엔터티 : 물리적 형태 있음예) 학생무형 엔터티 : 물리적 형태 없고 개념적 정보 예) 수업사건 엔터티 : 업무 중 발생하는 사건 (혼자 존재 X)예) 수강신청기본 엔터티 : 기본 정보, 독립적으로 생성예)
4.SQLD 1-1-3 속성
인스턴스의 구성 요소, 데이터의 최소 단위업무에서 필요한 정보엔터티는 2개 이상의 속성 가짐.주식별자에 종속속성당 값은 1개업무에서 쓰는 용어 사용약어 지양명사형으로 수식어, 소유격 지양전체 데이터 모델에서 유일성 확보 (product_id)도메인 : 각 속성이 가질
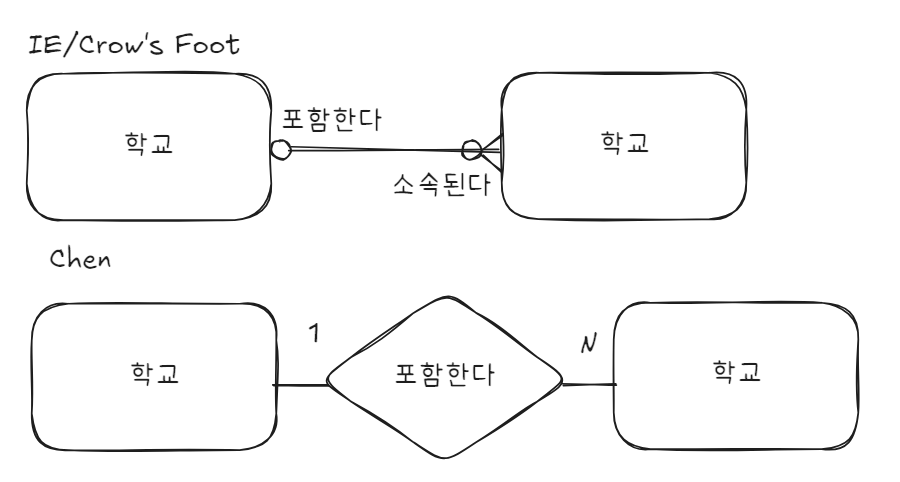
5.SQLD 1-1-4 관계
관계 : 인스턴스 사이의 논리적 연관성. 페어링 : 엔터티 안의 인스턴스가 개별적으로 관계를 가짐.\-> 관계 = 페어링 집합연결 목적으로 분류하나의 엔터티가 다른 엔터티에 속함독립적 존재연관관계 (UML)(실선으로 표현)멤버 변수로 선언하여 사용혼자서는 존재 불가 의
6.SQLD 1-1-5 식별자
각 인스턴스를 구분할 수 있게 하는 대표 속성\-> 엔터티 필수 요소\+) DB에서는 키라고도 함유일성 : 중복 X최소성 : 하나의 속성으로 구분 가능시 추가 X불변성 : 바뀜 안됨존재성 : null 안됨주식별자 : 대표성을 나타내는 식별자 (PK)보조 식별자 : 주식
7.SQLD 1-2-1 정규화
\+) 데이터 모델링 순서정규화DB 용량 산정트랜젝션 유형 파악반정규화이력모델 조정, PK,FK 조정, 슈퍼/서브 타입 조정성능 검증정규화 : 데이터의 중복 제거, 일관성, 유연성 유지를 위해 데이터를 분리 하는 과정\-> 정규화를 통해 삭제 이상, 삽입 이상, 갱신
8.SQLD 1-2-2 관계와 조인의 이해
엔터티와 인스턴스 간 논리적 연관성\-> 관계를 맺음 = 식별자를 상속, 그걸로 매핑 (FK 쓴다고)존재 관계 : 엔터티가 다른 엔터티에 속함예) 학생과 학과행위 관계 : 행위를 통해 발생 예) 구매 내역식별자로 매핑-> 데이터 결합하기(보통 외래키를 씀)자기 자신하고
9.SQLD 1-2-3 모델이 표현하는 트랜잭션의 이해
@Transaction트랜잭션 : 업무처리 위한 논리적 작업 단위\+) 트랜잭션에 의한 관계는 필수적 관계 형태원자성 : 전부 처리되거나, 전부 안되거나일관성 : 트랜잭션 했다고 DB 모순되면 안됨격리성 : 중간에가외부에서 참조, 수정 불가영속성/지속성 : DB에 영속
10.SQLD 1-2-4 Null 속성의 이해
Null : 아직 정의되지 않은 값 \- null은 연산해도 nullnull은 비교하면 unknown 반환집계함수에서는 제외
11.SQLD 1-2-5 본질 식별자 VS 인조 식별자
업무에 의해 만들어지는 식별자본질 식별자로 만들어진 식별자장점 : 개발 편의성 증가단점 : 중복 데이터 발생, 불필요 인덱스 생성 가능
12.SQLD 2-1-1 관계형 DB 개요
데이터베이스 : 데이터를 일정한 형태로 저장관계형 데이터베이스 시스템 : 데이터를 효율적으로 관리, 복구 해주는 시스템 1960 : FlowChart 중심, 파일구조1970 : 계층형, 망형 DB 1980 : 관계형 DB1990 : 객체 관계형 DBsql 문장으로 관리
13.SQLD 2-1-2 SELECT문
SELECT문 SQL 문장 종류 데이터 조작어 (DML) : SELECT, INSERT, UPDATE, DELETE 데이터 정의어 (DDL) : CREATE, ALTER, DROP, RENAME 데이터 제어어 (DCL) : GRANT, REVOKE 트랜잭션 제어어 (
14.SQLD 2-1-3 함수
입력값 받아서 출력값 반환입력: 출력 = 1:1데이터 변환, 조작용 (SELECT, WHERE, ORDER BY등)함수 중첩 가능여러행으로 하나의 결과값 리턴합계, 평균등 (SELECT, HAVING등)GROUP BY랑 같이 쓰기도 함🔢 숫자 함수🔤 문자열 함수 (
15.SQLD 2-1-4 WHERE
WHERE 조건에 맞는 데이터 필터링 -null도 IS NULL과 IS NOT NULL로 조회 가능 집계 함수는 불가 (이건 HAVING에서 사용) 연산자 | 우선순위 | 연산자 | 설명 | | ----
16.SQLD 2-1-5 GROUP BY와 HAVING
데이터를 묶어서 그룹의 통계 얻을 때 사용\-> 레벨 별로 사용자를 묶어서 각 레벨 별 인원수를 구한다.이때, 그룹화되지 않은 컬럼은 사용 불가. (예: 저 상태에서 사용자별 코인 수 조회는 불가. 단, AVG 같이 집계함수를 사용하면 가능)즉, GROUP BY로 묶고
17.SQLD 2-1-6 ORDER BY
데이터 정렬함ASC : 오름차순 (기본값)DESC : 내림차순\-> 이렇게 하면 나이순으로 내림차순 된다.복수의 컬럼을 기준으로도 가능. (왼쪽에 있는 게 우선 순위 높아짐)as 사용 가능null의 경우 오라클에서는 최댓값, SQL Server에서는 최솟값 취급SELE
18.SQLD 2-1-7 Join
여러 테이블 참조, 출력용보통 PK, FK로 조인함A,B,C 테이블 조인시 A,B 하고 그 결과를 C와 하는 방식으로 진행됨테이블간 컬럼이 일치하는 경우 사용오라클 버전ANSI/ISO SQL 버전테이블 간 컬럼이 일치하지 않을 때 사용\-> 범위를 가지고 조회에 사용조
19.SQLD 2-1-8 표준 Join
ANSI 표준으로 작성되는 조인INNER / CROSS / NATURAL / OUTER선택, 투영, 합집합, 차집합, 곱집합으로관계를 입력받아 관계를 출력하는 관계대수의 기본 연산자\+) DIVIDE는 이제 안 쓴다.내부 조인. 조건이 일치하는 교집합만 보여줌오라클은
20. SQLD 2-2-1 서브쿼리
\-SQL 안에 있는 SQL괄호로 감싸야 함단일행, 복수행 비교 연산자 사용 가능ORDER BY 사용 불가.\-> 특정 값 계산이나 테이블 같이, WHERE에서 조건 비교용으로 활용할 수 있다.인라인 뷰 같이 쓸 떄 조인할 테이블의 기본키가 2개 이상이면 WHERE에서
21.SQLD 2-2-2 집합 연산자
SELECT문 결과를 집합 취급해서 집합 연산하기\-> 두 집합 간 컬럼의 순서와 타입이 호환되어야 함 (이때, 타입은 첫번째 집합에 의해 결정)\-> 두개 이상의 테이블에서 join 없이 연관 데이터 조회하는 방법중복 데이터는 1번만 출력하는 합집합중복 데이터도 다
22.SQLD 2-2-3 그룹함수
ANSI/ISO SQL 표준 데이터 분석용 함수null 값은 무시한다.행의 개수를 카운트특정 컬럼만 카운트 할 경우, null 값은 카운트 안함총 합 출력숫자 컬럼만 사용 가능평균 출력 (숫자 컬럼만 사용 가능)최대, 최소 출력날자, 숫자, 문자 모두 사용 가능분산,
23.SQLD 2-2-4 윈도우 함수
윈도우 함수 조인, 서브쿼리 없이 행과 행간 비교, 연산하게 해줌 각 행 유지하며 연산 가능 (GROUP BY 안해도 OK) 윈도우 함수 안에 집계, 순위 함수 같은 걸 넣는다. PARTITION BY : 그룹 연산 수행할 그룹 지정 ORDER BY : 순위
24.SQLD 2-2-5 TOP N 쿼리
TOP N 쿼리 TOP N 쿼리 전체 데이터에서 상위 N개 행 추출 (페이징) TOP-N 행 추출 방법 ROWNUM 출력 데이터 기준으로 행 번호 부여 -> 정렬 기준에 따라 바뀜 단, 가상 번호라 특정 행 지정 불가
25.SQLD 2-2-6 계층형 질의와 셀프 조인
START WITH : 시작점 지정CONNECT BY PRIOR : 이어질 행의 조건NOCYCLE : 루프 방지PRIOR : PRIOR 컬럼A = 컬럼B -> 컬럼 A 읽고 그 값이 일치하는 컬럼 B 연결자식 = 부모 : 순방향 전계부모 = 자식 : 역방향 전계\->
26.SQLD 2-2-7 PIVOT 절과 UNPIVOT절
하나의 속성 -> 하나의 컬럼 동일 키 값 반복 가능RDBMS 설계 방식타 테이블과 조인 연산 가능행 : 관찰 단위열 : 측정 변수, 속성하나의 속성 -> 여러 컬럼 \-> 데이터가 많으면 열도 많아짐타 테이블과 조인 불가PIVOT : long data -> wide
27.SQLD2-2-8 정규 표현식
정규 표현식 문자열의 공통 규칙을 일반화 해서 표현 정규 표현식 사용 가능한 문자 함수 제공 특정 패턴 찾기에 유리 정규 표현식 종류 1️⃣ 기본 메타 문자 | 표현식 | 의미 | | | --- | --------- | -- | | . | 임의의
28.SQLD 합격!

와~ 이론은 인터넷 찾아보고 책은 노랭이(문제만 있는 그거)만 한 3~4번 돌린 것 같다. 의외로 거기서 한 2,3 문제는 나온 것 같기도?