앞서 OneToMany V2에서의 문제점들에 대한 해결방안을 제시합니다.
Order -> OrderCollectionDTO로 변환해서 Response로 보내는 부분은 동일하기 때문에 다루지 않겠습니다.
V3_0: JOIN FETCH
API
@GetMapping("api/v3_0/collection-orders")
private Result ordersV3_0() {
List<Order> orders = orderRepository.findAllWithItem0();
List<OrderCollectionDTO> orderDTOS = orders.stream()
.map(o -> new OrderCollectionDTO(o))
.collect(Collectors.toList());
return new Result(orderDTOS);
} findAllWithItem0()
public List<Order> findAllWithItem0() {
String query = "select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i";
return em.createQuery(query, Order.class)
.getResultList();
}orders를 가져올때 JOIN FETCH를 사용해서 가져옵니다. 하지만, JOIN FETCH로 orderItems도 가져올 경우, 문제가 발생합니다. 결과 값에서 중복이 나타납니다.
{ * "data": [ * { * "orderId": 4, * "username": "userA", * "orderDate": "2022-04-19T11:14:55.235249", * "orderStatus": "ORDER", * "address": { * (생략) * }, * "orderItems": [ * { * "itemName": "JPA1 Book", * (생략) * }, * { * "itemName": "JPA2 Book", * (생략) * } * ] * }, * { * "orderId": 4, * "username": "userA", * "orderDate": "2022-04-19T11:14:55.235249", * "orderStatus": "ORDER", * "address": { * (생략) * }, * "orderItems": [ * { * "itemName": "JPA1 Book", * (생략) * }, * { * "itemName": "JPA2 Book", * (생략) * } * ] * }, * { * "orderId": 11, * "username": "userB", * "orderDate": "2022-04-19T11:14:55.356448", * "orderStatus": "ORDER", * "address": { * (생략) * }, * "orderItems": [ * { * "itemName": "Spring1 Book", * (생략) * }, * { * "itemName": "Spring2 Book", * (생략) * } * ] * }, * { * "orderId": 11, * "username": "userB", * "orderDate": "2022-04-19T11:14:55.356448", * "orderStatus": "ORDER", * "address": { * (생략) * }, * "orderItems": [ * { * "itemName": "Spring1 Book", * (생략) * }, * { * "itemName": "Spring2 Book", * (생략) * } * ] * } * ] * }Response 값을 보면 중복이 생기는 것을 확인 할 수 있습니다. 이러한 이유는 처리 되는 SQL과 같이 보면 이해하기 쉽습니다.
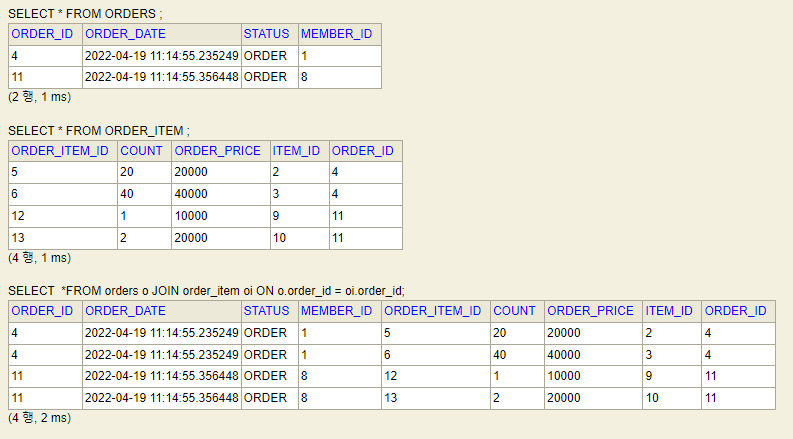
JOIN FETCH로 ordeItems를 가져오는 것을 생각해면, 'SELECT *FROM orders o JOIN order_item oi ON o.order_id = oi.order_id;' 과 유사합니다. Orders와 order_item에 아래 사진과 같은 데이터가 있을때, JOIN을 할 경우 총 튜플이 4개가 반환이 됩니다.
이떄, JPA에서는 각 튜플이 다르다고 생각하기 때문에 중복된 결과가 나오게 됩니다. 이러한 에러를 해결하기 위해서 DISTINCT를 사용합니다.
V3_1: JOIN FETCH +DISTINCT
API
@GetMapping("api/v3_1/collection-orders")
private Result ordersV3_1() {
List<Order> orders = orderRepository.findAllWithItem1();
List<OrderCollectionDTO> orderDTOS = orders.stream()
.map(o -> new OrderCollectionDTO(o))
.collect(Collectors.toList());
return new Result(orderDTOS);
}findAllWithItem1()
public List<Order> findAllWithItem1() {
String query = "select distinct o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d" +
" join fetch o.orderItems oi" +
" join fetch oi.item i";
return em.createQuery(query, Order.class)
.getResultList();
}createQuery를 실행할때, distinct를 이용해서 중복되는 엔티티를 가져오는 것을 해결합니다.
/** * (쿼리문:) * select distinct order0_.order_id as order_id1_9_0_, member1_.member_id as member_i1_6_1_, delivery2_.delivery_id as delivery1_4_2_, orderitems3_.order_item_id as order_it1_8_3_, item4_.item_id as item_id2_5_4_, order0_.member_id as member_i4_9_0_, order0_.order_date as order_da2_9_0_, order0_.status as status3_9_0_, member1_.city as city2_6_1_, member1_.street as street3_6_1_, member1_.zipcode as zipcode4_6_1_, member1_.username as username5_6_1_, delivery2_.city as city2_4_2_, delivery2_.street as street3_4_2_, delivery2_.zipcode as zipcode4_4_2_, delivery2_.order_id as order_id6_4_2_, delivery2_.status as status5_4_2_, orderitems3_.count as count2_8_3_, orderitems3_.item_id as item_id4_8_3_, orderitems3_.order_id as order_id5_8_3_, orderitems3_.order_price as order_pr3_8_3_, orderitems3_.order_id as order_id5_8_0__, orderitems3_.order_item_id as order_it1_8_0__, item4_.name as name3_5_4_, item4_.price as price4_5_4_, item4_.quantity as quantity5_5_4_, item4_1_.artist as artist1_0_4_, item4_1_.etc as etc2_0_4_, item4_2_.author as author1_1_4_, item4_2_.isbn as isbn2_1_4_, item4_3_.actor as actor1_7_4_, item4_3_.director as director2_7_4_, item4_.dtype as dtype1_5_4_ from orders order0_ inner join member member1_ on order0_.member_id=member1_.member_id * inner join delivery delivery2_ on order0_.order_id=delivery2_.order_id * inner join order_item orderitems3_ on order0_.order_id=orderitems3_.order_id inner join item item4_ on orderitems3_.item_id=item4_.item_id * left outer join album item4_1_ on item4_.item_id=item4_1_.item_id * left outer join book item4_2_ on item4_.item_id=item4_2_.item_id * left outer join movie item4_3_ on item4_.item_id=item4_3_.item_id * => 쿼리문 총 1개 처리 * * { * "data": [ * { * "orderId": 4, * "username": "userA", * "orderDate": "2022-04-19T11:39:58.086423", * "orderStatus": "ORDER", * "address": { * "city": "seoul", * "street": "street", * "zipcode": "12345" * }, * "orderItems": [ * { * "itemName": "JPA1 Book", * "orderPrice": 20000, * "count": 20 * }, * { * "itemName": "JPA2 Book", * "orderPrice": 40000, * "count": 40 * } * ] * }, * { * "orderId": 11, * "username": "userB", * "orderDate": "2022-04-19T11:39:58.193136", * "orderStatus": "ORDER", * "address": { * "city": "ulsan", * "street": "blvd", * "zipcode": "22345" * }, * "orderItems": [ * { * "itemName": "Spring1 Book", * "orderPrice": 10000, * "count": 1 * }, * { * "itemName": "Spring2 Book", * "orderPrice": 20000, * "count": 2 * } * ] * } * ] * } */(Distinct에 관한 내용은 이미 다뤘으므로 생략합니다. https://velog.io/@k_ms1998/JPA-JPQL-JOIN-FETCH 참고)
Distinct 덕분에 중복된 값을 반환 받는 것을 해결 했지만, 컬렉션을 JOIN FETCH하게 되면 페이징(Paging)이 불가능해진다는 문제점이 있습니다. 이러한 문제점을 극복하기 위해서 V3_2를 보겠습니다.
Spring에서 컬렉에서 OneToMany 또는 ManyToMany일때 페이징을 막아둔 이유는 JOIN 하는 엔티티의 튜플 수 보다 더 많은 튜플이 반환되기 되므로, 정확히 몇개의 튜플에 대해서 limit, offset을 알 수 없기 때문에 막아둡니다. 강제로 페이징을 시킬 수는 있으나, 그럴 경우 JOIN FETCH한 모든 값을 메모리에 저장 후 페이징을 하는데, 모든 값을 메모리에 저장을 시키기 때문에 장애가 발생 할 수 있습니다.
V3_2: JOIN FETCH + @BatchSize/batch_fetch_size
API
@GetMapping("api/v3_2/collection-orders")
private Result ordersV3_2(@RequestParam(value = "offset", defaultValue = "0") int offset,
@RequestParam(value = "limit", defaultValue = "100") int limit) {
// /api/v3_2/collection-orders?offset=1&limit=1
List<Order> orders = orderRepository.findALlWithOrderMemberPaging(offset, limit); //ManyToOne, OneToOne 관계 모두 JOIN FETCH && Paging
List<OrderCollectionDTO> orderDTOS = orders.stream()
.map(o -> new OrderCollectionDTO(o))
return new Result(orderDTOS);
}findALlWithOrderMemberPaging(offset, limit)
public List<Order> findALlWithOrderMemberPaging(int offset, int limit) {
String query = "select o from Order o" +
" join fetch o.member m" +
" join fetch o.delivery d";
return em.createQuery(query, Order.class)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}ManyToOne, OneToOne 일때는 JOIN FETCH를 해도 엔티티에 저장된 튜플의 수 이상으로 결과 갯수가 나올 수 없기 때문에 페이징이 가능합니다. 그렇기 때문에, 페이징을 해야될 경우 ManyToOne, OneToOne 연관관계에 있는 엔티티들을 JOIN FETCH하고 페이징을 합니다.
하지만, 페이징을 할 경우, OneToMany 관계에 있는 값들은 JOIN FETCH를 할 수 없기 때문에, batch_fetch_size/@BatchSize 를 사용해서 성능 최적화를 합니다.
이럴 경우, 실제 처리되는 쿼리문은 V3_1보다는 많지만, DB를 접근하는 횟수는 1번에 끝낼 수 있기 때문에 성능 최적화가 됩니다. V2에서는 1+5N 만큼 DB를 접근하고, V3_1에서는 1번, 그리고 V3_2에서는 1+1 만큼 접근합니다./** * (쿼리문) * 1. select order0_.order_id as order_id1_9_0_, member1_.member_id as member_i1_6_1_, delivery2_.delivery_id as delivery1_4_2_, order0_.member_id as member_i4_9_0_, order0_.order_date as order_da2_9_0_, order0_.status as status3_9_0_, member1_.city as city2_6_1_, member1_.street as street3_6_1_, member1_.zipcode as zipcode4_6_1_, member1_.username as username5_6_1_, delivery2_.city as city2_4_2_, delivery2_.street as street3_4_2_, delivery2_.zipcode as zipcode4_4_2_, delivery2_.order_id as order_id6_4_2_, delivery2_.status as status5_4_2_ from orders order0_ * inner join member member1_ on order0_.member_id=member1_.member_id * inner join delivery delivery2_ on order0_.order_id=delivery2_.order_id limit ? * * 2. select orderitems0_.order_id as order_id5_8_1_, orderitems0_.order_item_id as order_it1_8_1_, orderitems0_.order_item_id as order_it1_8_0_, orderitems0_.count as count2_8_0_, orderitems0_.item_id as item_id4_8_0_, orderitems0_.order_id as order_id5_8_0_, orderitems0_.order_price as order_pr3_8_0_ from order_item orderitems0_ where orderitems0_.order_id * in (?, ?) * * 3. select item0_.item_id as item_id2_5_0_, item0_.name as name3_5_0_, item0_.price as price4_5_0_, item0_.quantity as quantity5_5_0_, item0_1_.artist as artist1_0_0_, item0_1_.etc as etc2_0_0_, item0_2_.author as author1_1_0_, item0_2_.isbn as isbn2_1_0_, item0_3_.actor as actor1_7_0_, item0_3_.director as director2_7_0_, item0_.dtype as dtype1_5_0_ from item item0_ left outer join album item0_1_ on item0_.item_id=item0_1_.item_id * left outer join book item0_2_ on item0_.item_id=item0_2_.item_id * left outer join movie item0_3_ on item0_.item_id=item0_3_.item_id where item0_.item_id * in (?, ?, ?, ?) * * batch_fetch_size를 설정했기 때문에 2번과 3번 쿼리문에서 in()이 처리됩니다 */
- applicatin.yml에서
spring: jpa: properties: hibernate: default_batch_fetch_size: 100OR
2. @BatchSize(size = 100)
두가지 방법으로 설정 가능하며, 필요에 따라 각각 size 값을 변경하면 됩니다.
보통 size는 100~1000의 값 중 선택 하는 것을 권장합니다. Size의 값과 상관 없이 클라이언트에서 메모리 사용량은 같지만, 값이 너무 크면 DB에서 순간 부하가 걸릴 수 있기 때문에 값을 조정하면 됩니다.
