Preview
-Title
Explainalbe Artificial Intellgence : understand, Visuallzing and interpreting Deep Learning Models
-Author
- Wojciech Samek
- Thomas Wiegand
- Klaus-Robert Muller
-Publication Information
arXiv, 2017.08
-Index Terms
- Artificial intelligence
- deep neural networks
- black box models
- interpretability
- sensitivity analysis
- layerwise relevance propagateon
-Objection
- XAI 분야의 동향 분석 요약(2017년), AI 해석 가능성 성능의 중요성 인식 제고
- Deep Learning model의 prediction을 설명하는 두 가지 접근 방식을 제시, 3가지의 Classification Task 평가
Background
AI 기술은 사용자에게 분류, 추천, 예측 등의 정보를 제공하며 광범위한 분야에서 다양한 용도로 활용 중
하지만, AI 기술은 Algorithm Complexity(알고리즘 복잡성)으로 인해 Black box 특성이 존재, 도출 과정과 도출한 최종 결과에 대한 타당성을 제공하지 못하는 한계점이 존재
Black Box 특성 : Input data에 대해 어떠한 정보가 어떠한 과정을 거쳐 결과에 어떠한 영향을 주었는지 명확히 파악할 수 없는 특성- AlphaGo가 '왜 해당 지점에 바둑돌을 두었는가?'에 대한 의문
- AlphaGo의 접근법 성공에 대한 논리적 근거 부족성, 결정 과정을 이해하거나 검증할 수 없는 이슈 제기
Deep Learning Model의 경우 우수한 성능을 보였지만 model의 복잡한 비선형 구조로 인해 데이터 차원에서 그 요인을 파악하는 것은 어려움. 따라서, 결과에 따른 원인을 파악할 수 없어 투명성, 타당성 부족에 대한 문제가 야기
이러한 문제 해결을 위해 Deep Learning Model이 판단한 과정과 판단 근거의 투명성, 타당성을 부여하고자 하는 'XAI(설명 가능한 AI)' 기술 필요성 제기
XAI(Explainable Artificial Intelligence)
AI 결과에 대한 인과관계를 분석하여 근거와 타당성 제시, AI의 행위와 판단을 사람이 이해할 수 있는 형태로 설명할 수 있는 기술 AI model 설명성(ExPlainability)
해석성(Interpretability) : system 구조를 이해 가능한 수준으로 설명
정확성(Completeness) : system 동작 원리를 정확한 방법으로 설명
XAI의 의미 변화
| year | description |
|---|---|
| 1975년 | ✔️설명 가능한 의사 결정 체계 ✔️전문가 시스템에서 컴퓨터의 의사결정 과정을 확인하는 연구 |
| 2004년 | ✔️설명 가능한 인공지능 'XAI'라 명칭(반 렌트, 피셔, 만쿠소 ✔️컴퓨터와 AI System의 복잡성 증가, 그에 반해 자기 설명 기능에는 발전이 미비 ✔️군대의 모의 전투 프로그램 속 NPC 인공지능을 개조하여 행동 이유 설명 아키텍처 제안 |
| 2010년대 초 | ✔️계산력을 비롯한 물리적 한계가 존재, 인공지능을 통한 문제 해결에 집중 |
| 2017 | ✔️H/W의 발전으로 데이터 처리 수준 향상으로 인한 Big data 유용성 증가 ✔️기계가 학습하는 Feature 양의 증가로 인한 의사 결정 분기점 증가 ✔️AI Model이 특정 결론을 내리기까지 설명 가능성을 추가하는 기법에 조명 |
 |
|---|
| Explainable AI – What Are We Trying To Do?, DARPA |
| DARPA : ARPA(Advanced Research Project Agency) – 군사 기술 개발 D = Defense, 방어 정책에 초점 2016년 문서번호 BBA-16-53, XAI(Explainable Artificial Intelliegence) |
DARPA에서 제시하는 XAI의 목적
- Model Complexity를 감소
- System output 신뢰 가능
- 의사 결정을 위해 AI Model 활용 가능
DARPA에서 제시하는 XAI의 3가지 과정
- 기존 ML Model에 설명 가능한 기능 추가
- ML Model에 HCI(Human Computer Interaction)
- XAI를 통한 현재 상황 개선
XAI의 이점과 한계점
| 이점 | 한계점 |
|---|---|
| ✔️새로운 Insight ✔️AI 연구원들에게 개선 방향 제시, 비 전문가들과 소통하기 위한 수단 ✔️비 전문가들에겐 AI를 신뢰할 수 있는 근거 | ✔️정확도가 낮은 AI Model에 적용 시 역효과 야기 ✔️XAI를 지원하는 각기 다른 Method의 상충되는 결과 도출 ✔️Data Scientist 역량에 따른 성능 차이 |
why do we need Explainable AI
- Verification of the system
✔️ AI Model 적용 분야의 전문가에 의해 검증 가능
✔️ data domaim에 대한 이해가 부족한 상태에서 개발된 model은 잘못된 결론에 도달할 가능성이 존재 - Improvement of the system
✔️ Model의 취약점을 파악하여 개선 방안 모색, 다른 model과의 비교 분석
✔️ Model의 성능 저하 요소를 파악하여 data processing, 활성 함수 변경 등 효과적인 개선 방안 도출 가능 - Learning from the system
✔️ AI model이 새로운 Insight 제공 가능
✔️ black box model의 결과 예측뿐만 아니라 숨겨진 법칙을 발견 이를 사람이 습득 가능 - Compliance to legislation
✔️ 법적 질문과 그 결정 이유에 대한 투명한 근거 필요
✔️ EU '설명권(right to explanation)'에 대한 규정, 사용자가 자신에 대한 알고리즘적 결정에 대한 설명을 요청할 수 있는 권리
METHODS for XAI
- Sensitivity Analysis(SA)
- Layer-Wise Relevance Propagation(LRP)
- LIME
- Decision trees
- Deep Taylor Decomposition
- DeepLift
- KT-method
- Validity Internal analysis위와 같은 다양항 방법으로 AI를 설명하는 연구가 진행 중
본 논문에서는 SA와 LRP 방법을 설명 및 실험 결과를 제시
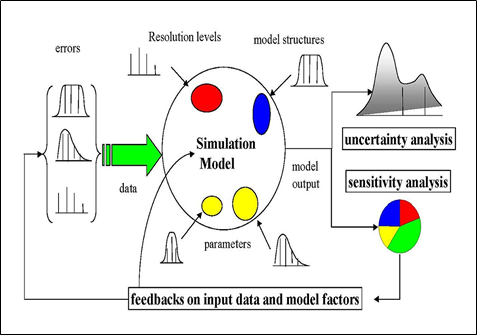
SA(Sensitivity Analysis)
통계, 경여 분야에서 사용되는 방법으로 타당성 평가 과정에서 사용된 변수를 변화시켜 최종적인 결과가 예측치 못한 상황 변화에 대한 예상을 할 수 있도록 하는 방법
XAI :
- How much do changes in each Variables affect the prediction
입력 변화에 대한 예측 결과의 변화량을 정량화하여 입력 이미지의 어떤 부분이 딥러닝 모델의 결과도출에 큰 영향을 미쳤는지에 대한 설명 (the most Sensitive Variables = the most relevant input Variables)를 전제
- Input Variables 𝑖 Importance 𝑅_𝑖
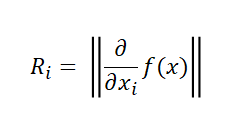
✔️ SA Heatmap에는 결과에 민감한 영향을 끼친 입력 값만을 확인가능하고 중요도를 나타내지는 못함
LRP (Layer Wise Relevance Propagation)
XAI : How much dose each Variables contribute to prediction
예측 결과로부터 역전파 형태로 신경망의 각 레이어별 기여도를 측정할 수 있는 방법, 딥러닝 모델의 부분 모듈인 각 레이어의 기여도를 Heatmap 형태로 시각화하여 직관적 이해 가능

-
Layer-Wise : 레이어 단위로
-
Relevance : 결과에 영향을 주는 관련성을 구하는
-
Propagation : 역전파 기술
-
Keep total relevance score by layer

-
Calculation relevance score 𝑅_𝑖

✔️ FFNN, LSTM, Fisher Vector Classifiers framework를 사용하며 최대 불확실성 대비 예측에 관한 상대적인 수치로 설명
Evaluation the quality of explanations
Deep Learning model을 설명하기 위해 많은 방법들이 존재하나 이러한 방법들의 설명력을 비교하기 위해서는 설명의 품질(quality)에 대한 객관적인 측정이 필요
Gradient, SmoothGrad 등과 같은 방법들의 heatmap 결과와 Edge Detector(model의 input value, train과는 연관이 없음)의 heatmap 결과를 비교하였을때 차이가 크지 않음을 확인 가능
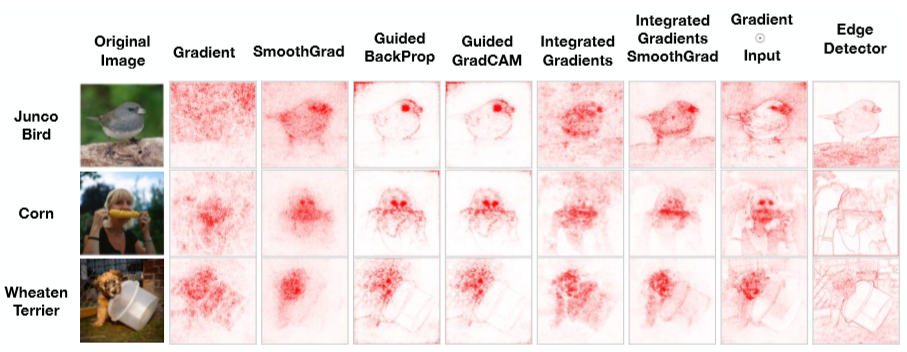 |
|---|
| < Sanity checks for saliency maps > |
시각적 자료(heatmap)만으로는 model의 설명력을 판단하기에 역부족
본 논문에서는 섭동 이론(perturbation theory)에 기초한 quality 측정 방법을 제안
섭동 이론 : 정확한 해가 잘 알려진 어떤 계에 미세한 변화를 줬을 때 그 해가 어떻게 변화하는지를 수학적으로 풀어내기 위한 도구인데, 특별한 경우가 아니면 보통 양자역학에서의 섭동 이론을 지칭해당 방법은 다음의 3가지 조건을 기반
- perturbation of input variables which are highly important > the perturbation of input dimensions which are of lesser importance
예측에 매우 중요한 입력 변수의 perturbation은 덜 중요한 입력 변수들의 perturbation보다 큼
그렇기 때문에 중요한 입력 변수의 미세변화가 일어날수록 예측 점수가 더 급격하게 감소
- SA와 LRP와 같은 설명 방법은 모든 입력 변수에 점수를 제공 따라서 제공된 관련성 점수에 따라 입력 변수를 정렬 가능
- 입력 변수를 가장 관련성이 높은 변수부터 시작하여 반복적으로 변화(본 논문에서는 삭제)시켜, 모든 변화 단계 후에 예측 점수를 확인, 예측 점수(정확도)가 감소가 크게 감소하는 것은 관련성이 높은 입력 변수를 식별하였음을 의미
(1) SA와 LRP와 각 설명 방법을 통해 입력 변수 점수 계산
(2) 점수가 높은 상위 변수로부터 k번째 입력 변수를 선택
(3) random noise를 주고 예측 점수를 확인한 뒤
(4) 이를 통해 관련성이 높은 변수를 찾고 예측 점수의 변화폭을 확인
EVALUATING THE QUALITY OF EXPLANATIONS
Image Classification
- 실험 환경

 |
|---|
| <'Volcano', 'Coffee cup' heatmap to SA, LRP> |
 |
|---|
✔️ SA Heatmap : 민감한 입력 변수를 보여주지만 해당 그림이 결과값에 어떻게 반영되었는지 알아보기는 어려움
✔️ LRP Heatmap : 화산의 경사면과 컵의 원 모형을 인지했음을 알 수 있음
✔️ Heatmap과 Perturbations 그래프를 참고 하였을때, LRP가 SA보다 이미지 식별 부분에서 더 나은 설명력을 제공
Text Document Classifiation
- 실험 환경

 |
|---|
| <sci.med file heatmap to SA, LRP> |
 |
|---|
✔️ 두 방법 모두 'body', 'discomfort', 'sickness' 단어를 핵심 단어로 구별
✔️ SA Heatmap : 문서 분류에 긍정적 영향을 준 단어와 부정적 영향을 준 단어를 구별 불가능
✔️ LRP Heatmap : 문서 분류에 긍정적, 부정적 영향을 끼치는 단어 구별 가능
✔️ Heatmap과 Perturbations 그래프를 참고 하였을때, LRP가 SA보다 이미지 식별 부분에서 더 나은 설명력을 제공
Human Action Recognition in Video
- 실험 환경

 |
|---|
✔️ LRP heatmap과 관련성 분포를 통해 비디오의 frame 내에서 관련 동작이 발생한 위치를 시각화하며 관련 동장이 발생하는 시점을 파악
Conclusion
- 다양한 분야에서 AI model이 뛰어난 성능을 보여주고 있지만 'Black box' 특성으로 인해 몇몇의 분야에서는 활용이 제한
- AI model에 설명력을 부여하는 XAI 기술의 필요성이 증가
- 설명 가능성은 AI model의 취약점과 편향된 data 발견, 효과적인 model 개선, 새로운 insight 제공, 법규 준수 근거 제공 등 효과 기대
- 2가지 XAI 제공 방법(SA, LRP)을 소개하고 해당 방법을 3가지 과제에 적용 실험한 결과를 제공
- 본 논문에서는 SA보다 LRP 방법이 더 좋은 설명력을 제공하였음을 제시
