DP (Data Parallel)
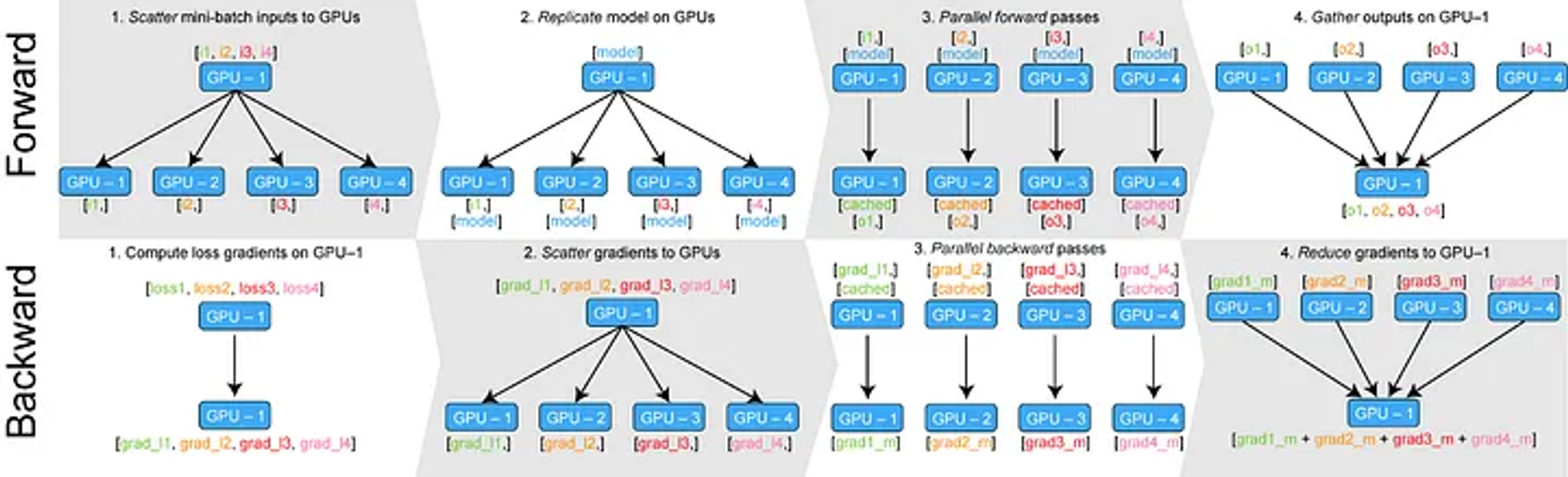
- 멀티 스레딩에 기반해 데이터를 분할하고 연산 결과를 취합해 업데이트하는 방식
- 수행 과정
- 입력 데이터와 모델의 파라미터를 각 GPU에 전달
- 역전파 과정에서 각 GPU에 전달된 데이터와 관련된 gradient를 분할 전달
- 모든 gradient를 모아 업데이트
- 멀티 프로세스가 아닌 멀티 스레드라 모델 업데이트는 첫 번째 GPU에서만 수행
- 사용하는 GPU의 전체 개수가 늘어날 수록 첫 번째 GPU에 걸리는 bottleneck이 커질 수 밖에 없는 구조
- 한 device에서 업데이트가 진행된 모델은 매 스텝마다 다른 device로 복제되어야 함
- Gradient를 모으지 않아도 각 GPU에서 자체적으로 step()을 수행한다면 해결됨
DDP (Distributed Data Parallel)
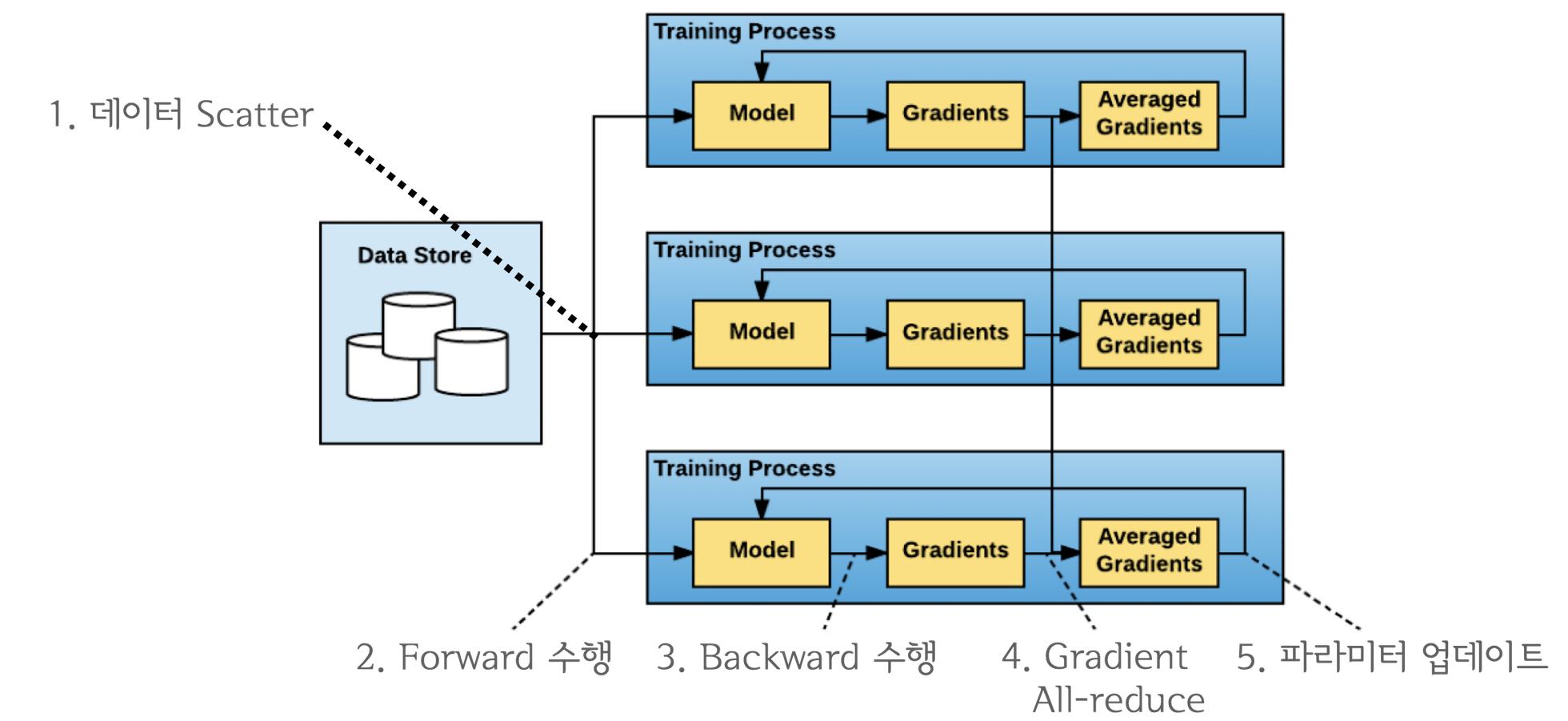
- DP의 단점들을 극복하기 위해 멀티 프로세스 기반으로 각 GPU에서 step을 수행할 수 있도록 만든 data parallel 기법
- DP처럼 마스터 프로세스를 두는 reduce + broadcast 방식은 마스터 프로세스의 부하가 심하고,
모든 프로세스가 서로 1번씩 통신하는 all-to-all 방식은 발생하는 통신량이 너무 많음
- 2017년 바이두 연구진이 개발한 ring-all-reduce 방식을 사용
FSDP (Fully Sharded Data Parallel)
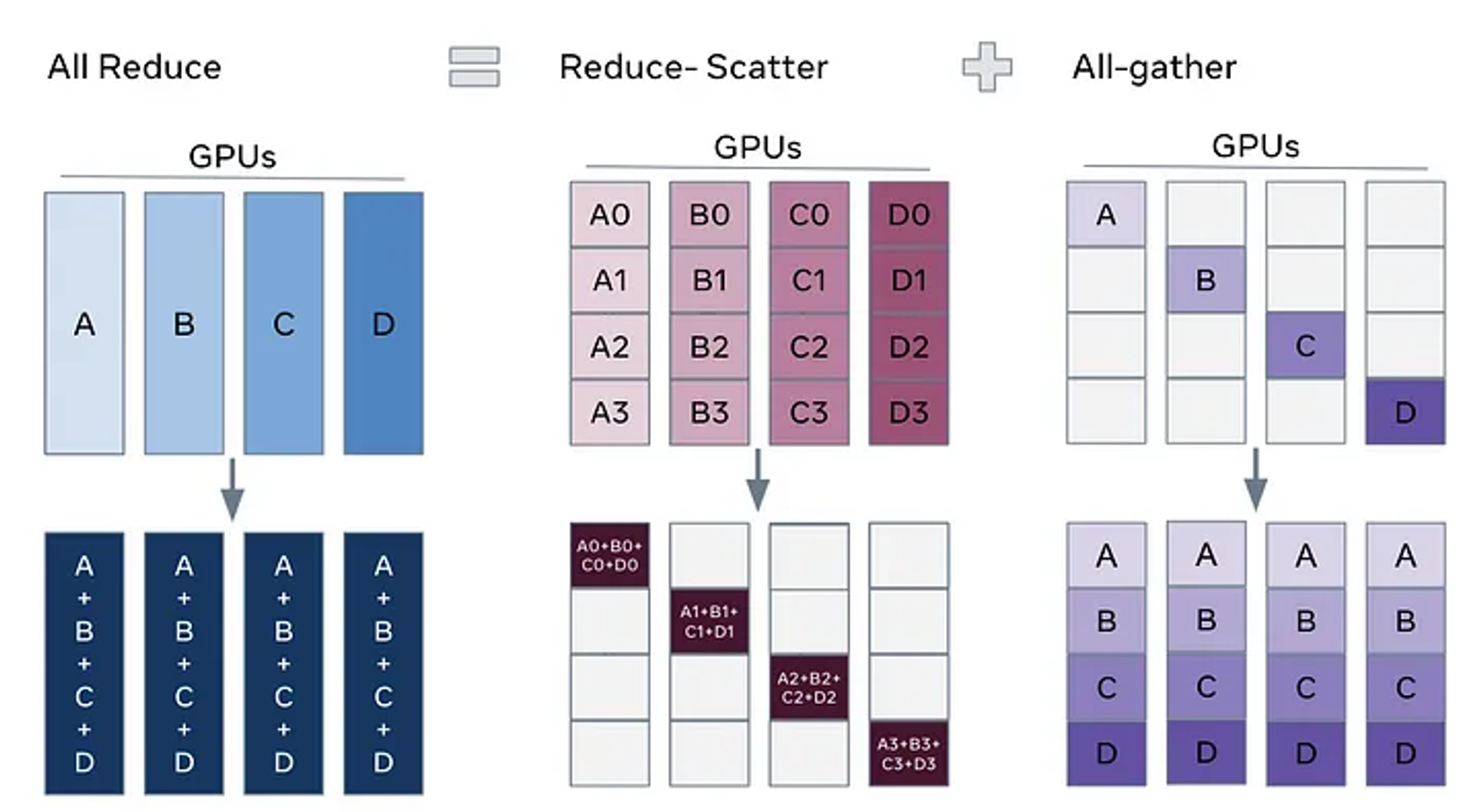
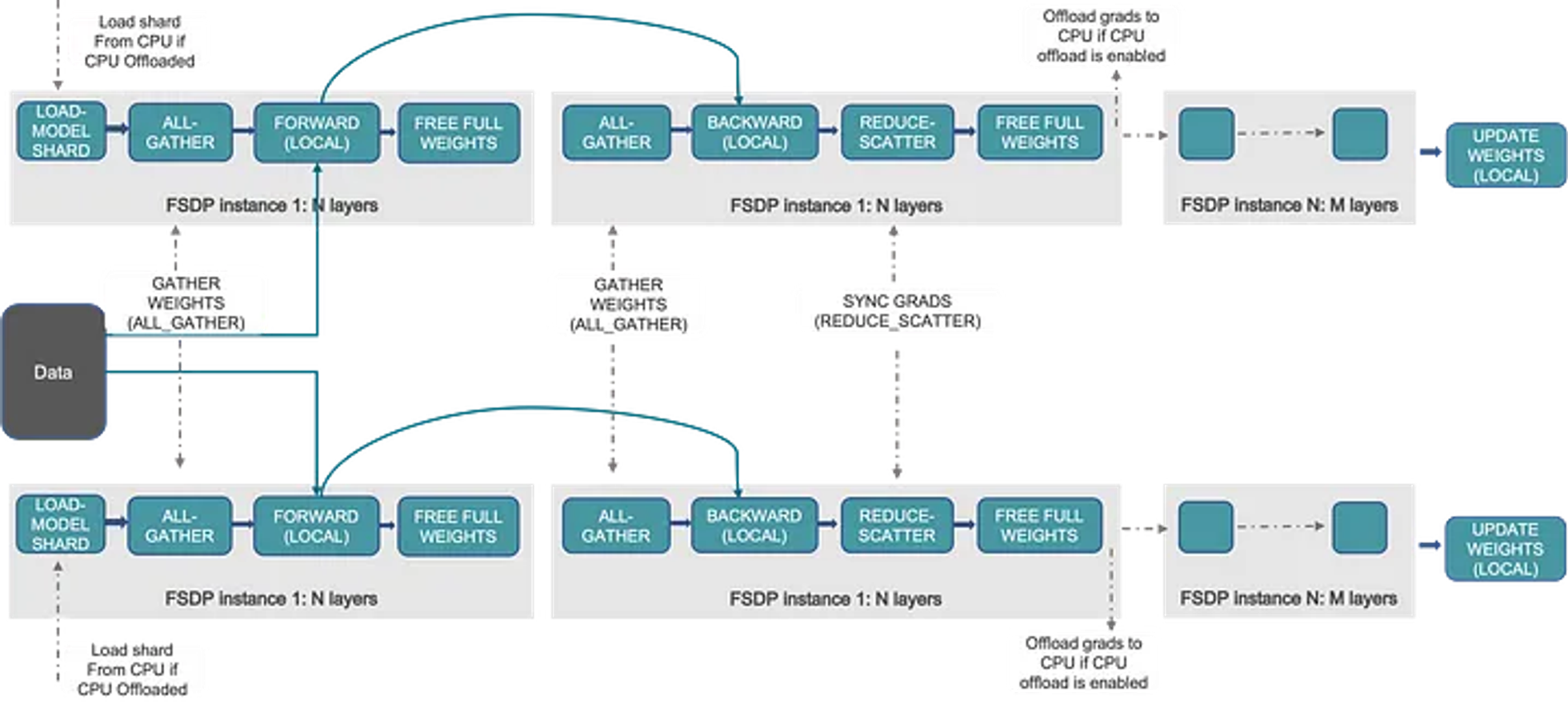
- DP나 DDP에서는 기본적으로 모든 GPU에 하나의 전체 모델이 동일하게 복사되어 있음
- 반면 FSDP는 모델의 정보 자체가 여러 GPU에 분산(sharded)되어 있음 (즉, model parallel)
- 순전파 과정에서 모델의 각 layer를 통과할 때마다 다른 GPU에 저장된 파라미터를 가져와서 사용하고 제거 (all-gather 연산)
- 이후 역전파 시 gradient를 계산하기 위해 또 다시 all-gather 연산을 수행하고, 각 GPU에서 계산된 gradients를 원래 속해있던 GPU에 전달 (reduce-scatter 연산)
- 최종적으로 각 GPU에는 원래 갖고 있던 모델에 대한 gradient만 남아있고, 이를 optimizer의 step() 연산으로 업데이트
요약
-
Data Parallel (multi-thread):
모든 GPU에 모델 복사
→ 각 GPU에서 gradient 계산
→ Gradient를 하나의 GPU에 모아 업데이트 -
Distributed Data Parallel (multi-process):
모든 GPU에 모델 복사
→ 각 GPU에서 gradient 계산
→ Averaged gradient를 통해 모든 GPU에서 각각 업데이트 -
Full-Sharded Data Parallel (multi-process):
모든 GPU에 모델 layer-sharding
→ 다른 GPU의 shard 정보를 임시 복사해 all-gather 연산으로 순전파
→ 다른 GPU의 shard 정보를 임시 복사해 all-gather 연산으로 역전파
→ 각 GPU에서 gradient 계산
→ Layer가 속해있던 원래의 GPU로 gradient를 전달해 reduce-scatter 연산
→ 각 GPU의 shard에 대한 gradient를 통해 모든 GPU에서 각각 업데이트

J의 틀에 몸을 녹여 맞추는 P