개요
- 잘 알려주는 곳은 없지만, GPU를 최대한 활용하는 것은 학습 파이프라인의 기본이자 시작
- 학습이 잘 된 모델이란 무엇인가?
- 모델의 성능을 판단하기 위해 사용하는 다양한 metric이 있지만, 이는 현존하는 모델들을 비교하기 위한 방법일 뿐 최고(literally “the best”)의 모델을 찾는 방법은 아님
- 해집합은 매우 복잡한 고차원 공간이며, 수많은 local minimum이 존재하고, 최적해를 찾는다는 것은 보장할 수 없음 → “우리의 모델은 최고가 아니다.”
- 최고의 모델을 찾는 확률을 높이는 방법은 단지 분석하고, 시도하고, 에러를 수정하는 것 뿐
- 계속 시도한다는 가정 하에, 시도 횟수를 높이려면?
- 한 번 모델을 학습 시키는데 들어가는 시간이 짧아야만 함
학습 파이프라인
- 딥러닝의 학습 파이프라인은 (1) CPU의 데이터와 (2) GPU의 학습으로 나누어짐
- GPU 유틸을 높이려면 둘 모두 최적화되어야 함 → 병목이 없어야 함
- CPU의 데이터 처리
- 디스크에서 데이터 읽기
- 전처리
- 배치 만들기
- GPU의 학습
- 순전파
- 손실 계산
- 역전파
CPU의 데이터 처리
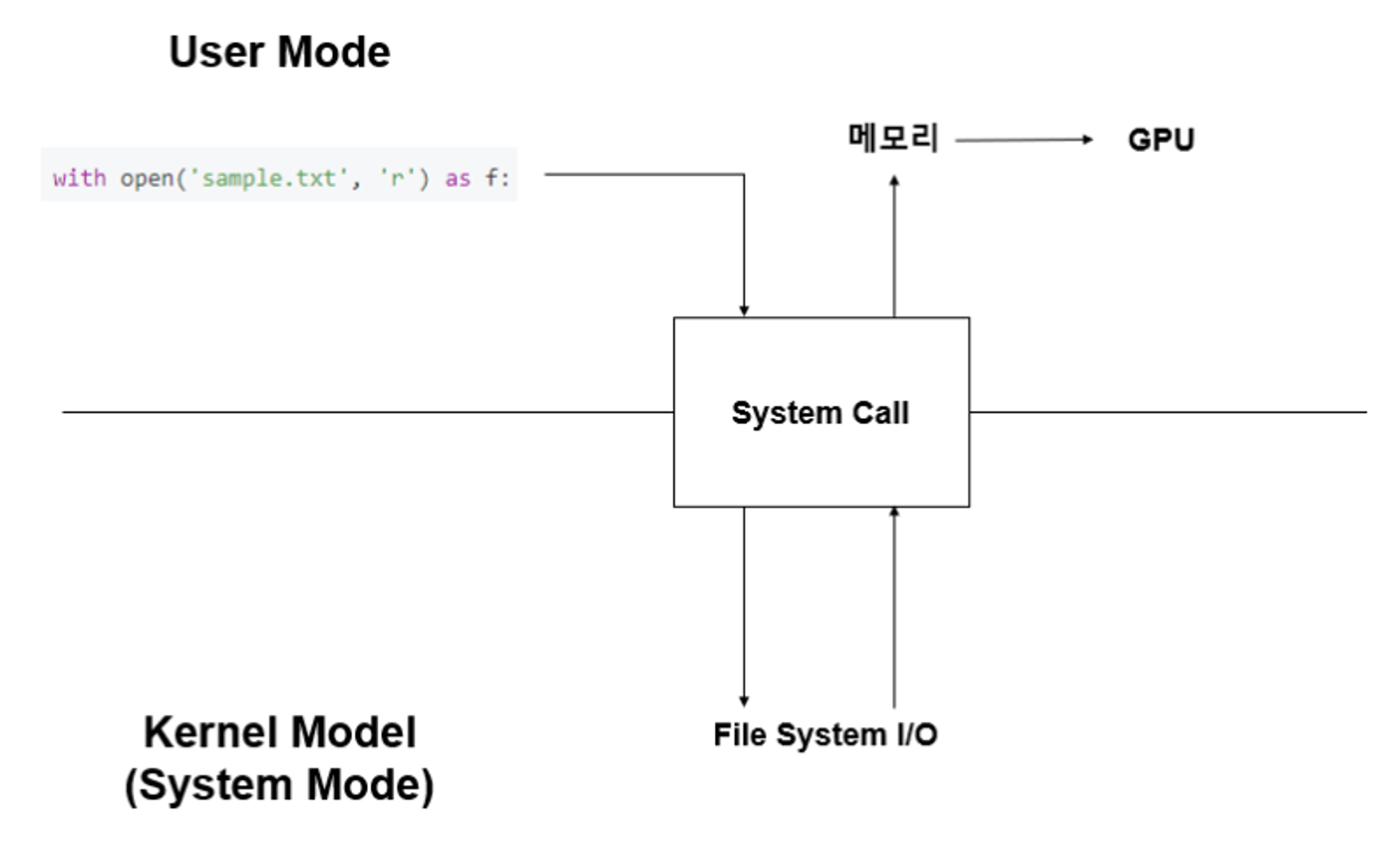
- CPU의 데이터는 위 과정을 거쳐 GPU로 올라가게 됨
- 데이터를 읽으라는 명령 받기 (User mode → Kernel mode / Context switching)
- Kernel mode에서 file system I/O에 디스크 내 해당하는 데이터를 반환해달라고 명령
- 반환된 데이터를 메모리에 올림 (Kernel mode → User mode / Context switching)
- 메모리의 데이터를 GPU에 올림
- 디스크에서 바로 데이터를 읽어오지 않고, file system I/O device가 디스크의 데이터를 읽어 CPU에 전달 → Kernel mode에서만 동작 가능
- 즉, 디스크의 데이터를 읽을 때 user mode와 kernel mode의 context switching 발생
- 이 때 사용하고자 하는 데이터 전부가 메모리에 올라갈 수도 있고, 올라가지 못 할 수도 있음
- 디스크에서 메모리로 데이터를 올리는 작업이 상대적으로 매우 느린 일이기 때문
- 즉, 데이터를 GPU에 올리는 과정에서 디스크 → 메모리 간 병목이 발생해 작업 속도가 감소할 확률이 높음
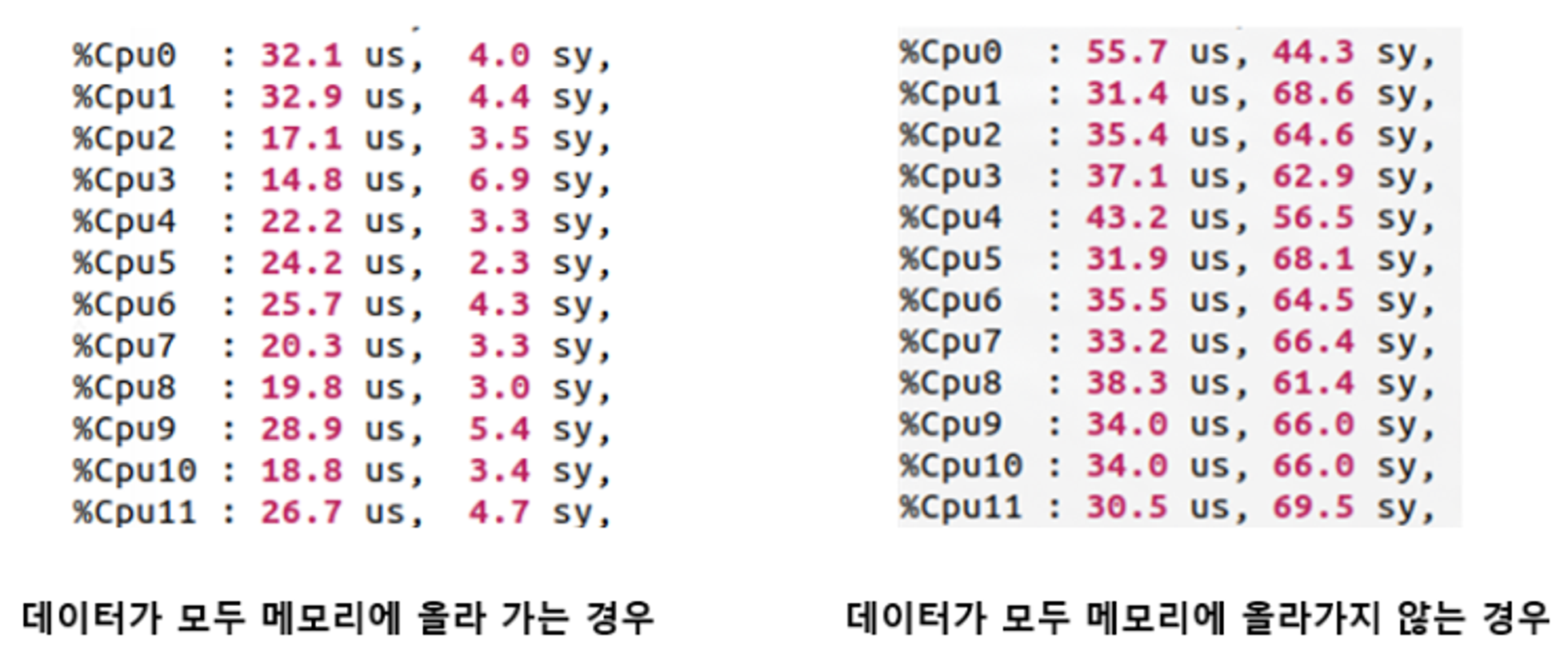
- 각 상황에서 CPU의 상태를 보면(us는 user mode, sy는 kernel mode에서 작업하는 비율), 데이터가 메모리에 한 번에 올라가지 않는 경우 디스크에서 계속 메모리에 데이터 일부분을 올려야 함
- CPU는 kernel mode에서 대부분의 시간을 보내게 되고, 데이터가 GPU에 빠르게 올라갈 수 없어 GPU 유틸이 떨어지게 됨
모델이 학습되는 과정
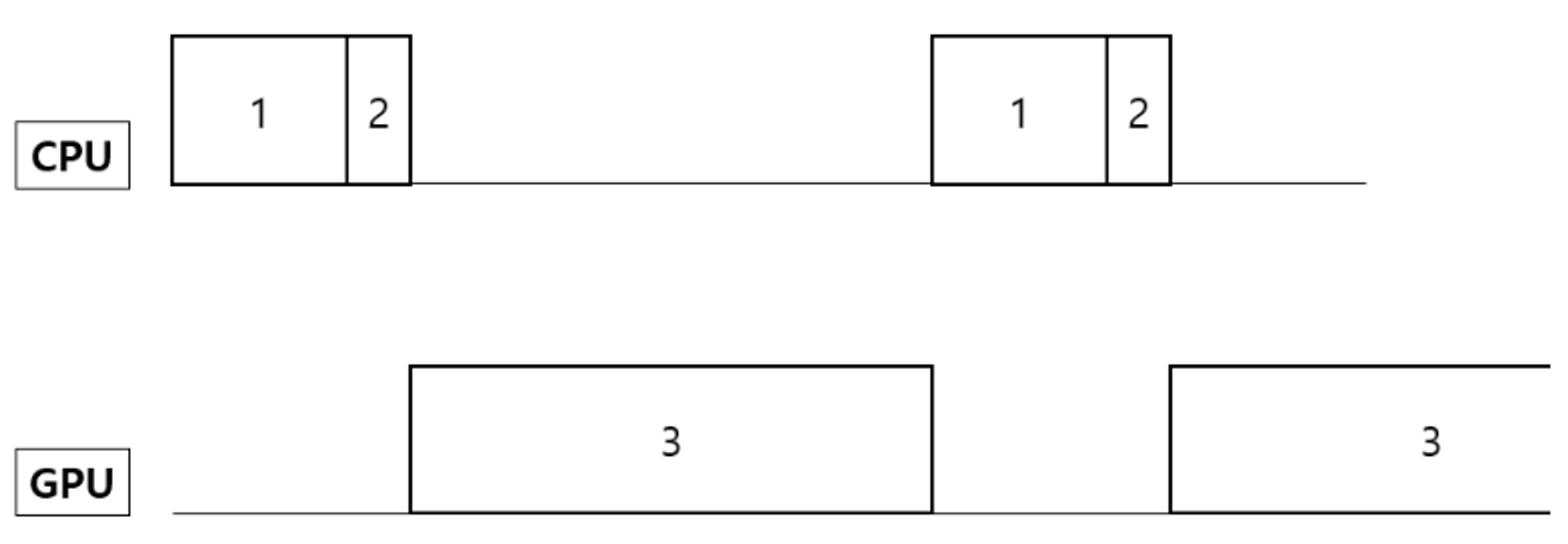
- 배치 학습은 위와 같은 방식으로 수행됨
- 디스크에서 메모리로 데이터를 올림
- CPU가 메모리에 올라간 데이터를 전처리하고 배치를 만듦
- GPU가 한 배치를 학습
- 메모리에 있는 배치를 GPU에 올리는 시간도 있으나 PCIe 통신은 15GB/s 정도로 매우 빠르기에 무시해도 될 정도
- 위 파이프라인대로만 학습을 수행하는 경우 GPU 유틸은 절대 99%를 찍을 수 없음
- 한 배치의 학습을 끝내고 다음 배치의 학습 전까지 1+2 과정의 시간 동안 지연이 발생
- 즉, GPU 유틸을 높이기 위해서는 한 가지만을 명심하면 됨
- GPU에서 한 배치의 학습이 끝나기 전까지 다음 배치를 메모리에 올려놓기
데이터 파이프라인 최적화
멀티 프로세스 데이터 로딩 (Prefetch)
- 1+2의 지연 시간은 단일 프로세스라서 발생하기 때문에, 한 코어가 한 배치를 준비하고 GPU에 올려 학습하는 동안 다른 코어가 다음 배치를 준비
- PyTorch의 DataLoader가 쉽게 지원함
from torch.utils.data.dataloader import DataLoader train_loader = DataLoader(dataset=train_set, num_workers=4, # 사용할 프로세스의 수 batch_size=512, persistent_workers=True)
작은 데이터 타입 사용
- 보통 이미지 데이터가 0~255의 UINT8 타입으로 표현이 가능하기에 사용이 원활함
- PyTorch의 기본 설정 상 모델 파라미터는 FP32이며, 단적으로 UINT8과 단순 비교해도 크기가 4배 더 큼
- 데이터를 UINT8로 가지고 있다가 모델에 입력하기 직전에 normalize하여 FP32로 변환해주는 것이 지연을 줄일 수 있음
- 다만 데이터가 한 번에 메모리에 올라가지 않는 경우에는 GPU 유틸이 99%까지 올라가지는 않음
Chunk Hit
- 디스크에서 메모리로 데이터를 올리는 것이 느리다면, 디스크의 데이터를 요청하는 횟수 자체를 줄이면 됨
- 데이터의 일부분을 메모리에 일단 올려놓는 것 → 이때 사용하는 것이 HDF5의 chunk
- HDF5(hierarchical data format 5)란 HDF 그룹에 의해 관리되는 대용량 데이터를 저장하기 위한 파일 형식
- 이름 그대로 계층 구조화된 배열 데이터를 저장하기에 용이
- 레이아웃이란 다차원의 데이터셋을 연속적 파일에 맵핑시키는 방법을 말하는데, HDF5에는 contiguous layout과 chunk layout이 있음
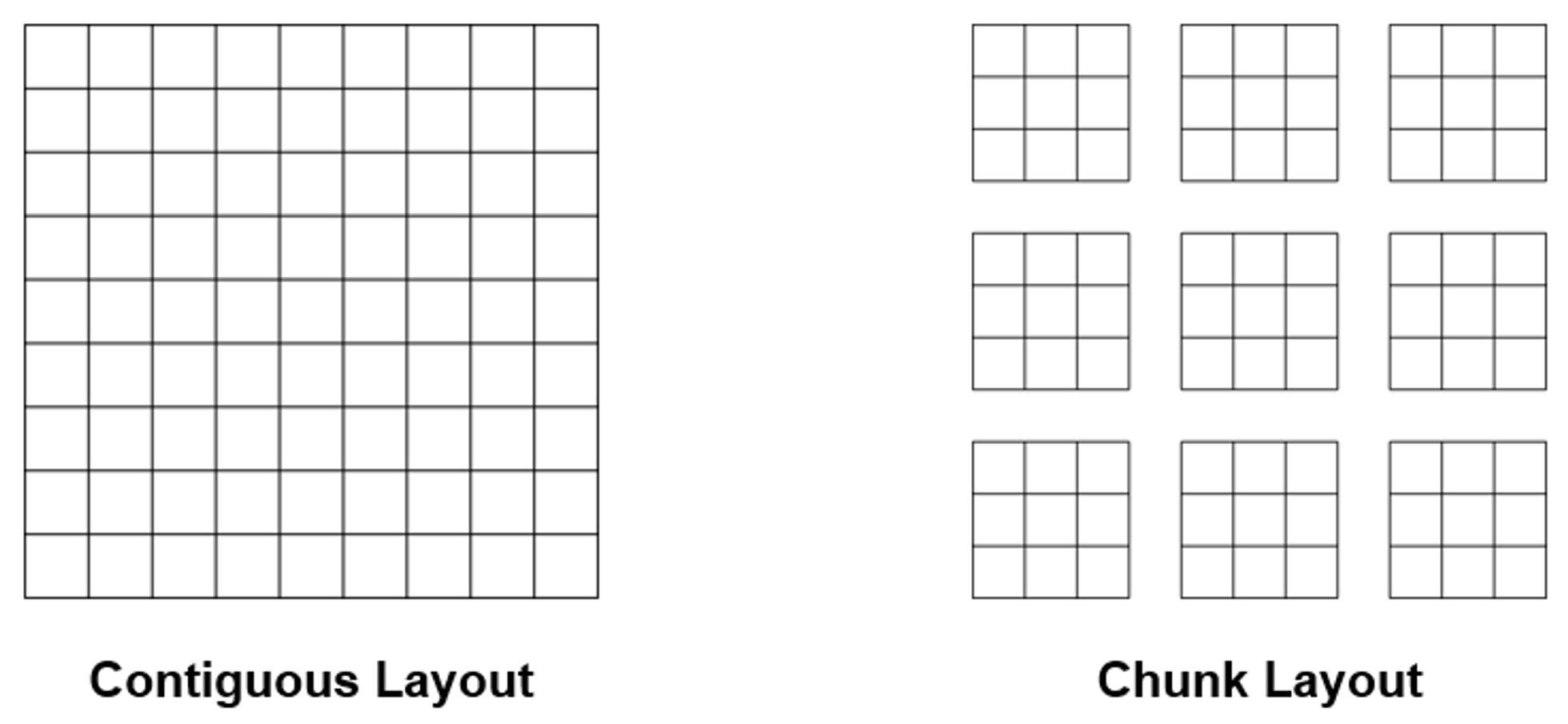
- Contiguous layout은 데이터셋을 일자로 펴서 하나의 덩어리로 디스크에 저장됨
- Chunk layout은 데이터셋을 여러 chunk로 나누어 파일 안에 한 블록이 무작위로 저장되며, chunk 별로 읽고 쓰는 것도 가능함
- 이러한 구조 특성이 GPU 유틸을 올리는데 중요한 이유는 다음과 같음
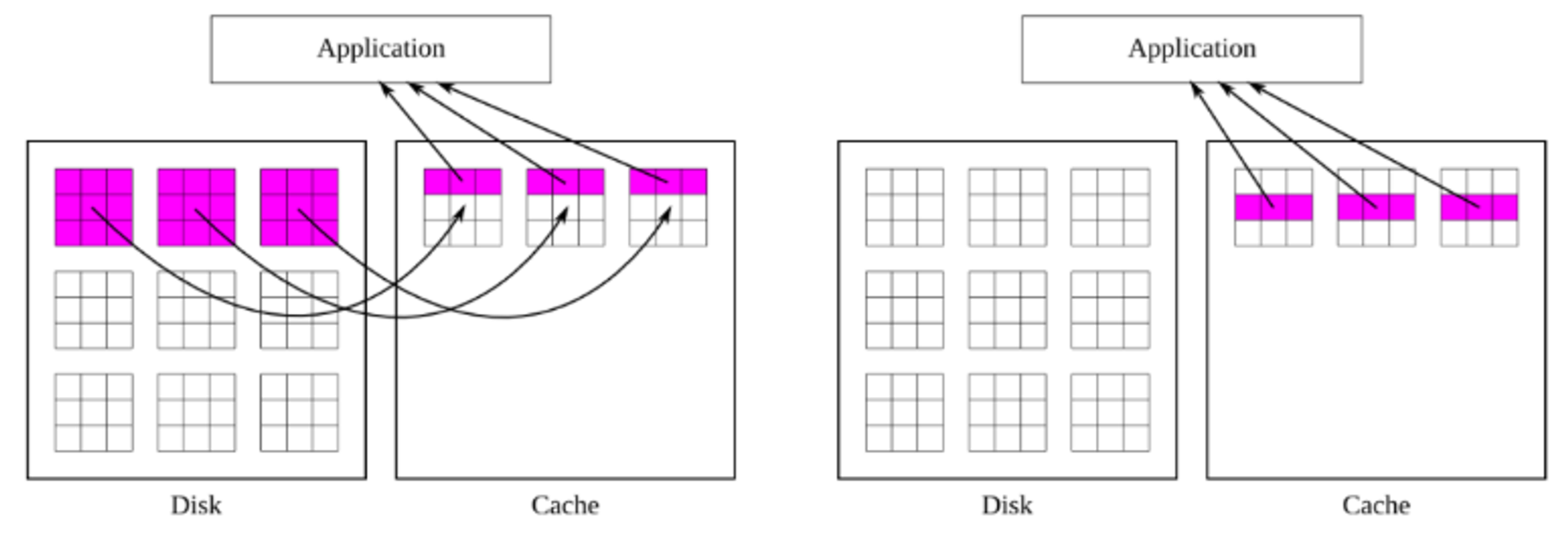
- Chunk에 있는 데이터 하나를 참조하면 해당 chunk 전체가 메모리에 올라감
- 이후 임의의 데이터를 참조했을 때 해당 데이터가 메모리에 이미 올라와 있는 chunk에 존재한다면 즉시 참조가 가능함
- 파이썬에서는 h5py로 HDF5 계층 구조의 데이터셋을 다룰 수 있음
import h5py celebA = h5py.File(DATA_DIR, 'w', rdcc_nslots=11213, rdcc_nbytes=1024**3, rdcc_w0=1) celebA.create_dataset('images', data=batch_images, dtype=np.uint8, chunks=(100, 3, 217, 178), # Chunk size는 11MB maxshape=(None, 3, 218, 178)) celebA.create_dataset('labels', data=labels_h5[:size], dtype=np.uint8, chunks=(20000, 0))
배치 에코잉 (Echoing)
- GPU에 올라와있는 하나의 배치를 여러 번 활용하는 것
- 학습의 randomness가 저해될 수 있는 방법이기 때문에 명백한 trade-off가 존재함
- 대신 다음과 같은 trick을 사용할 수 있음
- 512 배치를 GPU에 올려 256 배치 2개로 분할 (A0, B0)
- 모델이 A0, B0를 각각 학습
- 512 배치의 순서를 shuffle
- 섞인 512 배치를 다시 256 배치 2개로 분할 (A1, B1)
- 모델이 A1, B1을 각각 학습
결론
- 방법론들 보다 GPU 유틸이 떨어지는 원인이 무엇이고, 어떻게 해결할 수 있을지를 파악할 수 있으면 됨
- 속도 저하의 원인을 파악할 때 여러 도구를 사용할 수 있다는 사실을 알아둬야 하며, 무작정 원인 파악을 위해 달려들기 보다는 어떤 가설을 세워서 실험하듯 접근하는 편이 효율적임
- CPU 스탯을 확인할 수 있는 top, htop, atop 등을 사용할 수 있음

J의 틀에 몸을 녹여 맞추는 P