데이터베이스를 정리하기에 앞서, 데이터와 정보의 차이를 알아야한다.
데이터(data)는 분석을 거치기 전 단계의 재료로, 아직은 의미가 없는 것이고,
정보(information)는 데이터를 분석하거나 구조화한 의미있는 것이라 볼 수 있다.
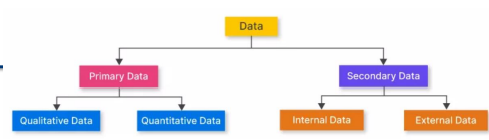
데이터의 종류
1. 1차자료(Primary Data)
-
연구자가 직접 수집한 원시 데이터
-
시간이 들고 비싸지만, 신뢰도가 높고 연구 목적에 맞는 정확한 데이터를 제공
질적 데이터 (Qualitative Data / Categorical Data) : 의견,묘사와 같이 글자 의존적 응답
양적 데이터 (Quantitative Data / Numerical Data) : 측정할 수 있고 통계적으로 분석할 수 있는 수를 사용한 데이터2. 2차자료(Secondary data)
-
기존에 다른사람이 수집하여 저장된 데이터
-
수집 비용과 시간이 절약되지만, 연구 목적과 완전히 일치하지 않을 수 있음.
내부 데이터 (internal Data) : 한 조직안에서 수집된 데이터
외부 데이터 (External Data) : 조직 밖에서 얻은 데이터
정보처리
날 것의 데이터로부터 의미있는 정보를 추출하는 과정(Raw Data -> Processed Information)
규칙1. 데이터 저장(Data Storage) :데이터베이스가 광대한 기본 데이터를 효율적으로 저장하는 것
규칙2. 데이터 검색(Data Retrieval) : SQL 같은 쿼리 언어를 사용하면 구조화된 데이터 검색이 가능하다.
규칙3. 데이터 집계(Data Aggregation) : SUM(),GROUP BY,AVG()은 대규모 데이터 세트를 요약하는데 도움이 된다.
데이터베이스(DB)
통합하고, 저장하고, 공유하고, 사용가능한 데이터의 모음

특징1. 데이터 중복 최소화 : ->효율적인 저장공간 확보
특징2. 데이터 일관성과 무결성 : 다중 작업사이에서도 데이터 정확성을 유지
특징3. 동시 제어 : 다수의 사용자가 충돌없이 같은 데이터에 접근
특징4. 확장성 : 많은 양의 데이터를 다루고, 작업량 증가에 적응한다.
특징5. 보안성과 접근 제어 : 사용자 인증과 규칙기반 접근 제어(RBAC/role-based access control)을 데이터 보호를 위해 제공
종류1. Structured Data (ex. MySQL,PostgreSQL)
- schema는 DB에 저장전에 정의되어 있어야 하고, 데이터 자체와 별도로 정의되기 때문에 일관성과 구성을 보장한다.
- 미리 정의된 규칙과 고정된 구조를 가짐
- 정의된 관계에 따라 표에 저장
- SQL(Structured Query Language)을 사용하면 쉽게 검색할 수 있다.
- schema에 따라, 콜론이나 데이터 타입, 제약이 정의될 수 있다.
- SELECT,JOIN,GROUP BY와 같은 작업을 사용하면, 효율적인 질의와 데이터 분석이 가능해진다.
종류2. Semi-Structured Data (ex. HTML,XML,Json files)
: 구조 데이터같은 엄격한 schema내부에 저장되는 것은 아니지만, 조직적인 데이터(tags,metadata)가 데이터 내부에 존재한다.
- 데이터에는 구조를 설명하는 metadata, marker가 포함된다.
- 의미있는 구조를 추출하기 위해서 parsing과정이 필요하다.
- 전통적인 관계 DB보다 파일기반 형식(file-based format)에 주로 저장된다.
- 데이터를 융통성있게 다룰 수 있는 MongoDB,Firebase,CouchDB와 같은 NoSQL안에 저장된다.
종류3. Unstructured Data (ex. 비디오,음성파일,텍스트 데이터,이메일 등)
: 사전 정의된 schema나 조직적인 format없이 저장되는 데이터.깔끔한 관계형 대ㅔ이터베이스에는 적절하지 않고 특별한 처리과정이 필요하다(store,retrieve,analyze)
- 정해져 있는 구조가 없음.
- 전통적인 도구를 이용해서 분석하기 힘듦.(big data,AI-based techniques)
- 많은 양을 저장하게 됨(이미지,비디오와 같은 고차원 데이터)
- 데이터 누수나 클라우드 저장소, 분산 데이터베이스와 같은 고급저장기술이 요구됨.
Q. Ustructured Data를 다루는 방법?
A1. NoSQL Databases-MongoDB,Cassandra
A2. Data Lakes -Hadoop,AWS S3
A3. AI & NLP
데이터 특성의 분류(통계학적으로 보았을 때)
Categorical Data(Nominal & Ordinal Data)
: 이산적인 카테고리나 무리로 분류될 수 있는 값. Qualitative data(질적)라고도 하며, 이산적인 계산이나 수를 비교하지 못함
- Nominal Data : 순위나 순서가 없는 데이터 (ex,성별, 혈액형등등)
- Ordinal Data : 의미있는 순위나 순서가 있지만 그 간격이 일정하지는 않는 데이터(ex. membership rankings(실버,골드,플래티넘))
Numerical Data(Discrete & Continuous Data)
:연산작업을 할 수 있고 측정할 수 있는 값들로 구성된 데이터.Quantitive data(양적)이라고도 함.
- Discrete Data: 셀 수 있는 데이터 (소비자 수, 시험을 통과한 사람 수 )
- Continous Data: 측정할 수 있는 데이터. 통계적 모델을 이용하여 분석할 수 있다. (ex. height,weight)
