데이터 베이스 디자인 6단계
이 단계는 데이터베이스를 현실 세계의 요구사항을 실제로 동작하는 DBMS로 옮기는 과정이다.
1. Requirements Analysis
- 사용자, 업무 담당자와 인터뷰를 통해 어떤 데이터를 관리해야 하는지, 어떤 기능이 필요한지를 조사한다.
- 무엇을 할 것인가를 정의하는 단계로, 이 단계의 결과는 "요구사항 명세서" 이다. 예를 들어 학생의 학번,이름, 소속 학과를 관리하는 표가 결과가 되는 것이다.
2. Conceptual Data Modeling
- 현실 세계의 데이터와 요구사항을 개념적 데이터 모델로 변환하는 단계이다. 보통 E-R Diagram을 사용하고 ER 모델을 만들게 된다.
3. Logical DB Design
개념적 모델인(ERD)를 DBMS 독립적인 관계형 모델로 변환하고 테이블 구조를 설계하고, 정규화(Normalization)을 수행하는 단계이다. 그 결과 relation schema 집합이 완성된다.
4. Physical DB Design
하드웨어와 OS의 특성에 기반한 데이터의 물리적 구조를 고려하여 DB를 설계하는 단계이다. 인텍스(index), 뷰(view), 파티션, 접근 경로 등을 결정하여 성능, 저장공간 최적화를 고려하게 된다. DB는 DBMS안에서 SQL이 실행되면서 만들어지고, 이 단계의 결과물은 저장구조 명세서이다.
5. DB implementation
DBMS에 SQL을 이용하여 실제 데이터베이스를 생성하는 단계이다.
이 단계의 결과, 아래와 같은 실제 데이터베이스 스키마가 탄생하게 된다.
CREATE TABLE Student (
sid INT PRIMARY KEY,
name VARCHAR(50),
dept VARCHAR(50)
);
6. Testing & Quality Assurance
이 단계를 마치면 최종적으로 운영 중인 데이터 베이스가 완성된다.
Normalization
데이터 삽입, 업데이트, 삭제를 할때 불필요한 데이터 중복(Data Redundancy)으로 인해 예상치 못한 문제가 나타나는 것을 Anmaly라고 한다. 그래서 이러한 문제가 없도록 중복을 최소화하고 이상현상 제거를 목표로 하는 과정을 정규화(Normalization)이라고 한다. 정규화(Normalization)을 진행하는 정도를 Normal Form(NF)라고 하고, 1NF~6NF가 존재하지만 실제 실무에서는 3NF나 BCNF까지만 주로 사용한다.
목표: 기능적으로 관련이 있는 데이터끼리 묶어서 만들자!
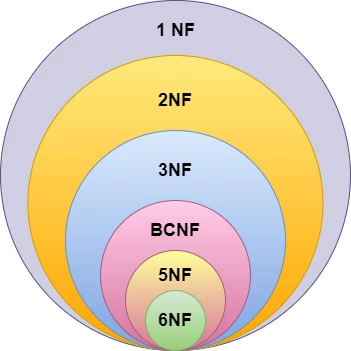
더 높은 정규화 과정일 수록 더적은 anomaly들을 가지게 되고 엄격해진다.(나누는 기준에따라 최종 테이블의 결과가 다를 수 있음)
1NF(First Normal Form)
: 모든 속성값이 원자값이어야 한다(원자성). 즉, 모든 열들은 하나의 값들만 가져야 하다는 말이다.
예를 들면 3행 1열에 happy라는 값과 sad라는 값이 같이 올 수 없다는 말.
2NF(Second Normal Form)
: 1NF를 만족하면서, 의존하고 있는 주요키(Primary Key) 별로 테이블 나누어야 한다(부분함수종속제거). 즉, 키의 일부분에만 종속되는 속성을 분리한다.
예를 들면 Enroll테이블에 sid, cid, sname, cname, grade Attribute값이 존재할 때, 기본 키가 sid,cid인데 sname이 side에만 종속된다면 부분함수 종속이 발생하는 것이다.
3NF(Third Normal Form)
: 2NF를 만족하면서, 주요키(Primary Key)가 아닌 것에 의존하고 있을 경우, 테이블 분리한다 (이행적 함수 종속 제거)
예를 들어 Student테이블에 sid,sname,dept,dept_phone_number값이 존재할 때, dept_phone_number은 dept에, dept는 sid에 종속된다면 dept를 기준으로 분리하면 된다.(dept_phone_number은 sid에 종속될 필요가 없기 때문)
BCNF(Boyce-Codd Normal Form)
:3NF를 만족하면서,모든 종속당하는 키가 SuperKey여야 한다.즉 후보 키가 여러 개일때 발생하는 문제를 해결한다.
예를 들어 Student테이블에 sid, sname, dept, dept_phone_number, dept_room이 존재할 때, 후보 키가 sid, dept_phone_number이라고 해보자. 그러면 부서dept는 후보키 sid,dept_phone_number에 의해 결정이 되는데 실제로는 dept가 dept_phone_number을 결정하게 된다. 그래서 BCNF를 만족시키려면, dept를 기준으로 테이블을 나누면 된다.
4NF(Fourth Normal Form)
:BCNF를 만족하면서, 다치 종속(Multivalued Dependency,MVD)을 제거한다. 즉 한 키에 여러 독립적인 다치 종속을 가지면 분리하게 된다.
예를 들어 Student테이블에 sid,sname,hobby,skill이라는 키가 있고 hobby와 sid가 종속, skill이 sid에 또 다시 종속되는 현상인 다치 종속을 가지게 되면 sid를 기준으로 한 테이블을 2개로 나누어야 한다.
//수정이 필요한 부분이 있다면 댓글로 알려주세요
