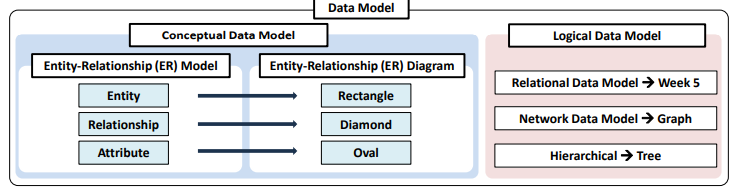
Data Modeling이란, 실제 세계의 데이터를 컴퓨터시스템 내부에 구조화된 데이터로 바꾸어 넣는 과정을 의미한다.
Data Modeling의 종류
1. Conceptual Data Modeling
"Key Element"
필수적인 실제 세계의 데이터를 추출하고, 이것을 개념적 표현으로 바꾸는 과정을 말한다.
저장소나 데이터 구조에서 어떠한 문제없이 key entities, attributes, relationships를 확인하는 것에 초점이 맞추어져 있다.
e.g. 실제 자동차의 특징을 개념적으로 정리한다.
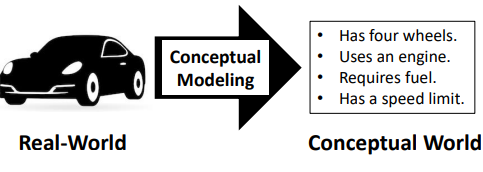
1.1 Conceptual Data Model
사람이 이해할 수 있는 방법으로 바꿈. 물리적인 저장소를 다룰 수 있는 최소한의 추상화가 존재한다.
e.g. E-R(Entity-Relationship) Model
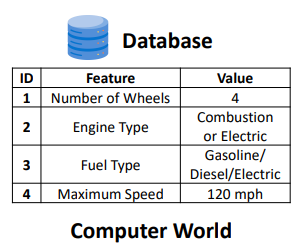
2. Logical Data Modeling
"tables, attributes, relationships"
개념적인 데이터를 데이터베이스에 저장할 수 있는 형태로 보여주는 것.
어떻게 데이터가 논리적으로 조직되어 있는지 tables, schemas, relationships을 통해 정의한다.
e.g. conceptual data를 데이터베이스의 논리적인 데이터로 추출하여 저장한다.
2.1 Logical Data Model
Conceptual Data Model을 데이터베이스가 실행할 수 있는 논리적인 구조로 바꾸는 것. 어떻게 데이터가 데이터베이스 내부에 저장되고, 구조화 되어있는지 묘사한다.
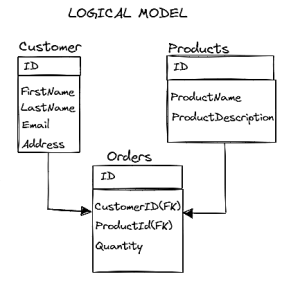
e.g. Relational Data Model
- 표 형식으로 데이터가 저장됨.
- 관계를 수립하기 위해 primary & foreign keys를 사용함.
Data Model의 구성요소
1. Data Structure
: 각각의 서로다른 데이터 모델들 내부에서 어떻게 데이터가 조직되는지를 정의함.
2. Operations on Data
데이터가 conceptual, logical 모델에서 어떻게 처리되는지 정의함.
CRUD operations
- Create
- Read
- Update
- Delete
3. Constraints(Ensuring Data Integrity)
목적: 데이터무결성과 일관성 유지
- Structural Constraints: 어떻게 데이터가 조직될 지 규칙을 정한다.
- Semantic Constranints: 무조건 적용을 해야하는 비즈니스 규칙을 지정한다.
중요한 이유
1) 데이터 정확성 보장
2) 의미있는 데이터 저장에 대한 규칙 시행
3) 다양한 작업에서 일관성 유지하는데 도움이 된다.
E-R Model (Entity-Relationship Model)
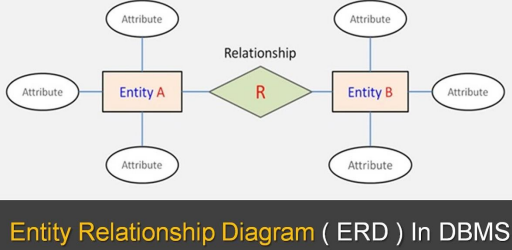
E-R Diagram (Entity-Relationship Diagram)
E-R model의 그래픽적 표현
Entity

조직을 위해 필수적이고 구별가능한 어떠한 것.(사람,물체,개념,이벤트 등등)
- Strong Entity: 독립적으로 존재함
- Weak Entity: 다른 Entity에 의존함.
Entity가 중요한 이유
- 데이터베이스의 기본을 정의함
- 구조화된 데이터저장소에서 쉽게 찾을 수 있게 함
- 효율적인 데이터베이스를 위한 관계 모델링에 도움을 줌
- Entity Type: 독특한 이름과 특성을 사용하여 entity를 정의하는 것.
- Entity Instance(Entity Occourence): 실제 속성 값을 갖는 entity의 현실 세계 발생.Entity
- Entity Set: 같은 entity 타입에 속해있는 entity instance의 집합체
Attribute

entity나 관계를 묘사하는 독특한 특성
Attribute가 중요한 이유
- 구조화된 포멧에서 entity의 특성을 정의함.
- 데이터 찾기와 조직화에 도움을 줌.
- 관계데이터 schemas 디자인을 가능하게 함.
1. Number of Values(Single/Multi-valued Attribute로 나뉨)
: 특성값의 갯수에 따라 나뉨.
- Multi-valued attributes는 이중 타원으로 그림
2. Divisibility of Meaning(Simple/Composite Attribute로 나뉨)
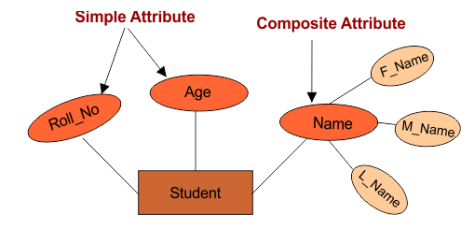
: 더 나누어질수 있는지 없는지에 따라 나뉨.
- **"Divisibility of Meaning"**이란? **Attribute 값이 더작고 의미있는 구성요소로 쪼개질 수 있는지**를 의미한다.
Q. 이 특성이 중요한 이유? A. single은 표의 개별 필드로 저장되지만, Composite은 쿼리성능을 위해 별도의 열이나 여러 필드가 필요할 수 있기 때문.
3. Dependency on Other Attributes

: 다른 속성에 별도로 저장되지 않고 다른 속성에서 값이 파생되는 속성. 데이터베이스에 따로 저장되지는 않지만, 필요할 때 계산될 수 있다.
- Derived Attribute: 점선 타원으로 표현됨.
Q. Derived Attribute가 중요한 이유 A1. 불필요한 계산값 저장을 피하기 때문에 **데이터 과잉을 줄임.** A2. 파생된 값은 항상 최신 데이터로 부터 계산되기 때문에 **일관성을 증가시킴** A3. 몇몇 계산은 저장하지 않고도 계산할 수 있기때문에 **쿼리 효율성을 증가시킴.** 꿀팁 -**성능최적화가 필요하다면, 자주사용하는 파생값을 테이블에 저장하자!**
4. Null Attribute
: Null값을 가지고 있는 특성
- Null값
: 알려지지 않았거나, 할당되지 않았거나,존재하지않는 값을 말한다. 일반적으로 말하는 빈문자열(""),숫자 0값과 다른 개념이다.Q. 왜 Null 값이 중요한가? A1. 놓치거나 알려지지않은 데이터를 나타낼 수 있기 때문 A2. 데이터 분석시 올바르지 않은 가정을 막을 수 있기 때문 A3. 쿼리에서 특별한 처리가 필요하기 때문.
5. Key Attribute
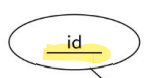
: 각각의 entity instance를 독특하게 구분하는데 사용되는 Attribute. 모든 entity instance들은 독특한 key attribute 값을 가지고 있다. 이는 하나 이상의 attribute로 구성될 수 있다.
- 이름 밑줄로 표시
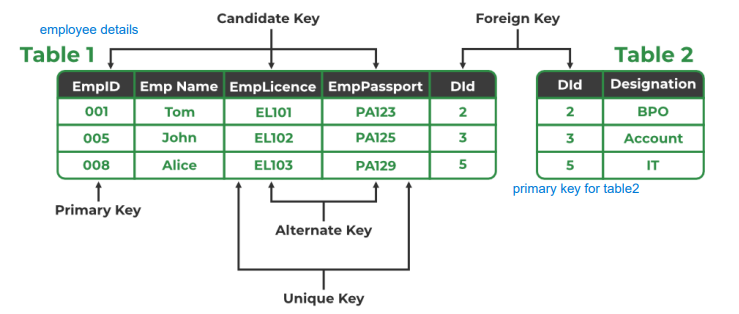
<key의 종류>

Q. 왜 Key Attribute 값이 중요한가? A1. 각각 entity instance의 독특함을 가능하게 한다 A2. DB안에서 indexing하고 값을 찾는 것을 효율적으로 할 수 있도록 한다. A3. 관계형 데이터베이스에서 서로 다른 테이블 간의 관계를 설정한다.
<key 예시>
Relationship
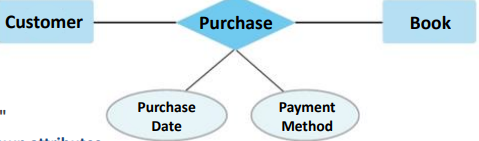
: 2개이상의 entites들 사이의 의미있는 연결.
relationship entity들은 각자 자신의 attribute를 가지고 있을 수 있다.
Q. 왜 Relatinoship이 중요한가? A1. 서로다른 entites사이에서 데이터 연결이 가능하게 한다. A2. 실제 세계의 연결을 데이터베이스 내부에서 정의하는 것을 돕는다. A3. 효율적인 querying과 데이터 찾기를 가능하게 한다.
모범사례 : 관계 데이터베이스 안에서 관계를 효율적으로 유지하기 위해 foreign key를 사용한다.
연결방식에 따른 분류
1. One-to-One(1:1) Relationship
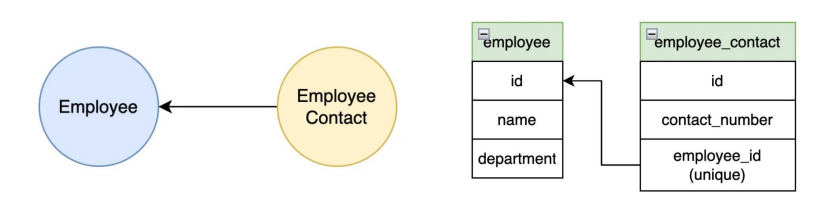
서로 다른 테이블에서 민감하거나 추가적인 데이터를 나눌때 유용하다.
Q. 1:1 relationship이 중요한 이유? A1. entity사이에서 독특한 관계를 가능하게 한다. A2. 접근성의 빈도에 따라 나눔으로써 데이터 과잉을 줄인다. A3. 민감한 정보를 나누어서 보안성을 높인다.
모범사례 성능이나 보안상의 이유로 entity에 선택사항이나, 민감한 세부 정보가 별도로 저장되어야 하는 경우에 사용하자!
2. One-to-Many(1:N) Relationship
주로 실제 세계 데이터 베이스에서 modeling transactions나 데이터 관계에서 주로 사용된다.
Q. 왜 1:N relationship이 중요한가?
A1. 계층적 관계에서 효율적인데이터 조직가능
A2. 관계 데이터 베이스에서 참조 무결성으 유지한다.
A3. 연결된 데이터에 대해 쿼리 성능이 최적화된다.
모범사례 : foreign key를 1:N 관계를 수립하기 위해 사용하자!
3. Many-to-Many(M:N) Relationship <미완성>
