🗺️ HashMap
💡
HashMapis an implementation of aHash Tabledata structureinJavawhere the data can be stored in thekey-valuestructure. Eachkeyis unique, andvaluesare associated with specifickeys.
HashMap, theoretically, ensures constant time O(1) operations specifically on basic add, remove, and get operations. HashMap being able to offer constant time O(1) operations, thereby being the most efficient data structure in the Java Collections Framework was a foundational reason why HashMap was preferred over other Collections.
HashMap Class in Java, however, sometimes fails to achieve constant time complexities O(1) on basic operations implying that understanding the underlying mechanisms of the HashMap Class may be important.
🗺️🔍 HashMap Class (behind the scene)
💡
HashMap Classis anarrayofNode objects, where, if necessary, multiplekey-valuepairs can be stored at the sameindexby forming aLinkedList.
An index is determined through the mathematical calculation underneath:
index = (n - 1) & hash
where the index is simply a remainder of the key's hashcode, divided by the map array's size, n. Each index is termed as a bucket named after a container that holds multiple items.
Given the above index determination mechanism, a hash collision could occur where the two or more keys could generate the same hash value mapped to the identical index or bucket.
In response to a hash collision, HashMap constructs a LinkedList of Node objects. This implies that some add, remove, and get operations could take linear time complexities O(n) as these operations involve traversing the LinkedList for the bucket involved in the collision.
This overall can be graphically illustrated as below:
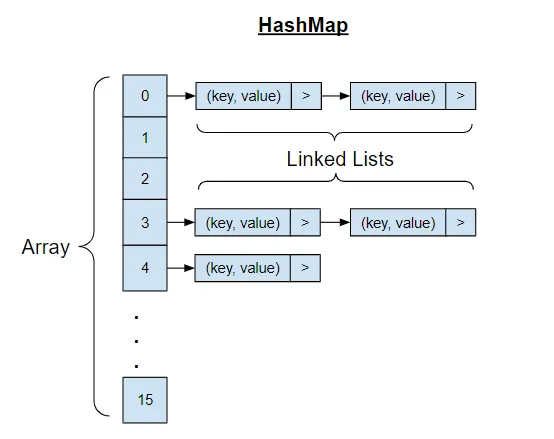
Level Up Coding Available at here
As of Java 8, for the improved performances, HashMap class has introduced an algorithm where it replaces a LinkedList to a balanced tree structure (usually a Red-Black tree) that of the TreeMap class after a certain threshold (TREEIFY_THRESHOLD & MIN_TREEIFY_CAPACITY) is reached. This reduces the time complexities of the basic operations from O(n) to O(log n), thereby enabling more optmised operations.
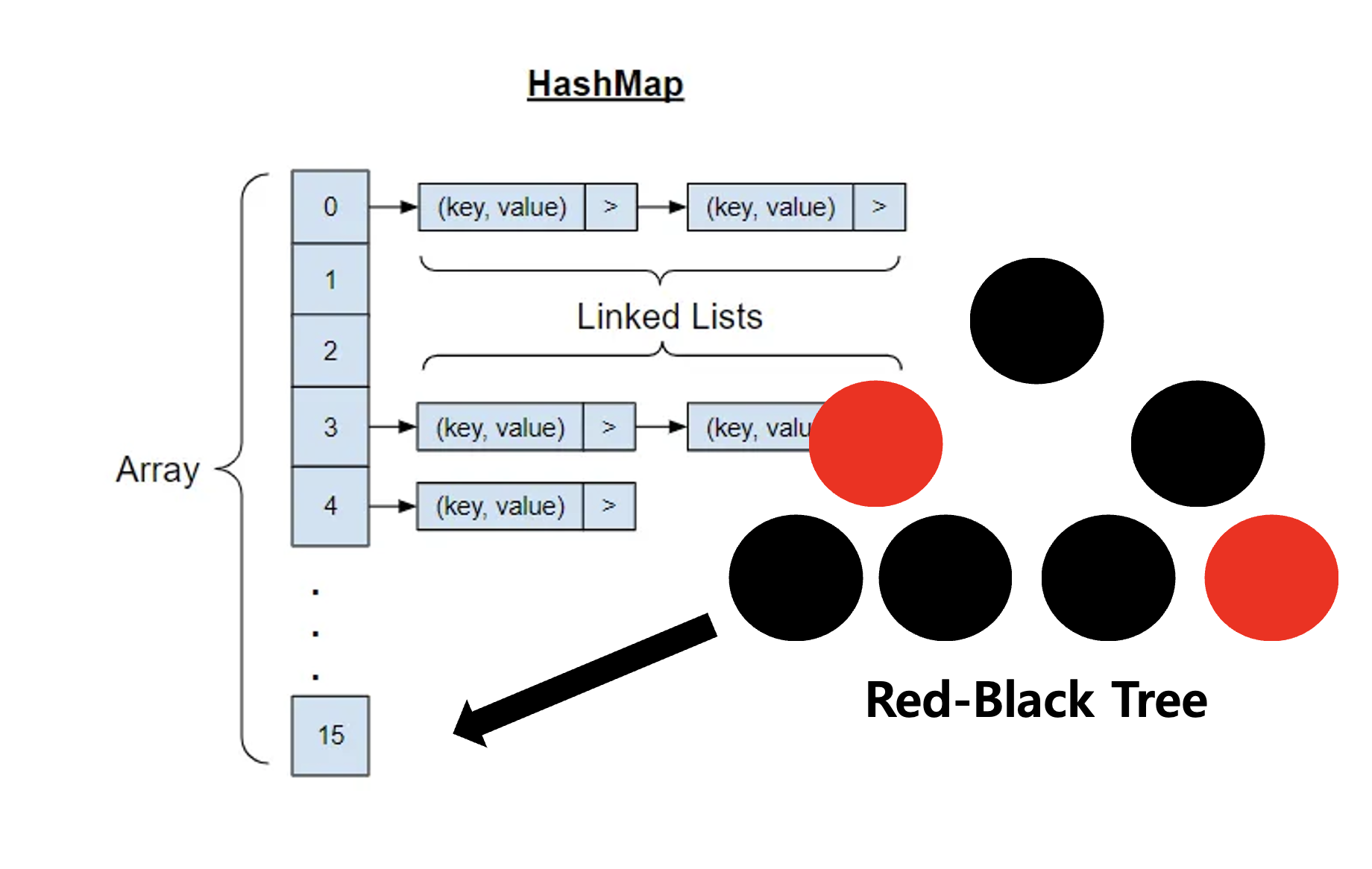
Over the following sections, HashMap's implicit working mechanisms will be discussed with actual code snippets (JDK 17).
🫀🔬 HashMap Class (code)
Almost all basic operations (add, remove, get) in a HashMap roughly involve the following procedures:
-
Calculate
key'shashcodeviahash() method. -
Find a
bucketfollowed byindex = (n - 1) & hash. -
If the bucket is empty:
put- if thebucketat the calculatedindexis null, it means nokey-valuepair has been stored there, and a newentryis inserted directly.get,remove- return null.
-
If the bucket is not empty:
-
TreeNode- runTreeNoderelevantget,add, andremoveoperations. -
LinkedList- runLinkedListrelevantget,add, andremoveoperations. -
return the
Node
-
-
Return
nullif there is no identicalkey.
🧯 Node Class
💡
Node Classis a foundationalclassthat is anentryof theHashMapfollowed by the fact that theHashMap classis implemented asNode objects array,Node<K, V>[].
It is a static nested class declared inside the HashMap and contains key, value, next, and hash instance variables where these variables all happen to be the core components for the HashMap get, put, and remove logics.
Node Class
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
return o instanceof Map.Entry<?, ?> e
&& Objects.equals(key, e.getKey())
&& Objects.equals(value, e.getValue());
}
}🕵️♀️ hashCode() & equals()
💡
hashCode() & equals()are the methods available at theObject classand play a critical role in identifyingkeysinHashMap.
In HashMap for efficient bucket allocation, the hash() method which indirectly replaces hashCode in the Objects class further conducts an unsigned rightward bit shifts after the Object's hashCode() method that returns a heap memory address related unique integer:
[HashMap] hash()
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}[Object] hashCode()
@IntrinsicCandidate
public native int hashCode();and this essentially results impacts the bucket allocation followed by:
[HashMap] getVal()
// codeSnippet
(first = tab[(n - 1) & (hash = hash(key))]) != null)And for every Node Class identification whether the key of a specific Node happens to be identical followed by either the == operator or equals() method from the Object class:
[Object] equals()
public boolean equals(Object obj) {
return (this == obj);
}[HashMap] getVal()
// codeSnippet
((k = first.key) == key || (key != null && key.equals(k)))HashMap Class (JDK 17)
hash(), get(), and getNode() methods.
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
...
...
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*
* @see #put(Object, Object)
*/
public V get(Object key) {
Node<K,V> e;
return (e = getNode(key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods.
*
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n, hash; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & (hash = hash(key))]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
...
...
}📚 References
