🧑🤝🧑 Java Synchronized Collection & Concurrent Collection
🏔️ Overview
By default, almost all Java Collection Classes including ArrayList, HashMap, HashSet, and etc that were thoroughly discussed here are not thread-safe. This implies that implementing the Java Collection Classes under the multi-threading environment could potentially incur a synchronisation problem or deadlock which can negatively affect the performance, reliability, and stability of the programme (for more please read here).
Java, to enable legacy Java Collections Classes to well function in the multi-threading context, overall introduces two approaches:
Collections synchronized_TYPE() methodConcurrent Collection
where these will be discussed in the following sections.
🧑🤝🧑 Java Synchronized Collection
💡
Java Synchronized Collectionsrefers to thethread-safeCollection Classes.
Collections Class contains the static methods where these static methods wrap the original collection classes into the thread-safe Collections Classes and return.
Behind the scenes, the synchronized blocks at the instance level are implemented over the Synchronized Collections particularly on basic data structure operations including add, remove, search, and etc.
Below is the code snippet of the Synchronized Collections Class where a lock object mutex forming a synchorized block can be well observed, thereby achieving the thread-safety.
Collections Class
public class Collections {
// Suppresses default constructor, ensuring non-instantiability.
private Collections() {
}
...
public static <T> Collection<T> synchronizedCollection(Collection<T> c) {
return new SynchronizedCollection<>(c);
}
static <T> Collection<T> synchronizedCollection(Collection<T> c, Object mutex) {
return new SynchronizedCollection<>(c, mutex);
}
...
}
SynchronizedCollection Class
static class SynchronizedCollection<E> implements Collection<E>, Serializable {
@java.io.Serial
private static final long serialVersionUID = 3053995032091335093L;
@SuppressWarnings("serial") // Conditionally serializable
final Collection<E> c; // Backing Collection
@SuppressWarnings("serial") // Conditionally serializable
final Object mutex; // Object on which to synchronize
SynchronizedCollection(Collection<E> c) {
this.c = Objects.requireNonNull(c);
mutex = this;
}
SynchronizedCollection(Collection<E> c, Object mutex) {
this.c = Objects.requireNonNull(c);
this.mutex = Objects.requireNonNull(mutex);
}
....
public int size() {
synchronized (mutex) {return c.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return c.isEmpty();}
}
public boolean contains(Object o) {
synchronized (mutex) {return c.contains(o);}
}
....
public boolean add(E e) {
synchronized (mutex) {return c.add(e);}
}
public boolean remove(Object o) {
synchronized (mutex) {return c.remove(o);}
}
public boolean containsAll(Collection<?> coll) {
synchronized (mutex) {return c.containsAll(coll);}
}
public boolean addAll(Collection<? extends E> coll) {
synchronized (mutex) {return c.addAll(coll);}
}
public boolean removeAll(Collection<?> coll) {
synchronized (mutex) {return c.removeAll(coll);}
}
....Like any other code implementing synchronized blocks, however, Synchronized Collections suffers from the low-performance issues as there could be a considerable number of threads waiting for data structure methods to be unlocked.
🦹♂️ Concurrent Collection
💡
Concurrent Collectionwas initially introduced to address the above performance-related issues with theSynchronized Collections.
Concurrent Collection addresses the synchronisation and its related performance issues via the following approaches:
Segment Lock (Lock Striping)Lock-Free AlgorithmVolatile and Memory Barriers
where these will be discussed in greater detail in the following sub-sections.
⚛🔓 Segment Lock (Lock Striping)
⚛🔓
Segment Lock (Lock Striping)refers to a lock at abucketlevel.
Segment Lock (Lock Striping) follows the functioning principles of the HashMap Class (read here) where an index or a bucket represents the position of the data operations. This essentially led to the idea that using such bucket as a lock would be efficient.
Segment Lock (Lock Striping) was a very primitive form of a ConcurrentHashMap and other Concurrent Collections specifically in a way that until the later lock-free alogrithm was introduced, the core principles of the Segment Lock (Lock Striping) was widely implemented.
Segment Lock (Lock Striping) is still applied to some data operational methods where a bucket lock appears practical.
putVal() method from ConcurrentHashMap Class is a good example where underneath, if specifically, the hash bucket is found to be non-empty, synchronized block at a bucket level then applies to prevent all other threads accessing to the put() method with the identical key or hash value.
[ConcurrentHashMap] putVal() method synchronized block
// given
Node<K,V> f = tabAt(tab, i = (n - 1) & hash));
...
else { // non-empty
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;🚫🔓 Lock-Free Algorithm
🚫🔓
Lock-Free Algorithmrefers to analgorithmwhere athread-safetyis achieved without necessarily implementingsynchronization blockswithlocksat thecodelevel.
Lock-Free Algorithm is referred to as a non-blocking algorithm as well. Lock-Free Algorithm exploits low-level atomic machine instructions, implying that the thread-safety is maintained after the hardware level support.
Particularly, in Java, the lock-free algorithm in the ConcurrentHashMap is implemented via UnSafe Class and UnSafe Class introduces CAS (Compare-And-Swap) Operations for thread-safe updates.
CAS (Compare-And-Swap) compares the stored value in the memory address in interest and modifies (swaps) it if and only if such stored value equals to the value a thread expects from the memory address, implying that there has been no modifications from other threads.
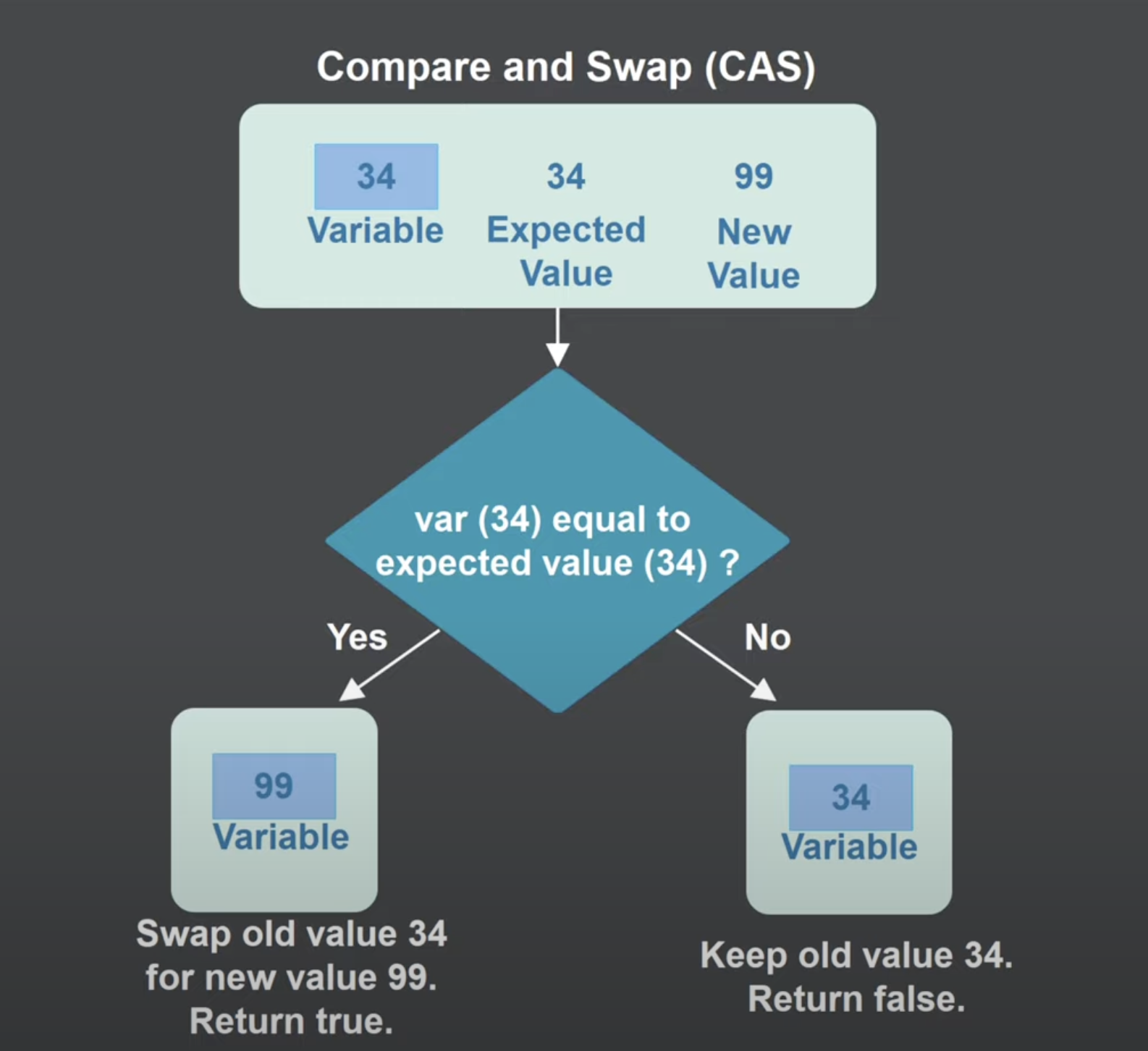
Jenkov Available at here
CAS is applied to put and remove operations in the ConcurrentHashMap Class where these corresponds to the putVal() and replaceNode() methods.
Regarding the get operation, followed by the sequential U.getReferenceAcquire() method call, memory visibility is ensured over every get operation where the U.getReferenceAcquire() method call reflect the most recent updates that occurred before the get operation.
Underneath contains the actual code snippets from the Unsafe Class and ConcurrentHashMap where they are relevant to the above discussion.
CAS is strictly applied at casTabAt() and sequential compareAndSetReference() method call in UnSafe class.
UnSafe Class
public final class Unsafe {
private static native void registerNatives();
static {
registerNatives();
}
private Unsafe() {}
private static final Unsafe theUnsafe = new Unsafe();
...
@IntrinsicCandidate
public native Object getReferenceVolatile(Object o, long offset);
@IntrinsicCandidate
public final Object getReferenceAcquire(Object o, long offset) {
return getReferenceVolatile(o, offset);
}
@IntrinsicCandidate
public final native boolean compareAndSetReference(Object o, long offset,
Object expected,
Object x);
...
}[ConcurrentHashMap] putVal() method
...
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetReference(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
...
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
...
}
...
...
}Overall ConcurrentHashMap Class
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
private static final long serialVersionUID = 7249069246763182397L;
...
private static final Unsafe U = Unsafe.getUnsafe();
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getReferenceAcquire(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetReference(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putReferenceRelease(tab, ((long)i << ASHIFT) + ABASE, v);
}
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
...
}💻 Volatile and Memory Barriers
💻
Volatileis aJavakeyword where it specifically instructs a declaredvariableto be directly read and written to theMain Memory, bypassing theCPU Cache
This mechanism was designed to address data inconsistency issues that arise when different threads have outdated copies of variables in their respective CPU Cache, leading to discrepancies with the Main Memory. By using volatile, Java ensures that all threads access the most up-to-date value directly from Main Memory, preventing caching-related inconsistencies.
In Java ConcurrentCollections, the volatile keyword appears to be frequently used alongside the above other techniques like Lock Striping and Lock-Free Algorithms (CAS) to achieve thread-safety and improve performance.
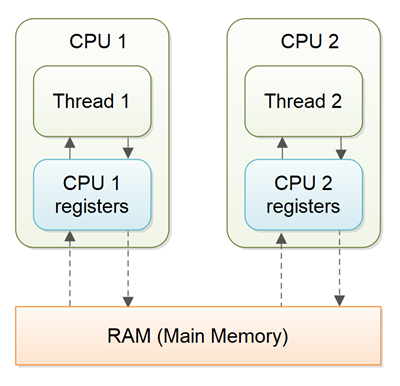
Jenkov (2) Available at here
📚 References
